حل یک تست بدون دسترسی به پاسخ تشریحی ناممکن است. ازاینرو، شما باید به جواب تشریحی تمامی تستهای کنکور برای هر درس دسترسی داشته باشید. این مقاله به بررسی روشهایی میپردازد که میتوانید به پاسخ تشریحی کنکور ارشد فناوری اطلاعات ۱۴۰۰ دسترسی داشته باشید.

روش های دسترسی به پاسخ نامه تشریحی تست های کنکور ارشد فناوری اطلاعات ۱۴۰۰
مؤسسه کنکور کامپیوتر دو روش برای دسترسی به پاسخ نامه تشریحی تست های کنکور ارشد آیتی ۱۴۰۰ برایتان فراهم کرده است:
روش اول: استفاده از پلتفرم آزمون کنکور کامپیوتر
پلتفرم آزمون با گردآوری جواب تشریحی تمامی تستهای کنکور برای تمامی درسها، یک منبع جامع برای دانشجویان است که آنها را از کتابهای درسی بینیاز میکند. همچنین امکان ایجاد آزمون، رقابت با دیگر دانشجویان و… نیز از دیگر مزایای این محیط است. برای کسب اطلاعات بیشتر میتوانید به صفحه پلتفرم آزمون مراجعه کنید.

برای آشنایی شما کیفیت پاسخنامههای تشریحی این پلتفرم، پاسخ تشریحی تستهای کنکور فناوری اطلاعات ۱۴۰۰ برای درسهای ساختمان داده و الگوریتمآموزش ساختمان داده و الگوریتم هر ساختمان داده یک نوع فرمت ذخیرهسازی و مدیریت دادهها در کامپیوتر است، که امکان دسترسی و اصلاح کارآمد آن دادهها را برای یکسری از الگوریتمها و کاربردها فراهم میکند، در این صفحه به بررسی و آموزش ساختمان داده و الگوریتم پرداخته شده است، هوش مصنوعیدرس هوش مصنوعی
هر ساختمان داده یک نوع فرمت ذخیرهسازی و مدیریت دادهها در کامپیوتر است، که امکان دسترسی و اصلاح کارآمد آن دادهها را برای یکسری از الگوریتمها و کاربردها فراهم میکند، در این صفحه به بررسی و آموزش ساختمان داده و الگوریتم پرداخته شده است، هوش مصنوعیدرس هوش مصنوعی این صفحه عالی به معرفی درس هوش مصنوعی از جمله پیش نیازهای درس هوش مصنوعی، سرفصل و منابع درس هوش مصنوعی و فیلمهای آموزشی درس هوش مصنوعی پرداخته شده، پایگاه دادهدرس پایگاه داده ⚡️ پایگاه داده کنکور ارشد کامپیوتر و آی تی
این صفحه عالی به معرفی درس هوش مصنوعی از جمله پیش نیازهای درس هوش مصنوعی، سرفصل و منابع درس هوش مصنوعی و فیلمهای آموزشی درس هوش مصنوعی پرداخته شده، پایگاه دادهدرس پایگاه داده ⚡️ پایگاه داده کنکور ارشد کامپیوتر و آی تی این مقاله عالی توضیح داده که درس پایگاه داده چیست و چه کاربردهایی دارد و منابع و سرفصل های درس پایگاه داده در آزمون کنکور ارشد کامپیوتر و آی تی را بررسی کرده
و ریاضیات گسستهجامع ترین آموزش درس ریاضی گسسته
این مقاله عالی توضیح داده که درس پایگاه داده چیست و چه کاربردهایی دارد و منابع و سرفصل های درس پایگاه داده در آزمون کنکور ارشد کامپیوتر و آی تی را بررسی کرده
و ریاضیات گسستهجامع ترین آموزش درس ریاضی گسسته درس ریاضیات گسسته به معرفی مباحثی نظیر شمارش و احتمال، استدلال و برهان خلف، نظریه اعداد، منطق ریاضی، روابط بازگشتی، روابط و نظریه گراف میپردازد. از آن رو که در عصر کنونی ریاضی گسسته بطور گسترده در رشته کامپیوتر و برنامه نویسی استفاده میشود در این صفحه به معرفی و بررسی درس ریاضی گسسته پرداخته شده است و ... در زیر آورده شده است:
درس ریاضیات گسسته به معرفی مباحثی نظیر شمارش و احتمال، استدلال و برهان خلف، نظریه اعداد، منطق ریاضی، روابط بازگشتی، روابط و نظریه گراف میپردازد. از آن رو که در عصر کنونی ریاضی گسسته بطور گسترده در رشته کامپیوتر و برنامه نویسی استفاده میشود در این صفحه به معرفی و بررسی درس ریاضی گسسته پرداخته شده است و ... در زیر آورده شده است:
پاسخ نامه تشریحی تست های درس پایگاه داده کنکور فناوری اطلاعات ۱۴۰۰
دشوار
در رابطه $R = (A,B,C,D,E,F)$ وابستگیهای زیر برقرار است.
طراحی پایگاه داده
$A \to F$
$B \to C$
$ABC \to E$
در این رابطه چند سوپر کلید وجود دارد؟
1 1
2 3
3 6
4 8
گزینه 4 صحیح است.
D، B، A در سمت راست رابطه وجود ندارد (نمیتوان به آنها رسید) بنابراین قطعاً جزئی از کلید کاندید میباشند.
$\left. \begin{array}{c}
\text{جزء}\mathrm{\ }\text{کلید}\ A\to F \\
\text{جزء}\text{کلید}\ B\to C \end{array}
\right\}\Rightarrow ABC\to E\Rightarrow
$ کلید اصلی است ABD پوشش داده شد، بنابراین A، B، C ،F، E تمام خصیصههای
برای تعداد ابرکلید، خصیصههای کلید اصلی یعنی D, B, A که کلید اصلی است حتماً باید در کلید باشند و دیگر خصیصهها میتوانند باشند یا نباشند پس برای هر خصیصه 2 حالت وجود دارد.
$
ABD\left(2^{\mathrm{\ }\text{تعداد}\mathrm{\ }\text{ستونهای}\mathrm{\ }\text{دیگر}}\right)=2^3=8
$
آسان
کدام مورد در خصوص رابطه درست است؟
طراحی پایگاه داده
1 رابطهای نرمال است که هیچیک از صفات سادهاش چند مقداری نباشند.
2 کلید کاندید رابطه میتواند کاهشپذیر باشد.
3 تاپلهای یک رابطه نظم مکانی دارند.
4 رابطه تاپل تکراری ندارد.
گزینه 4 صحیح است.
گزینه 1: رابطهی نرمال نباید صفات چندمقداری داشته باشد اما لزوماً رابطهای که صفات چندمقداری ندارد نرمال نیست. پس این گزینه غلط است.
گزینه 2: کلید کاندید، کلید کمینه است و با حذف هرجزء آن خاصیت کلیدیاش را از دست میدهد. پس این گزینه غلط است.
توجه: ابرکلید میتواند کاهشپذیر باشد.
گزینه 3: ترتیب و جابجایی تاپلها دررابطه اهمیتی ندارد، این گزینه غلط است.
گزینه 4: صحیح است.
متوسط
فرض کنید در یک جدول $N \ge 3$ خصیصه داریم. در این جدول دو کلید کاندید وجود دارد. یک کلید کاندید دارای دو خصیصه است و یک کلید کاندید دیگر دارای یک خصیصه. بین خصیصههای این دو کلید همپوشانی وجود ندارد. تعداد کل سوپر کلیدها در این جدول کدام است؟
پایگاه داده رابطهای
1 $3 \times 2^{N-2}$
2 $3 \times 2^{N-3}$
3 $5 \times 2^{N-3}$
4 $5 \times 2^{N-2}$
گزینه 3 صحیح است.
باتوجه به شرایط سؤال فرض میکنیم 2 کلید کاندید یکی A و دیگری BC را داریم.
$
\text{تعداد}\mathrm{\ }\text{سوپر کلید}\mathrm{\ }\text{جدول}=\left[\mathrm{A\ }\text{تعداد}\mathrm{\ }\text{سوپر کلید}\mathrm{\ }\text{ترکیب}\mathrm{\ }\text{با}+\mathrm{BC}\mathrm{\ }\text{تعداد}\mathrm{\ }\text{سوپر کلید}\mathrm{\ }\text{ترکیب}\mathrm{\ }\text{با}\right]-\mathrm{ABC}\mathrm{\ }\text{تعداد}\mathrm{\ }\text{سوپر کلید}\mathrm{\ }\text{ترکیب}\mathrm{\ }\text{با}
$
* توجه داشته باشید سوپرکلیدهای ترکیبی با ABC بین سوپرکلیدهای با BC و سوپرکلیدهای با A مشترک است و 2 بار حساب شدهاند بنابراین لازم است یکبار آنها را کم کنیم.
$\mathrm{A}\mathrm{\ }\text{ستون}\mathrm{\ }\text{دیگر}\mathrm{\ }\text{با}\mathrm{\ n-1}\mathrm{\ }\text{ترکیب}\mathrm{\ =\ }{\mathrm{2}}^{\mathrm{n-1}}$
$\mathrm{BC}\mathrm{\ }\text{ستون}\mathrm{\ }\text{دیگر}\mathrm{\ }\text{با}\mathrm{\ n-2}\mathrm{\ }\text{ترکیب}\mathrm{\ =\ }{\mathrm{2}}^{\mathrm{n-2}}
$
$\mathrm{ABC}\mathrm{\ }\text{ستون}\mathrm{\ }\text{دیگر}\mathrm{\ }\text{با}\mathrm{\ n-3}\mathrm{\ }\text{ترکیب}\mathrm{\ =\ }{\mathrm{2}}^{\mathrm{n-3}}
$
در سوپرکلید، کلید کاندید حتماً باید باشند و برای بقیه ستونها 2 حالت وجود دارد. میتوانند باشند یا نباشند بنابراین $
{\mathrm{2}}^{\mathrm{(}\text{تعداد}\mathrm{\ }\text{ستون های}\mathrm{\ }\text{غیر از}\mathrm{\ }\text{کلید}\mathrm{\ }\text{کاندید}\mathrm{)}}
$ حالت برای سوپرکلید داریم.
تعداد سوپر کلید جدول $=\ 2^{n-1}+2^{n-2}-2^{n-3}=2^{n-3}\left(2^2+2-1\right)=5\times2^{n-3}$
دشوار
رابطه $R = (A,B,C,D,E,F)$ را در نظر بگیرید. اگر مجموعه وابستگیهای تابعی F روی R برقرار باشد، کدامیک از تجزیههای زیر دارای گمشدگی (lossless) است؟
طراحی پایگاه داده
$F = \{A \to BC , CD \to E , B \to D , E \to A\}$
1 $R_1(A,B,C),R_2(C,D,E) $
2 $R_1(A,B,C),R_2(A,D,E)$
3 $R_1(E,B,C),R_2(E,D,A)$
4 $R_1(A,B,C),R_2(B,C,D,E)$
در این سؤال خطای تایپی F در متن سؤال وجود دارد. همچنین طراح در متن سؤال دارای گمشدگی و در پرانتز (lossless) عدم گمشدگی را خواسته است و این سؤال حذف شد.
طبق قضیه ریسانن در تجزیه مطلوب برای نداشتن گمشدگی باید خصیصه مشترک در 2 رابطه حداقل در یکی از آنها کلید کاندید باشد.
متوسط
رابطه R=(a,b,c) و عبارات جبر رابطه ای زیر را در نظر بگیرید:
پایگاه داده رابطهای
$Q1:P(S(a,b1,c1),R)$ $Q2:{\underset{b,c}{\prod}} {({\underset{b=c}{\sigma}} \ \ R})$
$P\left(T,S\bowtie R\right)$
${\underset{b1,c}{\prod}} ({\underset{b1=c}{\sigma}} \ \ T)$
1 Q1 و Q2 پاسخهای یکسان تولید میکنند.
2 Q1 و Q2 پاسخهای متفاوت تولید میکنند.
3 پاسخ Q2 زیر مجموعهای از پاسخ Q1 است.
4 پاسخ Q1 زیر مجموعهای از پاسخ Q2 است.
گزینه 3 صحیح است. در پرسوجوی اول یک جدول $R$ را تغییرنام داده به $S$ که ستونهای $a$ همان $a$ ولی $b,c$ را به $b_1,c_1$ تغییرنام داده و در خط بعدی با پیوند داخلی $R\infty S$ یک جدول جدید ایجاد میشود که به $T$ نامگذاری کرد. در پیوند داخلی براساس ستون مشترک $a$ ضرب انجام میشود. ادامه دستور مانند همان $Q_2$ است. دقت کنید پرسوجوی اول ضرب است و ستونهای بیشتری تولید میکند پس $Q_2$ زیرمجموعهی $Q_1$ است.
دشوار
رابطه $R = (A,B,C,D,E,F,G)$ را با وابستگیهای زیر در نظر بگیرید.
طراحی پایگاه داده
$AF \to BE$
$FC \to DE$
$F \to CD$
$D \to E$
$C \to A$
حاصل تجزیه 3NF این رابطه چند رابطه خواهد بود؟
1 1
2 3
3 4
4 5
در کلید نهایی سنجش گزینه 2 و3 را پاسخ اعلام کرد.
F ،G را سمت راست رابطه نداریم پس قطعاً جزئی از کلید میباشند.
$\left. \begin{array}{c}
\mathrm{(}\text{جزئی}\mathrm{\ }از\mathrm{\ }\text{کلید}\ G,\ F) \\
F\to CD \end{array}
\right\}\Rightarrow \left. \begin{array}{c}
\left(F,G,C,D\right) \\
FC\to CD \\
D\to E \\
C\to A \end{array}
\right\}\Rightarrow \left(F,G,C,D,E,A\right)
$
به کل رابطه R رسیدیم پس FG کلید رابطه است.
در سادهسازی رابطه میتوان A و C را از سمت چپ رابطه حذف کرد.
$\left. \begin{array}{c}
F\to CD \\
C\to A \end{array}
\right\}\Rightarrow \left. \begin{array}{c}
\text{رسید}\mathrm{\ }\mathrm{A\ }\text{می توان}\mathrm{\ }\text{به}\mathrm{\ }\mathrm{F\ }از \\
AF\to BE \end{array}
\right\}{{\stackrel{\text{می توان}\mathrm{\ }\text{نوشت}}{\longrightarrow}F\to DE\Rightarrow \left\{ \begin{array}{c}
F\to D \\
F\to E \end{array}
\right.}}
$
$\left. \begin{array}{c}
FC\to DE \\
F\to CD \end{array}
\right\}\Rightarrow \text{حذف}\mathrm{\ }\text{کرد}\ FC\ را\mathrm{\ }در\ C\mathrm{\ }\text{طبق}\mathrm{\ }\text{بالا}\mathrm{\ }\text{می توان}\Rightarrow F\to DE\Rightarrow \left\{ \begin{array}{c}
F\to D \\
F\to E \end{array}
\right.
$
بعد از ساده سازی داریم: $\begin{array}{c}
F\to B \\
F\to E \\
F\to C \\
F\to D \\
D\to E \\
C\to A \end{array}
$
در این رابطه (B, E, C, D) غیرکلید $\rightarrow$ جزء کلید (F) داریم. پس رابطه نرمال سطح دو 2NF نیست. کافی است G را جدا کنیم تا F بهتنهایی کلید باشد و دیگر جزئی از کلید نباشد.
داریم $R_2\left(F,G\right)$ و $R_1\left(A,B,C,D,E,F\right)$، $R_2$ نرمال 2NF و 3NF است ولی در $R_1$، [$\left(E,A\right)$ غیرکلید $\rightarrow$ غیرکلید $\left(C,D\right)$]داریم. پس باید به 3 رابطهای $R_{11}\left(D,E\right)$، $R_{12}\left(A,C\right)$، $R_{13}\left(F,B,C,D\right)$ تجزیه کنیم تا 3NF شود. حاصل تجزیه 4 رابطه است.
$R\left(A,B,C,D,E,F,G\right)\left\{ \begin{array}{c}
R_1\left(A,B,C,D,E\right)\left\{ \begin{array}{c}
R_{11}\left(D,E\right)\ \ \ \ \ \ \ \ \ \ \\
R_{12}\left(C,A\right)\ \ \ \ \ \ \ \ \ \ \\
R_{13}\left(F,B,C,D\right) \end{array}
\right. \\
R_2\left(F,G\right)\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \end{array}
\right.
$
پاسخ نامه تشریحی تست های درس هوش مصنوعی کنکور فناوری اطلاعات ۱۴۰۰
دشوار
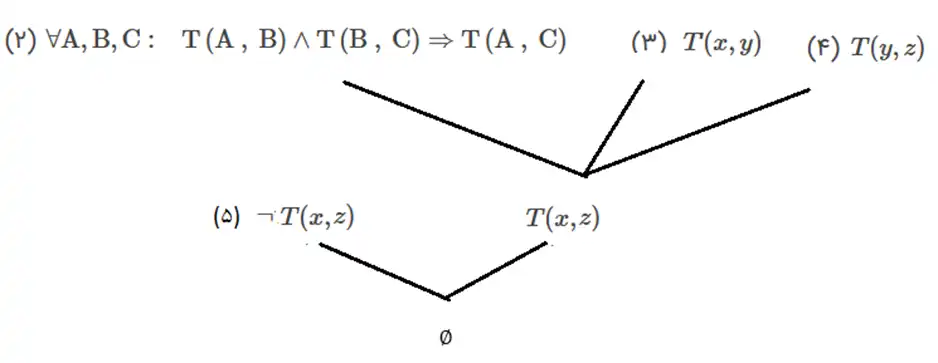
فرض کنید که پایگاه دانشی به فرم زیر در دسترس است.
منطق مرتبه اول
| $\mathrm{\ \ }\mathrm{\forall }\mathrm{A,B:\ \ \ T}\left(\mathrm{A\ ,\ B}\right)\Rightarrow \neg \mathrm{T}\left(\mathrm{B\ ,\ A}\right)$ |
(1) |
| $\mathrm{\forall }\mathrm{A,B,C:\ \ \ T}\left(\mathrm{A\ ,\ B}\right)\wedge \mathrm{T}\left(\mathrm{B\ ,\ C}\right)\Rightarrow \mathrm{T}\left(\mathrm{A\ ,\ C}\right)$ |
(2) |
| $T(x , y)$ |
(3) |
| $T( y , z)$ |
(4) |
حال فرض کنید میخواهیم پرسش $(5)\ \alpha = T(x,z)$ را با استفاده از روش تجزیه، استنتاج کنیم. کدام ترتیب بر روی گزارههای پایگاه دانش برای این استنتاج میتواند استفاده شود؟ (از راست به چپ)
1 (3 و 1) - (3 و 2) - (4 و 1)
2 (3 و 2) - (4 و 2) - (5 و 2)
3 (3 و 1) - (4 و 1) - (3 و 2)
4 (3 و 2) - (4 و 2) - (5 و 1)
گزینه صحیح 2 است.
برای استنتاج عبارت داده شده ابتدا نقیض آن را به پایگاه دانش اضافه کرده و سعی میکنیم به تناقض برسیم. درخت زیر مراحل استنتاج متغیر خواسته شده در صورت سوال را نشان میدهد که با توجه به شکل زیر و اینکه از قانون شماره یک در استنتاج استفاده نشده است میتوان گفت بهترین گزینه برای این سوال گزینه شماره ۲ است.
دشوار
دنیای مکعبها (شامل سه مکعب $A$، $B$ و $C$) را درنظر بگیرید. $P(x , y)$ نشان میدهد که مکعب $x$ جزء یکی از مکعبهای بالای مکعب $y$ است، از بین جملات زیر کدام گزینه فقط شامل جملات درست است؟
منطق مرتبه اول
$α\mathrm{:\ }\mathrm{\forall }\mathrm{x\ }\mathrm{\forall }\mathrm{y\ P}\left(\mathrm{x\ ,\ y}\right)\mathrm{\Rightarrow }\mathrm{\neg P}\left(\mathrm{y\ ,\ x}\right)\mathrm{\ }$
$β\mathrm{:\ }\mathrm{\forall }\mathrm{x\ }\mathrm{\forall }\mathrm{y\ }\mathrm{\forall }\mathrm{z\ P}\left(\mathrm{x\ ,\ y}\right)\mathrm{\wedge }\mathrm{\ P}\left(\mathrm{y\ ,\ z}\right)\mathrm{\Rightarrow }\mathrm{\ P}\left(\mathrm{x\ ,\ z}\right)$
$γ\mathrm{:\ }\mathrm{\exists }\mathrm{x\ }\mathrm{\forall }\mathrm{y\ \neg P}\left(\mathrm{y\ ,\ x}\right)$
$δ\mathrm{:\ }\mathrm{\forall }\mathrm{x\ }\mathrm{\exists }\mathrm{y\ P}\left(\mathrm{y\ ,\ x}\right)$
1 α , β , γ
2 α , β , δ
3 α , γ , δ
4 β , γ , δ
گزینه 1 صحیح است.
$\alpha$ : این عبارت بیانگر این است که اگر به ازای هر مکعب x و x ، y یکی از مکعبهای بالایی y باشد آنگاه y نمیتواند جز مکعبهایی بالایی x باشد چون میدانیم x بالای y است و این عبارت درست است.
$\beta$ : این عبارت میگوید به ازای هر سه مکعب اگر x بالای y باشد و y هم بالای z باشد میتوان گفت x بالای z نیز هست که عبارتی درست است.
$\gamma$ : این عبارت میگوید مکعبی وجود دارد که هیچ مکعب دیگری روی آن نیست و این عبارت نیز درست است چرا که همواره این شرط برای بالاترین مکعب برقرار است.
$\delta$ : این عبارت میگوید برای همه مکعبها یک مکعب وجود دارد که روی آن قرار گرفته است و این عبارت نادرست است چرا که برای بالاترین مکعب این شرط برقرار نیست.
دشوار
کدام گزاره درست است؟
منطق گزارهای
1 $\mathrm{F\ \models\ \alpha}\ $ یک جمله همیشه درست (tautology) است.
2 $ \mathrm{KB\ \models\ \alpha} $ آنگاه $ \mathrm{\lnot KB\ \vee\ \alpha}$ یک جمله همیشه نادرست است.
3 اگر $KB=\alpha$ آنگاه $\mathrm{KB\ \land\ \lnot\alpha}$ ارضاپذیر (satisfiable) است.
4 فرض کنید هرگاه برای یک مدل $m$، جمله $α$ درست برای آن مدل جمله $β$ هم درست است، در این صورت میتوان نتیجه گرفت $\mathrm{\alpha\ \equiv\ \beta}\ $ .
گزینه 1 صحیح است.
گزینه ۱ : این گزینه درست است زیرا در صورتی که سمت چپ یک استنتاج False باشد مستقل از اینکه سمت راست آن چه ارزشی دارد میتوان ارزش کل گزاره را درست در نظر گرفت در نتیجه این گزاره همواره درست است.
گزینه ۲ : در صورتی که یک جمله برقرار باشد نقیض آن همواره نادرست است و نقیض عبارت $KB\ \models \ \alpha $ برابر $KB \ \wedge \ \neg \alpha$ میباشد نه $\neg KB\ \vee \ \ \alpha $.
گزینه ۳ : از آن جایی که گفته شده است $KB=\alpha$ است میتوان عبارت $KB \ \wedge \ \neg \alpha$ را به صورت $\alpha \ \wedge \ \neg \alpha$ نوشت که میدانیم عبارتی ارضاناپذیر است.
گزینه ۴ : در این صورت میتوان گفت $M(\alpha) \subseteq M(\beta)$ یا همان $\alpha \models \beta $ برقرار است.
دشوار
مسئله CSP شامل سه متغیر بولین A, B, C و عبارتهای زیر که نشاندهندهی محدودیتها روی مقدار این متغیرهاست را درنظر بگیرید:
مسائل ارضای محدودیت
$\mathrm{A\ }\mathrm{\vee }\mathrm{\ B}$
$\mathrm{A\ }\mathrm{\vee }\mathrm{\ C}$
$\mathrm{\neg }\mathrm{B}\mathrm{\ }\mathrm{\vee }\mathrm{\ \neg C}$
$\mathrm{B}\mathrm{\ }\mathrm{\vee }\mathrm{\ \neg C}$
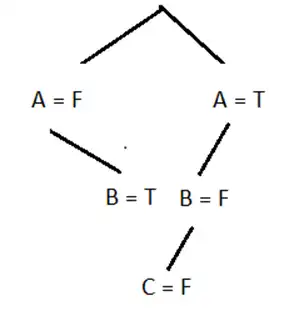
فرض کنید هنگام جستجو در مقداردهیها، ترتیب متغیرها به ترتیب الفبایی و ترتیب مقادیر بهصورت اول F و بعد T درنظر گرفته شود. ترتیب مقداردهیهایی که (از چپ به راست) به متغیرها توسط الگوریتم DFS با عقبگرد (backtrack) و استفاده از forward checking برای رسیدن به اولین جواب صورت میگیرد، کدام است؟
1 A =T, B = F, C = F
2 A = F, B = T, A = T, B = T, C = F
3 A = F, B = T, A = T, B = F, C = F
4 A = F, B = F, A = F, B = T, C = F, A = F, B = T, C = T, A = T, B = F, C = F
گزینه 3 صحیح است.
با توجه به ترتیب انتخاب متغیرها و ترتیب مقادیر بهصورت اول F و بعد T ، درخت حاصل از اجرای این الگوریتم با توجه به محدودیتهای در نظر گرفته شده در ادامه نشان داده شده است.
محدودیتها :
1- A ∨ B
2- A ∨ C
3- ¬B ∨ ¬C
4- B ∨ ¬C
در این روش ابتدا متغیر A را انتخاب کرده و مقدار آن را به F تنظیم میکنیم در نتیجه با توجه به محدودیت شماره یک مقدار F از دامنه B و C حذف میشود. پس از آن متغیر B انتخاب میشود و مقدار آن را T در نظر میگیریم اما در این حالت با توجه به محدویتهای شماره ۳ و ۴ دامنه مربوط به متغیر C تهی میشود و مجبور میشویم که عقبگرد انجام دهیم. در نتیجه به متغیر A که میتواند در این مرحله مقدار T بگیرد باز میگردیم. با این مقداردهی هیچ تغییر در دامنه متغیرها ایجاد نمیشود و در مرحله بعد متغیر B را انتخاب کرده و مقدار F را برای آن تنظیم میکنیم. در این حالت مقدار T از دامنه مقادیر C حذف میشود ولی همچنان مقدار F برای آن معتبر است و پس از آن متغیر C انتخاب شده و مقدار آن را F در نظر گرفته و به پاسخ میرسیم.
دشوار
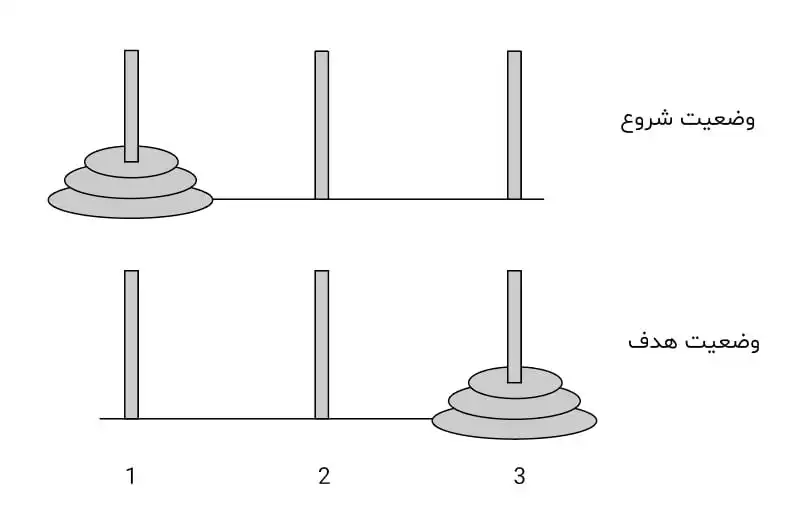
مسئله برج هانوی را درنظر بگیرید که در آن قرار است دیسکهایی که در شروع به ترتیب بزرگ به کوچک روی میلهی شماره 1 قرار گرفتهاند، در انتها به همین ترتیب روی میلهی شماره 3 قرار گرفته باشند. کنشها در این محیط میتوانند دیسکی را که روی آن چیزی قرار نگرفته (یا به عبارت دیگر بالاترین دیسک روی یک میله است) را به یک میله خالی یا روی یک دیسک بزرگتر منتقل کند. فرض کنید دیسک با کوچکترین اندازه 1 واحد، دیسک متوسط 2 واحد و دیسک بزرگ 3 واحد وزن داشته باشد و هزینهی انتقال هر واحد وزن بین دو میله با فاصله 1 برابر 1 واحد ولی بین دو میله با فاصله 2 به واسطه نداشتن استراحت برابر 3 واحد باشد. اگر هزینهی کلی انتقال هر دیسک ضرب تعداد واحد وزن آن در هزینه جابهجایی هر واحد وزن باشد، کدام گزینه میزان هزینهی کلی (یا مقدار تابع g(n)) برای 3 گره اولی که توسط الگوریتم UCS با فرض جستجوی گرافی گسترش مییابند (یا به عبارت دیگر از صف برداشته میشوند) را به درستی نشان میدهد و همچنین از بین توابع ابتکاری (heuristic) زیر کدام موارد قابل قبول (admissible) هستند؟ (قاعدتاً در تمام فضای جستجو)
الگوریتم های جستجوی آگاهانه
\( {h}_1 \) : سه برابر جمع وزن دیسکهای روی میلهی اول
\( {h}_2 \) : جمع وزن دیسکهای روی میلهی دوم
1 هزینهها در UCS: اولین گره 1، دومین 2 و سومین 3
توابع admissible: فقط \( {h}_2 \)
2 هزینهها در UCS: اولین گره 1، دومین 2 و سومین 3
توابع admissible: \( {h}_2 \) و \( {h}_1 \)
3 هزینهها در UCS: اولین گره 1، دومین 2 و سومین 4
توابع admissible: فقط \( {h}_2 \)
4 هزینهها در UCS: اولین گره 1، دومین 2 و سومین 4
توابع admissible: \( {h}_2 \) و \( {h}_1 \)
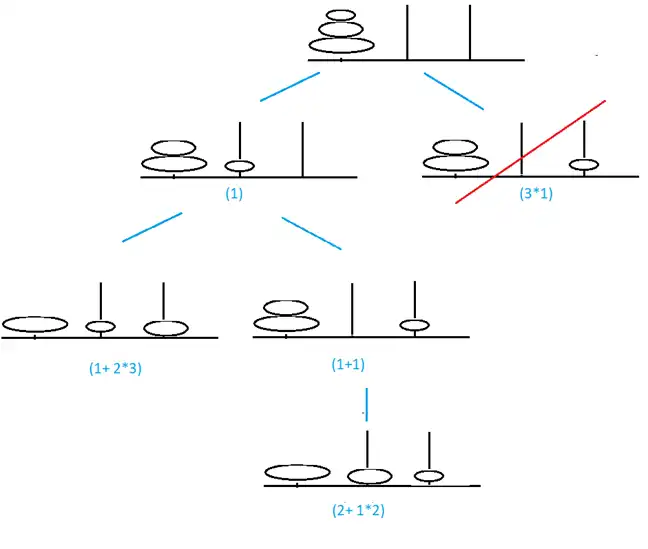
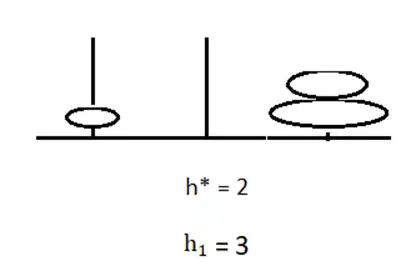
گزینه 3 صحیح است.
در ابتدا الگوریتم UCS را در مسئله داده شده اجرا میکنیم. در مرحله ابتدایی این الگوریتم دو انتخاب دارد که در شکل زیر نشان داده شده است و یکی هزینه ۳ و دیگری هزینه ۱ دارد. با توجه به این روش گره با هزینه ۱ انتخاب میشود. پس از آن با توجه به اینکه در صورت سوال گفته شده است که روش جستجو گرافی است از این گره به دو گره دیگر میتوان رفت که در شکل زیر مشخص شدهاند و یکی از این گرهها مشابه یکی از گرهها قبلی موجود در صف است و از آنجایی که g(n) کمتری دارد باعث بروزرسانی گره قبلی میشود (به این معنی که گره قبلی حذف و گره جدید جایگزین آن میشود). با توجه به شکل گره سوم برای بسط با توجه به مقادیر g(n) که در کنار هر شکل مشخص شده است، گره با g(n) برابر ۴ میباشد و تا به اینجا یکی از گزینههای ۳ یا ۴ درست هستند.
در مورد قابل قبول بودن توابع ابتکاری داده شده نیز تابع $h_1$ با توجه به مثال زیر قابل قبول نیست چرا که در این مثال میتوان طی دو مرحله با انتقال دیسک با وزن یک به میله دوم و سپس میله سوم با هزینه ۲ به هدف رسید در صورتی که مقدار هیوریستیک در این حالت برابر ۳ میباشد.
اما تابع $h_2$ قابل قبول است چرا که برای انتقال دیسکهای روی میله دوم و رسیدن به هدف باید هر کدام از آنها را حداقل یکبار و به میله با حداقل یک فاصله انتقال دهیم پس در هر صورت اندازه جمع وزن دیسکهای روی میله دوم از هزینه واقعی رسیدن به هدف کمتر مساوی میباشد.
متوسط
فرض کنید میخواهیم در یک مسئله جستجو از روش \( {A}^* \) استفاده کنیم. در این مسئله دو تابع مکاشفه قابل قبول \( {h}_1 \) و \( {h}_2 \) تعریف شدهاند. کدام یک از روشهای زیر حالت بهینه هدف را پیدا میکند؟
الگوریتم های جستجوی آگاهانه
1 جستجوی مبتنی بر گراف \( {A}^* \) با تابع مکاشفه \(\mathrm{h\ =\ }{\mathrm{h}}_{\mathrm{1}}\mathrm{+}{\mathrm{h}}_{\mathrm{2}}\)
2 جستجوی مبتنی بر درخت \( {A}^* \) با تابع مکاشفه \(\mathrm{h\ =\ }{\mathrm{h}}_{\mathrm{1}}{{}^{*\ }_{\ }{\mathrm{h}}}_{\mathrm{2}}\)
3 جستجوی مبتنی بر گراف \( {A}^* \) با تابع مکاشفه \(\mathrm{h\ =\ min}\left({\mathrm{h}}_{\mathrm{1}},{\mathrm{h}}_{\mathrm{2}}\right)\)
4 جستجوی مبتنی بر درخت \( {A}^* \) با تابع مکاشفه \(\mathrm{h\ =}{\left({\mathrm{2}\mathrm{h}}_{\mathrm{1}}+{\mathrm{h}}_{\mathrm{2}}\right)}/{\mathrm{3}}\)
گزینه 4 صحیح است.
ابتدا دو نکته را یادآوری میکنیم :
۱- در روش جستجوی A* :
- در حالت جستجوی درختی در صورتی که تابع هیوریستیک قابل قبول باشد، الگوریتم A* پاسخ بهینه را تضمین میکند .
- در حالت جستجوی گرافی در صورتی که تابع هیوریستیک سازگار باشد، الگوریتم A* پاسخ بهینه را تضمین میکند.
۲- در صورتی که چند تابع هیوریستیک قابل قبول داشته باشیم، میانگین حسابی و هندسی ،max و min آنها نیز قابل قبول هستند چرا که در این توابع نیز هیچگاه مقدار h(n) تخمین زده شده برای یک گره بیشتر از مقدار اصلی هزینه مسیر آن گره تا گره هدف نمیشود.
گزینه ۱ : مجموع دو تابع هیوریستک قابل قبول لزوما یک تابع هیوریستیک قابل قبول نیست در نتیجه در این حالت تضمینی برای یافتن حالت بهینه نداریم.
گزینه ۲ : حاصلضرب دو تابع هیوریستک قابل قبول لزوما یک تابع هیوریستیک قابل قبول نیست در نتیجه در این حالت تضمینی برای یافتن حالت بهینه نداریم.
گزینه ۳ : min دو تابع هیوریسیتک قابل قبول، باز هم تابعی قابل قبول است اما در روش A* برای اینکه بخواهیم الگوریتم پاسخ بهینه را تضمین کند در حالتی که تابع هیوریستیک قابل قبول است نیاز به جستجو درختی داریم نه گرافی.
گزینه ۴ : تابع داده شده در این گزینه قابل قبول است و اثبات آن در ادامه آمده است از طرفی طبق نکته اول جستجوی اشاره شده در این گزینه درختی است پس میتوان تضمین کرد که پاسخ بهینه در این شرایط یافت میشود.
$\forall n\ \ \ h_1(n)\ \le \ h^*(n)\ \ \ \ \ \ $
$\forall n\ \ \ h_2(n)\ \le \ h^*(n)$
$\forall n\ h_2\left(n\right)+2h_1\left(n\right)\le 3h^*\left(n\right)$
$\forall n\frac{\ h_2\left(n\right)+2h_1\left(n\right)}{3}\le h^*\left(n\right)\ \ \ \ \ \ \ $
آسان
کدام یک از موارد زیر در خصوص الگوریتم عمیقسازی تکرارشونده (iterative deepening) درست است؟
الگوریتم های جستجوی ناآگاهانه
1 همه حالات دیده شده در درخت جستجو در آخرین تکرار (iteration)، به تعداد مساوی در طول اجرا ملاقات میشوند.
2 با فرض ثابت بودن ضریب شاخه (branching factor)، مرتبه زمانی الگوریتم از جستجوی سطح اول (BFS) بیشتر است.
3 میزان حافظه مورد استفاده توسط الگوریتم، نمایی است.
4 هیچکدام
گزینه 4 صحیح است.
یادآوری :
الگوریتم DFS یک الگوریتم جستجو ناآگاهانه است که ممکن است در عمق نامتناهی بیفتد به همین دلیل در یک نوع آن که DLS (Depth Limited Search) نام دارد این الگوریتم را فقط تا عمق معینی اجرا میکنیم اما بسته به اینکه هدف در عمق بیشتر یا کمتر از عمق تعیین شده باشد ممکن است نتوانیم به هدف برسیم و به طور کلی به دلیل اینکه عمق جواب را نمیدانیم، تعیین پارامتر عمق برای این روش سخت است. روش دیگری که برای رفع این مشکل ارائه شد IDS (Iterative Deepening Search) است. در این الگوریتم ، در یک حلقه عمق را از صفر تا بینهایت یکی یکی زیاد میکنیم و در هر مرحله الگوریتم DLS را با آن اجرا می کنیم. کد زیر پیادهسازی این الگوریتم را نشان میدهد.
function ITERATIVE-DEEPENING-SEARCH(problem) returns a solution, or failure
for depth = 0 to ∞ do
result ← DEPTH-LIMITED-SEARCH(problem, depth)
if result ≠ cutoff then return result
گزینه ۱ : نادرست است چرا که مثلا ریشه در هر تکرار ملاقات میشود اما گره هدف فقط در تکرار آخر ملاقات میشود.
گزینه ۲ : مرتبه زمانی هر دو الگوریتم $O(b^d)$ میباشد اما تعداد گرههایی که در روش IDS تولید میشود بیشتر است.
گزینه ۳ : میزان حافظه مورد استفاده این روش از مرتبه O(bd) است و در صورتی که از روش عقبگرد استفاده شود به O(d) قابل کاهش است.
گزینه ۴ : پاسخ این گزینه است.
پاسخ نامه تشریحی تست های درس شبکه های کامپیوتری کنکور فناوری اطلاعات ۱۴۰۰
آسان
روتری را در نظر بگیرید که سه زیر شبکه X و Y و Z را به هم متصل میکند. فرض کنید که همه واسطها در این سه زیر شبکه باید پیشوند 0/21، 80، 2، 13 داشته باشند. فرض کنید زیر شبکه X باید از 1000 واسط پشتیبانی کند و هر کدام از زیر شبکههای Yو Z باید 500 واسط را آدرسدهی کنند. کدام مجموعه از آدرسهای زیر این شرایط را برآورده میسازد؟
لایه شبکه
1 X :13.2.88.0/23 ، Y :13.2.84.0/22 ، Z :13.2.80.0/22
2 X :13.2 ،84.0/23 ، Y :13.2.80.0/23 ، Z :13.2.82.0/23
3 X :13.2.80.0/22 ، Y :13.2.82.0/23 ، Z :13.2.84.0/23
4 X :13.2.80.0/22 ، Y :13.2.84.0/23 ، Z :13.2.86.0/23
IP های در دسترس در این شبکه بهصورت زیر است: (X به معنای این است که این قسمت فیکس نشده و میتواند صفر یا یک باشد):
IP: 13.2.01010XXX.XXXXXXXX اولیه موجود
ما در اینجا 11 جای خالی داریم که میتوان$2^{11}$ یا 2048 آدرس تولید کرد. ابتدا چون برای زیرشبکه X، 1000 IP میخواهیم 1024 تای آن را به X اختصاص میدهیم. سپس از آدرسهای باقیمانده، 512 تا را به زیرشبکه Z، Y میدهیم:
13.2.80.0/22 یا : 13.2.010100XX.XXXXXXXX زیرشبکه X
13.2.84.0/23 یا : 13.2.0101010X.XXXXXXXX زیرشبکه Y
13.2.86.0/23 یا : 13.2.0101011X.XXXXXXXX زیرشبکه Z
متوسط
یک کنترل کننده SDN با استفاده از APIهای شمالی و جنوبی اقدام به تبادل پیام میکند. کنترلر به API جنوبی چه پیامهایی میفرستد و مقصد این پیامها کدامند؟ کنترلر از طریق API شمالی چه پیامهایی را و از کجا دریافت میکند؟
لایه شبکه
1 مقصد پیامها به API جنوبی سوییچها هستند و برخی از این پیامها عبارتند از :
Modify-state,Read-state,Send-packet
کنترلر از طریق API شمالی پیامهایی را از برنامههای کنترل کننده شبکه دریافت میکند. برخی از این پیامها عبارتند از:
Network state messages, Flow tables
2 مقصد پیامها به API جنوبی سرور SDN است و برخی از این پیامها عبارتند از:
Error report, Send Table, Controller configuration
کنترلر از طریق API شمالی پیامهایی را از سوییچهای بستهای دریافت میکند. برخی از این پیامها عبارتند از:
Buffer states, Forwarding tables
3 مقصد پیامها به API جنوبی سرور OpenFlow است و برخی از این پیامها عبارتند از:
Server configuration, Flow control, Target reached
کنترلر از طریق API شمالی پیامهایی را از گراف شبکه دریافت میکند برخی از این پیامها عبارتند از:
Iink costs, Link failure report
4 مقصد پیامها به API جنوبی اطلاعات میزبانها است. و برخی از این پیامها عبارتند از:
Unreachable destination, Congestion notification, Bottleneck messages
کنترلر از طریق API شمالی پیامهایی را از برنامههای مدیریت شبکه دریافت میکند. برخی از این پیامها عبارتند از:
Traffic statistics. SNMP up/down messages
بهطور کلی در SDN، پیامها از طریق API جنوبی با سوئیچها در ارتباطاند و از طریق API شمالی با برنامهها
آسان
برای این که یک صفحه وب شامل یک فایل GIF را از یک سرور HTTP1.0 که آدرس IP آن را نمیدانیم بازیابی کنیم، علاوه بر HTTP از کدام پروتکلهای لایه کاربرد و انتقال باید استفاده کنیم؟ (فایل GIF روی همان سرور وب قرار دارد.)
لایه کاربرد
1 لایه کاربرد: IGP- لایه انتقال : RSVP و TCP
2 لایه کاربرد: DNS- لایه انتقال : UDP و TCP
3 لایه کاربرد: DASII- لایه انتقال : TCP و UDP و IGMP
4 لایه کاربرد: SNMP- لایه انتقال : UDP و TCP و RTP
ما میدانیم که برای اینکه اسم یک سرور را به آدرس یا یک IP مشخص ترجمه کنیم، از DNS استفاده میکنیم که به ما بهازای هرسرور، یک IP یکتا میدهد. زمانی که ما IP سروری را نداریم مشخص است که باید از پروتکل DNS استفاده کنیم.
متوسط
توپولوژی زیر را در نظر بگیرید که در آن هاست S قصد دارد یک فایل بسیار بزرگ چند گیگابایتی را برای R بفرستد. تاخیر انتشار و ارسال لینکها بر روی آنها نوشته شده است. فرستنده از پروتکل پنجره لغزان با اندازه پنجره 10 بسته استفاده میکند. فرض کنید که حداکثر اندازه صف ارسال در لینک متصل از سوئیچ به R برابر 30 بسته است. اندازه هر بسته داده 1000 بایت و اندازه هر بسته ack برابر 40 بایت است. فرض کنید که هیچ جریان ترافیکی دیگری در شبکه وجود ندارد. نرخ تقریبی ارسال از S به R کدام است؟ در شکل B بیانگر بایت است.
اصول و مقدمات شبکههای کامپیوتری
1 نرخ بین 225 تا 250 بسته بر ثانیه است.
2 نرخ بین 450 تا 500 بسته بر ثانیه است
3 نرخ بین 900 تا 1000 بسته بر ثانیه است.
4 نرخ تقریبی به مقدار timeout فرستنده وابسته است.
در اینگونه سؤالات باید ببینیم که از زمانیکه بسته اول ارسال میشود تا زمانیکه اولین ACK برمیگردد، ما چند بسته میتوانیم ارسال کنیم و بعد با یک تناسب ساده پاسخرا بهدست آوریم. ابتدا زمان ارسال هربسته و ACK را طبق دادههای مسئله حساب میکنیم:
$\frac {1000\times 8}{10^8 \times 8}=10^{-5}=0.01ms$ = زمان ارسال هربسته از S به روتر
$\frac {1000\times 8}{10^6 \times 8}=1ms$ = زمان ارسال هربسته از روتر به R
توجه: چون حجم بستههای ACK کم است و سوال از ما پاسخ تقریبی خواسته، میتوان از زمان ارسال ACK صرف نظر کرد. حال باید حساب کنیم از زمانی که بسته اول شروع به ارسال میکند تا زمانی که اولین ACK به ما برمیگردد چقدر طول میکشد:
تاخیر انتشار از R به روتر مربوط به ACK + تأخیر انتشار از روتر به R + زمان ارسال بسته اول از روتر به R + زمان
ارسال بسته اول از S به روتر = زمان مورد نظر
| زمان |
بسته |
تناسب
$\to$
|
| 21.01ms |
10 |
| ms1000 |
x |
=0.01+1+10+10=21.01ms
$\to x=\frac {10\times 100}{21.01}\approx476$
نکته قابل توجه در حل این سوال: ما از زمان ارسال بستههای ACK صرف نظر کردیم، همچنین طبق صورت مسئله تأخیر انتشار در لینکهای S به روتر و برعکس را صفر در نظر گرفتیم. همچنین طبق گفته صورت سوال پنجره ارسال 10 بسته گنجایش دارد و اگر محدودیت پنجره ارسال ذکر نمیشد، باید حساب میکردیم با توجه به زمان ارسال بستهها روی لینک از S به روتر و زمانی که طول میکشد تا اولین ACK به S برسد، ما چند بسته میتوانستیم ارسال کنیم که مطابق محاسبات روبرو است: بسته $\frac {21.01}{0.01}=2101$
همانطور که محاسبه شد، اگر محدودیت پنجره امسال وجود نداشت، تعداد بستههایی که در تناسب برای محاسبه جواب باید استفاده میشد، به جای 10 عدد، 2101 عدد میبود. همچنین اگر در مسئلهای این عدد از محدودیت پنجره ارسال کمتر بود، باید این عدد را بهعنوان بستههای ارسالی در نظر گرفت. بهطور کلی برای جایگذاری تعداد بستهها در تناسب ذکر شد، ما باید مینیمم ظرفیت پنجره و تعداد بستههای قابل ارسال در مدت زمان فرستادن اولین بسته تا رسیدن اولین ACK قرار داده شود.
آسان
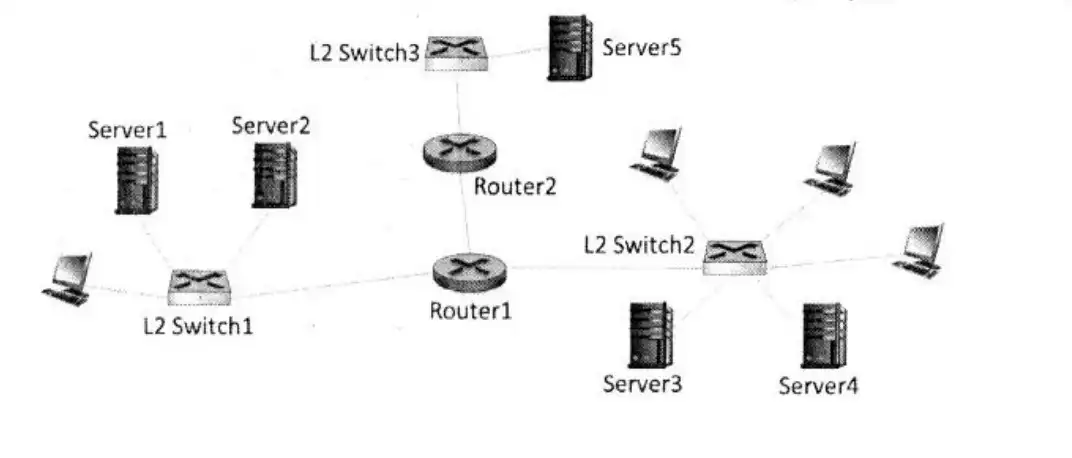
در شبکه زیر چند IP subnet وجود دارد؟
لایه شبکه
1 2
2 3
3 4
4 5
زیرشبکههای موجود به شرح روبهرو هستند: 1- زیرشبکه بین روتر 1 و 2 2- زیرشبکه سمت راست روتر 1 3- زیرشبکه سمت چپ روتر 1 4- زیرشبکه متصل به روتر 2
نکته: باید توجه داشت که سوئیچها سطح دو هستند و با IP کاری ندارند.
آسان
چند مورد از عبارات زیر در مورد فاز AIMD در پروتکل TCP درست هستند؟
لایه انتقال
- از کمک ادوات داخل شبکه برای کنترل ازدحام بهره میبرد.
- وقتی Timeout رخ دهد اندازه پنجره ازدحام را برابر 1 میکند.
- تاخیر ارسال بستهها را اندازه میگیرد و با استفاده از آن ازدحام را کنترل میکند.
- هر زمان که اتلاف یک بسته شناسایی شود اندازه پنجره ازدحام را نصف میکند.
1 1 مورد
2 2 مورد
3 3 مورد
4 4 مورد
گزاره اول: میدانیم ادوات داخل شبکه در کنترل ازدحام دخالتی ندارند و ما از طریق Loss، که به دو صورت timeout و یا دریافت ACK 3 تکراری تشخیص داده میشود، برای کنترل ازدحام تصمیم میگیریم و با تغییر پنجره ارسال این کار را میکنیم.
گزاره دوم: در کنترل ازدحام ما دو روش Reno و Tahoe داشتیم که در هردو روش با timeout، پنجره ارسال 1 میشد. پس این گزاره درست است.
گزاره سوم: همانطور که در گزاره اول اشاره شد، معیار ما برای کنترل ازدحام، Loss است و کاری به تأخیر ارسال بسته نداریم.
گزاره چهارم: میدانیم در روش Reno، با دریافت نسخه ACK تکراری، پنجره ارسال نصف میشود، اما در Tahoe، پنجره ارسال 1 میشود.
روش دوم: استفاده از دوره های نکته و تست درس های کنکور فناوری اطلاعات
دوره های نکته و تست علاوه بر حل و بررسی تمامی تستهای کنکور، نکاتی بیان میکنند که به درک بهتر و حل سریعتر تستها کمک میکند. برای آشنایی بیشتر با هر دوره نکته و تست از لینکهای زیر استفاده کنید.
پاسخ نامه کنکور ارشد فناوری اطلاعات
اگر میخواهید کلید نهایی کنکور ارشد فناوری اطلاعات ۱۴۰۰ یا سایر کنکورها را داشته باشید، میتوانید به صفحه دفترچه سوالات کنکور ارشد فناوری اطلاعاتدانلود رایگان دفترچه سوالات کنکور ارشد فناوری اطلاعات دفترچه سوالات کنکورهای ارشد فناوری اطلاعات (آی تی) از اولین سال برگزاری تا کنکور 1403 به همراه کلید نهایی سازمان سنجش در این صفحه بصورت رایگان وجود دارد مراجعه کنید و آنها را بهصورت رایگان دانلود کنید.
دفترچه سوالات کنکورهای ارشد فناوری اطلاعات (آی تی) از اولین سال برگزاری تا کنکور 1403 به همراه کلید نهایی سازمان سنجش در این صفحه بصورت رایگان وجود دارد مراجعه کنید و آنها را بهصورت رایگان دانلود کنید.
کلید کنکور ارشد مهندسی فناوری اطلاعات ۱۴۰۰
شما میتوانید کلید کنکور ارشد آیتی ۱۴۰۰ را در تصویر زیر مشاهده کنید. اگر میخواهید بهتمامی پاسخنامه های کلیدی کنکورهای مهندسی فناوری اطلاعات دسترسی داشته باشید، تمامی آنها در صفحه دفترچه سوالات کنکور ارشد فناوری اطلاعاتدانلود رایگان دفترچه سوالات کنکور ارشد فناوری اطلاعاتدفترچه سوالات کنکورهای ارشد فناوری اطلاعات (آی تی) از اولین سال برگزاری تا کنکور 1403 به همراه کلید نهایی سازمان سنجش در این صفحه بصورت رایگان وجود دارد قرار گرفته است.

جمعبندی
آزمون کارشناسی ارشد مهندسی فناوری اطلاعات شامل سؤالات متنوعی از جمله ساختمان داده و الگوریتمآموزش ساختمان داده و الگوریتمهر ساختمان داده یک نوع فرمت ذخیرهسازی و مدیریت دادهها در کامپیوتر است، که امکان دسترسی و اصلاح کارآمد آن دادهها را برای یکسری از الگوریتمها و کاربردها فراهم میکند، در این صفحه به بررسی و آموزش ساختمان داده و الگوریتم پرداخته شده است، هوش مصنوعیدرس هوش مصنوعیاین صفحه عالی به معرفی درس هوش مصنوعی از جمله پیش نیازهای درس هوش مصنوعی، سرفصل و منابع درس هوش مصنوعی و فیلمهای آموزشی درس هوش مصنوعی پرداخته شده، پایگاه دادهپایگاه داده چیست؟ – انواع، مفاهیم و کاربردها پایگاه داده چیست؟ این مقاله به بررسی این موضوع و همچنین انواع پایگاه داده، کاربردهای پایگاه داده، محبوب ترین پایگاه های داده و اجزای اصلی پایگاه داده پرداخته
و... است. داوطلبان برای پاسخگویی به این سؤالات نیاز به دانش عمیق و تسلط بر مباحث موردنظر دارند و لازم است که از منابع مناسبی مانند دوره نکته و تست و پلتفرم آزمون استفاده کنند.
پایگاه داده چیست؟ این مقاله به بررسی این موضوع و همچنین انواع پایگاه داده، کاربردهای پایگاه داده، محبوب ترین پایگاه های داده و اجزای اصلی پایگاه داده پرداخته
و... است. داوطلبان برای پاسخگویی به این سؤالات نیاز به دانش عمیق و تسلط بر مباحث موردنظر دارند و لازم است که از منابع مناسبی مانند دوره نکته و تست و پلتفرم آزمون استفاده کنند.
چگونه میتوانم به پاسخ تشریحی کنکور فناوری اطلاعات ۱۴۰۰ دسترسی داشته باشم؟
دو روش برای این کار در نظر گرفته شده است: 1-پلتفرم آزمون 2-دورههای نکتهوتست
آیا منابعی برای دروس کنکور فناوری اطلاعات وجود دارد؟
بله میتوانید از دورههای درس کنکور فناوری اطلاعات استفاده کنید.
چگونه میتوانم به پاسخهای کلیدی کنکورهای آیتی دسترسی داشته باشم؟
تمامی کلیدهای کنکور فناوری اطلاعات در صفحه دفترچههای کنکور آیتی موجود است.

اشتراکhttps://www.konkurcomputer.ir/a762


 از نگاه دانشجویان، قدرت بیان فوق العاده استاد رضوی و پوشش ۱۰۰ درصدی تمامی سرفصلها، نکات و تستها، ویدیوهای حل تست ساختمان داده و طراحی الگوریتم را به بهترین ویدیو حل تست کشور در درس ساختمان و الگوریتم تبدیل کرده است. این فیلم پرطرفدارترین و پرفروشترین فیلم حل تست ساختمان داده و الگوریتم کشور است و هر سال بیش از ۶۰۰۰ نفر این فیلم را تهیه میکنند
از نگاه دانشجویان، قدرت بیان فوق العاده استاد رضوی و پوشش ۱۰۰ درصدی تمامی سرفصلها، نکات و تستها، ویدیوهای حل تست ساختمان داده و طراحی الگوریتم را به بهترین ویدیو حل تست کشور در درس ساختمان و الگوریتم تبدیل کرده است. این فیلم پرطرفدارترین و پرفروشترین فیلم حل تست ساختمان داده و الگوریتم کشور است و هر سال بیش از ۶۰۰۰ نفر این فیلم را تهیه میکنند
 بهترین دوره نکته و تست هوش مصنوعی کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست هوش و نحوه استفاده از نکته و تست هوش مصنوعی گفته شده
بهترین دوره نکته و تست هوش مصنوعی کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست هوش و نحوه استفاده از نکته و تست هوش مصنوعی گفته شده
 دوره نکته و تست پایگاه داده و ویژگیها و اهمیت دوره نکته و تست پایگاه داده و نحوه استفاده صحیح از نکته و تست پایگاه داده کنکور ارشد کامپیوتر و آیتی در این صفحه عالی توضیح داده شده است
دوره نکته و تست پایگاه داده و ویژگیها و اهمیت دوره نکته و تست پایگاه داده و نحوه استفاده صحیح از نکته و تست پایگاه داده کنکور ارشد کامپیوتر و آیتی در این صفحه عالی توضیح داده شده است
 بهترین دوره نکته و تست سیستم عامل در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست سیستم های عامل و نحوه استفاده از نکته و تست سیستم عامل گفته شده
بهترین دوره نکته و تست سیستم عامل در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست سیستم های عامل و نحوه استفاده از نکته و تست سیستم عامل گفته شده
 بهترین دوره نکته و تست شبکه کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست شبکه های کامپیوتری و نحوه استفاده از نکته و تست شبکه گفته شده
بهترین دوره نکته و تست شبکه کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست شبکه های کامپیوتری و نحوه استفاده از نکته و تست شبکه گفته شده
 بهترین دوره نکته و تست ریاضیات گسسته کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست گسسته و نحوه استفاده از نکته و تست گسسته گفته شده
بهترین دوره نکته و تست ریاضیات گسسته کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست گسسته و نحوه استفاده از نکته و تست گسسته گفته شده




































