چه میخواهید برای اولینبار یک تست را حل کنید، چه آن را مرور کنید یا حتی یک کنکور را شبیهسازی کنید، به پاسخ تشریحی هر تست نیاز دارید. این مقاله به بررسی پاسخ تشریحی کنکور ارشد کامپیوتر ۱۳۹۷ میپردازد و روشهایی برای دسترسی به جواب تشریحی در اختیارتان قرار میدهد. در انتهای مقاله به نحوه دسترسی به پاسخ نامه یا کلید کنکور ارشد کامپیوتر ۱۳۹۷ و سایر سالها اشاره میکنیم.

روش های دسترسی به پاسخنامه تشریحی تست های کنکور ارشد کامپیوتر ۱۳۹۷
برای دسترسی به پاسخ تشریحی تمامی تست های کنکور ارشد کامپیوتر ۱۳۹۷ و سایر سالها میتوانید از روشهای زیر استفاده کنید.
روش اول: استفاده از پلتفرم آزمون کنکور کامپیوتر
پلتفرم آزمون یک محیط جامع برای دانشجویان است که آنها را از خرید هرگونه کتاب و منبع دیگری برای تستزنی بینیاز میکند. این پلتفرم علاوه بر پوشش پاسخ تشریحی تمامی تستهای کنکور برای تمامی درسها، محیطی برای ساخت آزمونهای شخصیسازی شده جهت شبیهسازی، رقابت با دیگر دانشجویان و… است. برای کسب اطلاعات بیشتر درباره این پلتفرم میتوانید به صفحه پلتفرم آزمون مراجعه کنید.

برای آشنایی شما باکیفیت بینظیر پلتفرم آزمون، پاسخنامه تشریحی درسهای هوش مصنوعیدرس هوش مصنوعی این صفحه عالی به معرفی درس هوش مصنوعی از جمله پیش نیازهای درس هوش مصنوعی، سرفصل و منابع درس هوش مصنوعی و فیلمهای آموزشی درس هوش مصنوعی پرداخته شده، شبکه های کامپیوتریجامعترین آموزش درس شبکه های کامپیوتری
این صفحه عالی به معرفی درس هوش مصنوعی از جمله پیش نیازهای درس هوش مصنوعی، سرفصل و منابع درس هوش مصنوعی و فیلمهای آموزشی درس هوش مصنوعی پرداخته شده، شبکه های کامپیوتریجامعترین آموزش درس شبکه های کامپیوتری درس شبکه های کامپیوتری یکی از مهمترین و بنیادیترین دروس رشته کامپیوتر است، با توجه به اینکه اینترنت امروزی بزرگترین سیستم مهندسی ساخت دست بشر در تمام طول تاریخ است، آشنایی با شبکههای کامپیوتری برای تمامی علاقهمندان و دانشجویان رشته کامپیوتر الزامی است، در این راستا در این صفحه به معرفی شبکههای کامپیوتری پرداخته شده است، سیستم عاملمعرفی درس سیستم عامل – بهترین آموزش درس سیستم عامل در کشور
درس شبکه های کامپیوتری یکی از مهمترین و بنیادیترین دروس رشته کامپیوتر است، با توجه به اینکه اینترنت امروزی بزرگترین سیستم مهندسی ساخت دست بشر در تمام طول تاریخ است، آشنایی با شبکههای کامپیوتری برای تمامی علاقهمندان و دانشجویان رشته کامپیوتر الزامی است، در این راستا در این صفحه به معرفی شبکههای کامپیوتری پرداخته شده است، سیستم عاملمعرفی درس سیستم عامل – بهترین آموزش درس سیستم عامل در کشور درس سیستم عامل در این صفحه معرفی شده، همچنین بهترین آموزش درس سیستم عامل در کشور را میتوانید در این صفحه تهیه کنید، فصول و مراجع سیستم عامل نیز بررسی شده و پایگاه دادهدرس پایگاه داده ⚡️ پایگاه داده کنکور ارشد کامپیوتر و آی تی
درس سیستم عامل در این صفحه معرفی شده، همچنین بهترین آموزش درس سیستم عامل در کشور را میتوانید در این صفحه تهیه کنید، فصول و مراجع سیستم عامل نیز بررسی شده و پایگاه دادهدرس پایگاه داده ⚡️ پایگاه داده کنکور ارشد کامپیوتر و آی تی این مقاله عالی توضیح داده که درس پایگاه داده چیست و چه کاربردهایی دارد و منابع و سرفصل های درس پایگاه داده در آزمون کنکور ارشد کامپیوتر و آی تی را بررسی کرده
برای کنکور کامپیوتر ۱۳۹۷ در زیر قرار گرفته است.
این مقاله عالی توضیح داده که درس پایگاه داده چیست و چه کاربردهایی دارد و منابع و سرفصل های درس پایگاه داده در آزمون کنکور ارشد کامپیوتر و آی تی را بررسی کرده
برای کنکور کامپیوتر ۱۳۹۷ در زیر قرار گرفته است.
تست های درس هوش مصنوعی کنکور کامپیوتر ۱۳۹۷ به همراه جواب تشریحی
دشوار
در مورد الگوریتم برنامهریزی گرافپلن (Graphplan)، کدام عبارت درست است؟
برنامه ریزی
1 اگر در سطح kام از گراف برنامهریزی، دو گزاره با یکدیگر ناسازگاری متقابل (mutual exclusion) داشته باشند، نمیتوان با انجام k کنش از وضعیت اولیه به وضعیتی رسید که شامل هر دو گزاره باشد.
2 در هنگام ساخت گراف برنامهریزی (Planning Graph)، در صورتیکه یک سطح دقیقاً مشابه سطح قبلی باشد، ولی هنوز برنامهای به دست نیامده باشد، الگوریتم متوقف میشود.
3 در برنامه یافتشده توسط این الگوریتم، تمام کنشهای انتخابشده از هر سطح، لزوماً باید قبل از تمام کنشهای انتخابشده از سطح بعد قرار گیرند تا برنامه حاصل معتبر باشد.
4 برنامه یافتشده توسط این الگوریتم از نظر تعداد کنشها بهینه است.
گزینه 1 صحیح است.
گراف برنامهریزی یک گراف لایهای است که در هر مرحله کنشها و لیترالهایی که قابل دستیابی همزمان نیستند را ردیابی میکند. این گراف شامل سطحهای حالات و کنشها و یالهای اثرات و پیش شرطها میباشد.
گزینه ۱ : درست است چرا که اگر این ناسازگاری در سطح kام وجود داشته است در سطوح قبلی نیز برقرار بوده است و با k کنش نمیتوان به وضعیتی که هر دو در آن برقرار باشند رسید در واقع یکی از ویژگیهای گراف برنامهریزی، کاهش یکنواخت تعارضات با افزایش سطوح گراف میباشد.
گزینه ۲ : شرط خاتمه وقتی است که سطح، تعارضات، لیترالها و کنشها در دو مرحله متوالی دقیقا شبیه به هم باشند.
گزینه ۳ : نادرست است.
گزینه ۴ : این روش تقریبی از روش بهینه را مییابد نه دقیقا خود آن را.
دشوار
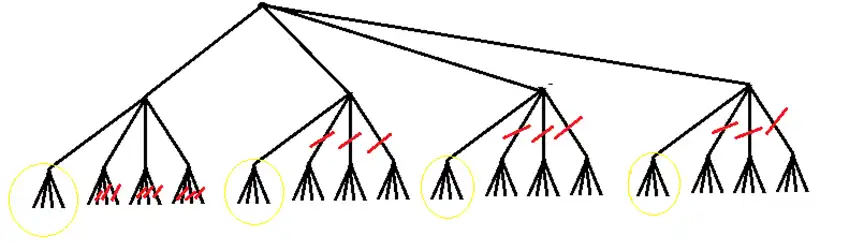
یک درخت جستجوی minimax را درنظر بگیرید که دارای عمق 3 باشد و هر گره در آن دقیقاً 4 فرزند داشته باشد (درخت 64 گره برگ دارد). اگر از روش هرس آلفا- بتا در جستجو استفاده کنیم، حداکثر چه تعداد از گرههای این درخت ممکن است هرس شود؟
بازی های رقابتی
1 48
2 45
3 35
4 32
گزینه 2 صحیح است.
می دانیم که در درخت مورد نظر سوال در جستجو minimax با اعمال روش هرس آلفا-بتا حتما چپترین زیردرخت که با دایره در شکل زیر مشخص شده است مشاهده میشود اما سایر گرهها مشخص شده در شرایطی ممکن است همزمان هرس شوند.
با توجه به شکل بالا از میان برگها ۹ برگ در زیر درخت اول و ۱۲× ۳ برگ در سایر زیر درختها هرس شده است که روی هم برابر ۴۵ برگ میشود که منظور سوال هم همین تعداد برگهای هرس شده بوده است نه تعداد کل گرههایی که ممکن است هرس شوند چون در این صورت عددی بزرگتری بدست میآمد که در گزینهها آن را نداریم.
دشوار
در خصوص الگوریتم \( {A}^* \) در حالت استفاده از یک تابع ابتکاری سازگار (consistent) h (در صورتی که g(n) هزینه مسیر طی شده تا گره n باشد)، کدام مورد نادرست است؟
الگوریتم های جستجوی آگاهانه
1 همواره مسیر بهینه به هدف را (در حالت جستجوی گرافی) پیدا میکند.
2 ممکن است گرههایی را که مقدار g(n) + h(n) آنها بیشتر از طول مسیر بهینه است، گسترش دهد.
3 ممکن است گرههایی را که مقدار g(n) آنها بیشتر از طول مسیر بهینه است، تولید کند (یعنی در صف بگذارد).
4 ممکن است گرههایی را که مقدار g(n) + h(n) آنها بیشتر از طول مسیر بهینه است، تولید کند (یعنی در صف بگذارد).
گزینه 2 صحیح است.
گزینه ۱: عبارت این گزینه درست است و A* با تابع ابتکاری سازگار و جستجو گرافی و تابع ابتکاری قابل قبول و جستجو درختی بهینه است.
گزینه ۲ : این گزینه نادرست است و ممکن است مطابق با عبارت گزینه ۴ این گرهها را تولید کند اما قبل از اینکه نوبت به بسط این گرهها برسد به هدف میرسیم و مسیر بهینه یافت میشود.
گزینه ۳ : این گزینه نیز درست است و با توجه به اینکه در هر مرحله فرزندان گره بسط داده شده به صف اضافه میشوند ممکن است این حالت پیش آید.
گزینه ۴ : این گزینه نیز درست است و با توجه به اینکه در هر مرحله فرزندان گره بسط داده شده به صف اضافه میشوند ممکن است این حالت پیش آید.
دشوار
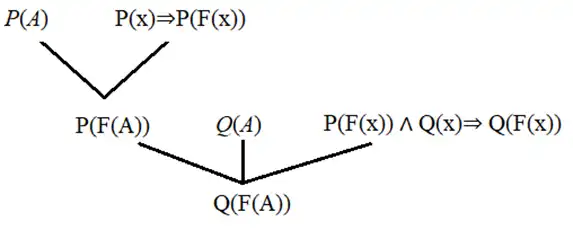
پایگاه دانش متشکل از عبارتهای Horn زیر را درنظر بگیرید. فرض کنید روش زنجیرهای جلورو (Forward Chaining) با استفاده از جستجوی سطح اول (Breadth First Search) و روش زنجیرهای عقبرو (Backward Chaining) با استفاده از جستجوی عمق اول (Depth First Search) پیادهسازی شده است. در این صورت، کدام جمله
نادرست است؟
منطق مرتبه اول
$\mathrm{P}\left(\mathrm{F}\left(\mathrm{x}\right)\right)\mathrm{\ }\mathrm{\wedge }\mathrm{\ Q}\left(\mathrm{x}\right)\mathrm{\Rightarrow }\mathrm{\ Q}\left(\mathrm{F}\left(\mathrm{x}\right)\right)$
$\mathrm{P}\left(\mathrm{x}\right)\mathrm{\Rightarrow }\mathrm{P}\left(\mathrm{F}\left(\mathrm{x}\right)\right)\mathrm{\ }$
$P(A)$
$Q(A)$
1 FC گزاره $Q(F(F(A)))$ را نتیجه میدهد.
2 FC قبل از گزاره $Q(F(A))$، گزاره $P(F(A))$ را نتیجه میدهد.
3 BC برای پرسمانی (query) بهصورت $Q(F(A))$، مقدار درست (True) را برمیگرداند.
4 BC برای یک پرسمانی (query) بهصورت $Q(F(F(A)))$، مقدار نادرست (False) را برمیگرداند.
گزینه 4 صحیح است.
بررسی گزینه ها:
گزینه ۱ : عبارت این گزینه قابل نتیجهگیری از روی FC است و مراحل آن بصورت زیر است:
با داشتن P(A) و Q(A) توانستیم به P(F(A)) و Q(F(A)) با انجام دوباره این مراحل روی دو گزاره دوم به Q(F(F(A))) میتوانیم برسیم.
گزینه ۲ : مطابق با مراحل نمایش داده شده در گزینه قبل میبینیم که این گزینه نیز برقرار است.
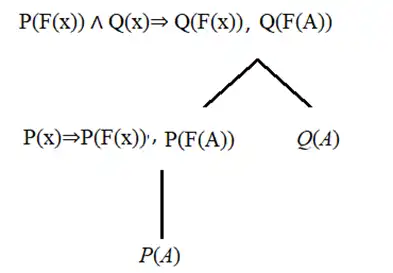
گزینه ۳ : درست است چرا که میتوان آن را طبق درخت زیر اثبات کرد چرا که هر دو برگ بدست آمده در این درخت از جملات پایگاه دانش و همواره درست هستند.
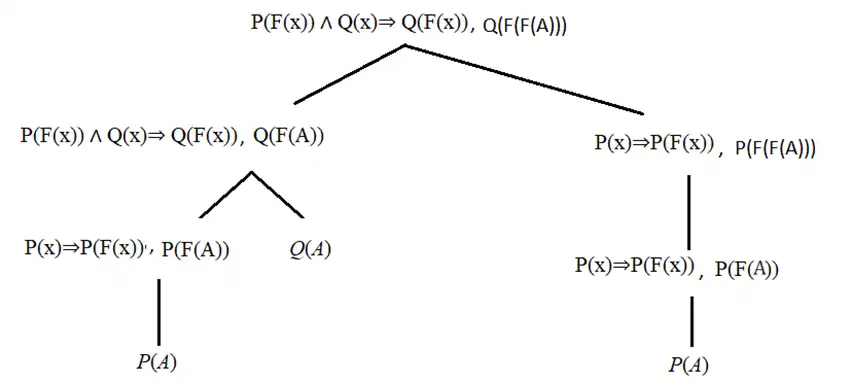
گزینه ۴ : عبارت Q(F(F(A))) را نیز میتوان طبق درخت زیر با این روش اثبات کرد و این گزینه نادرست است.
دشوار
سه عبارت $~\beta\ ،\alpha $ و $γ$ را در منطق گزارهای (propositional logic) درنظر بگیرید. در صورتی که داشته باشیم $\alpha \models \beta$ و $\alpha \nvDash \gamma$ کدام مورد در خصوص ارضاپذیری (satisfiability) و استلزام (entailment) بین عبارتها درست است؟
منطق گزارهای
1 عبارت $\beta \vee \gamma$ ممکن است ارضاپذیر (satisfiable) نباشد.
2 عبارت $\alpha \Rightarrow \gamma$ ارضاناپذیر (Unsatisfiable) است.
3 عبارت $α$ حتماً ارضاپذیر (satisfiable) است.
4 $\gamma \nvDash(\alpha \Rightarrow\beta)$
گزینه 3 صحیح است.
فرضیات صورت سوال را میتوان به صورت $M(\alpha )\ \subseteq \ M(\beta )\ ,\ M(\alpha )\ \nsubseteq \ M(\gamma )$ نوشت.
گزینه ۱ : برای اینکه عبارت $\beta \vee \gamma $ ارضا پذیر نباشد باید مدل این عبارت تهی باشد. یعنی هم $\beta$ و هم $\gamma$ باید تهی باشند. در این حالت چون $M(\alpha )\ \subseteq \ M(\beta )$ پس باید $\alpha$ هم تهی باشد که در این صورت به تناقض میرسیم چرا که میشود که خلاف فرض سوال است. پس عبارت داده شده در این گزینه حتما ارضا پذیر است.
گزینه ۲ : عبارت $\alpha \mathrm{\nvDash }\gamma $ طبق صورت سوال برقرار نیست پس میتوان نتیجه گرفت نقیض آن یعنی عبارت داده شده در گزینه دوم همواره برقرار است پس ارضا پذیر هم است.
گزینه ۳ : فرض کنیم عبارت $\alpha$ ارضاپذیر نباشد در این صورت $M(\alpha)$ تهی میشود پس از آنجا که میتوان گفت تهی زیرمجموعه هر مجموعهای است میتوان گفت $M(\alpha )\ \subseteq \ M(\gamma )$ هم برقرار است که به تناقض میرسیم پس $\alpha$ حتما ارضاپذیر است.
گزینه ۴ : سمت راست عبارت داده شده در این گزینه همواره درست است پس سمت چپ آن چه درست باشد چه غلط این استنتاج برقرار است و این گزینه که میگوید برقرار نیست نادرست است.
متوسط
کدام عبارت در مورد خصوصیات محیط (environment)، درست است؟
عامل ها و محیط ها
1 یک محیط پویا (dynamic) نمیتواند کاملاً مشاهدهپذیر (fully observable) باشد.
2 هر محیط کاملاً مشاهدهپذیر (fully observable) حتماً قطعی (deterministic) است.
3 یک محیط ناشناخته (unknown) ممکن است کاملاً مشاهدهپذیر (fully observable) باشد.
4 در یک محیط episodic، هر کنش (action) ممکن است به کنشهای انجامشده در مرحله قبل وابسته باشد.
گزینه 3 صحیح است.
گزینه ۱ : مشاهده پذیر بودن محیط به این معنی است که عامل بتواند هر اطلاعاتی از محیط که به آن نیاز دارد را با حسگرهایش بدست آورد و این ربطی به اینکه محیط پویا است یا ایستا ندارد.
گزینه ۲ : اساسا محیط های که شانس در آنها وارد میشود دیگر قطعی نیستند مثلا در بازی منچ محیط مشاهده پذیر کامل است به این معنی که محیط بازی برای هر بازیکن مشخص است اما این محیط بدلیل عنصر شانس (همان تاس) که در حرکات دخیل است محیطی غیر قطعی است.
گزینه ۳ : ناشناخته بودن محیط به این معنی است که حداقل یک کنش وجود دارد که عامل نتیجه انجام آن در محیط را نمیداند و این حالت میتواند در محیط مشاهده پذیر کامل نیز رخ دهد.
گزینه ۴ : محیط اپیزودیک یک محیط رویدادی است و شامل کنشهایی میشود که قابل تقسیم به اپیزودهای مستقل از هم هستند و تعریف ارائه شده در صورت سوال معادل برای محیط های ترتیبی است نه اپیزودیک.
آسان
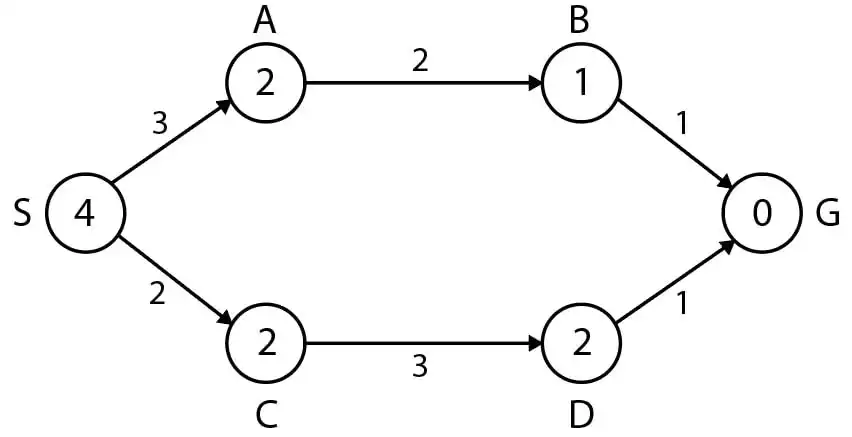
در شکل زیر هزینه کنشها روی یالها و مقدار تابع ابتکاری روی گرهها نوشته شده است. اگر S گره شروع و G گره هدف باشد، کدام مورد درست است؟ (در شرایط یکسان برای دو گروه از ترتیب الفبایی استفاده شود)
الگوریتم های جستجوی آگاهانه
1 تابع ابتکاری استفاده شده قابل قبول (admissible) است.
2 ترتیب گسترش گرهها در الگوریتم \( {A}^* \)، از چپ به راست S, C, A, B, G است.
3 ترتیب تولید گرهها در الگوریتم \( {A}^* \) ، از چپ به راست S, A, C, B, D, G است.
4 ترتیب تولید گرهها در الگوریتم UCS، از چپ به راست S, A, C, B, D, G است.
گزینه 2 صحیح است.
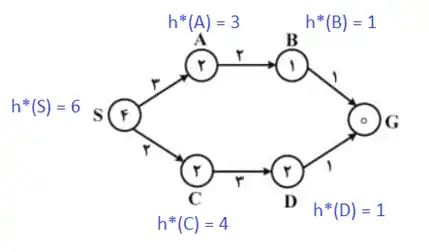
در شکل زیر مقدار h* برای گرهها مشخص شده است :
در این سوال تابع ابتکاری داده شده قابل قبول نیست چرا که در گره D شرط قابل قبول بودن یعنی بزرگتر مساوی بودن مقدار h* از تابع هیوریستیک برقرار نیست.
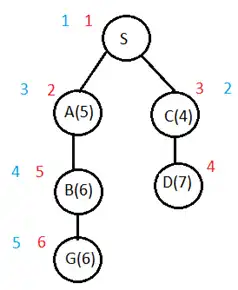
از طرفی شکل بالا گراف حاصل از اجرای الگوریتم A* روی شکل داده شده را نشان میدهد که در آن اعداد قرمز نشاندهنده ترتیب تولید گرهها و اعداد آبی ترتیب گسترش گرهها میباشد. همانطور که میبینیم ترتیب گسترش گرههای داده شده در گزینه دوم با اعداد آبی مشخص شده در شکل مطابقت دارد و این گزینه درست است.
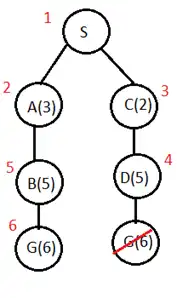
ترتیب تولید گرهها در الگوریتم UCS را نیز میتوانیم در شکل زیر ببینم که بیانگر نادرستی گزینه ۴ نیز میباشد.
دشوار
یک مسئله ارضای محدودیت با چهار متغیر C، B، A و D را درنظر بگیرید که در آن دامنه تمام متغیرها مجموعه $\left\{\mathrm{1,\ 2,\ 3,\ 4}\right\}$ است. این مسئله دارای محدودیتهای $\mathrm{A\ \lt \ B\ \lt \ C\ \lt \ D\ }$ و C = A + 3 است. میدانیم برای عدد طبیعی k، با حذف برخی مقادیر از دامنه متغیرها، ممکن است بتوان یک مسئله ارضای محدودیت را به یک مسئله strongly k-consistent تبدیل کرد. حال با فرض حذف مقادیر لازم از دامنه متغیرها، کدام مورد در خصوص مسئله فوق درست است؟
مسائل ارضای محدودیت
1 این مسئله را میتوان به یک مسئله strongly 2-consistent تبدیل کرد، ولی نمیتوان آن را به یک مسئله strongly 3-consistent تبدیل کرد.
2 این مسئله را میتوان به یک مسئله strongly 3-consistent تبدیل کرد، ولی نمیتوان آن را به یک مسئله strongly 4-consistent تبدیل کرد.
3 این مسئله را نمیتوان به یک مسئله strongly 2-consistent تبدیل کرد.
4 این مسئله را میتوان به یک مسئله strongly 4-consistent تبدیل کرد.
گزینه 3 صحیح است.
نکات :
یک مسئله ارضا محدودیت زمانی قویا K سازگار است که به ازا تمای iهای کوچکتر مساوی K این مسئله i-سازگار باشد.
یک مسئله ارضا محدودیت زمانی k-سازگار است که اگر به ازای هر k-1 متغیر از مسئله مقدار سازگار وجود داشته باشد آنگاه حداقل یک مقدار مجاز برای k امین متغیر مسئله نیز وجود داشته باشد.
با توجه به این تعریف این مسئله ۱-سازگار است به این معنی که اگر فقط یک متغیر را در نظر بگیریم امکان مقداردهی به آن وجود دارد و محدودیتهای یکانی نداریم.
اما این مسئله ۲-سازگار نیست چرا که نمیتوان مقداردهی برای متغیرها داشت که محدودیتهای دوتایی را نقض نکند. محدودیت دوتایی C= A + 3 با توجه به مقادیر دامنه متغیرها باعث میشود که A = 1 و C = 4 در نظر گرفته شود از طرفی عبارت $A \lt B \lt C \lt D$ یک عبارت ترکیبی از محدودیتهای دوتایی است و محدودیت $C \lt D$ از محدودیت بدست میآید، حال با توجه به مقداری که A و C با توجه به محدودیت C= A + 3 گرفتند و محدودیت $C \lt D$، این محدودیت قابل برطرف کردن نیست و دامنه C خالی میشود و بنابراین و امکان مقداردهی به متغیرها با در نظر گرفتن همه محدودیتها وجود ندارد و بنابراین دو سازگاری نداریم و گزینه 3 صحیح است.
دشوار
کدام جمله در مورد مسائل ارضاپذیری (SAT)، درست است؟
منطق گزارهای
1 مکانیزم انتشار عبارت واحد (Unit clause propagation) در الگوریتم DPLL برای حل مسئله SAT، کارکردی مشابه Forward chaining روی عبارتهای معین (definite clauses) دارد.
2 ارضاپذیری (satisfiability) یک عبارت منطقی، معادل معتبر (valid) بودن آن عبارت است.
3 برای حل همهی مسائل SAT پیچیدگی زمانی نمایی (برحسب تعداد نمادها) لازم است.
4 مسائل SAT زیرمجموعهای از مسائل CSP نیستند.
گزینه 1 صحیح است.
گزینه ۱ : این گزینه درست است. استفاده از هیوریستیک Unit clause که در آن کلازهایی که یک لیترال دارند مقداردهی میشوند میتواند منجر به انتشار واحد شود و این عمل را میتوان مشابه Forward chaining روی عبارتهای معین در نظر گرفت.
گزینه ۲ : یک عبارت منطقی زمانی ارضاپذیر است که حداقل در یک حالت از مقداردهی متغیرها برقرار باشد اما زمانی معتبر است که در تمامی حالات برقرار باشد و ارضاپذیر بودن و معتبر بودن با هم متفاوت هستند.
گزینه ۳ : مرتبه زمانی مسائل SAT از مرتبه نمایی است اما در بعضی از حالتهای خاص میتوان آنها را در مرتبه زمانی کمتری حل کرد همچنین استفاده از هیوریستیکها در این نوع مسائل میتوان مرتبه زمانی آنها در بعضی موارد کاهش دهد پس نمیتوان گفت برای حل همه آنها پیچیدگی زمانی نمایی لازم است.
گزینه ۴ : مسائل SAT جز زیرمجموعه مسائل CPS دستهبندی میشوند.
متوسط
فرض کنید در یک مسئله جستجو، فضای جستجو یک درخت محدود باشد که در آن هزینه هر یال یک عدد گویا است (هزینهها میتوانند منفی باشند). کدام عبارت در مورد یافتن مسیر بهینه توسط سه روش Breadth First Search ،Depth First Search، Uniform Cost Search درست است؟
الگوریتم های جستجوی ناآگاهانه
1 هر سه روش، یافتن مسیر بهینه را برای مسئله گفتهشده تضمین میکنند.
2 فقط دو روش، یافتن مسیر بهینه را برای مسئله گفته شده تضمین میکنند.
3 فقط یکی از این سه روش، یافتن مسیر بهینه را برای مسئله گفته شده تضمین میکند.
4 هیچکدام از این سه روش، یافتن مسیر بهینه را برای مسئله گفته شده تضمین نمیکنند.
گزینه 4 صحیح است.
شرایط بهینگی :
BFS : هزینه هر گره تابع غیر نزولی از عمق آن باشد (مثلا هزینه ها یکسان باشد، هزینه ها در هر سطح یکسان باشد، هزینه فرزند از والد بیشتر مساوی باشد)
DFS : در هیچ حالتی نمیتوان بهینگی این الگوریتم را تضمین کرد.
UCS : هزینه یالها باید از یک مقدار ثابت مثبت بزرگتر باشد.
با توجه به توضیحات بالا و فرضیات سوال هیچکدام از این سه روش، یافتن مسیر بهینه را برای مسئله گفتهشده تضمین نمیکنند.
دشوار
دو عبارت زیر را درنظر بگیرید. P یک رابطه، f یک تابع و a یک شیء است. کدامیک از این دو عبارت، یک جمله همیشه درست (tautology) است؟
منطق مرتبه اول
i)$\left(\mathrm{\forall }\mathrm{x\ }\mathrm{\exists }\mathrm{y\ }\mathrm{\exists }\mathrm{z}\left(\mathrm{P}\left(\mathrm{x\ ,\ y\ ,\ z}\right)\vee \neg \exists z\ \exists \mathrm{u}\left(\neg \mathrm{P}\left(\mathrm{x\ ,\ z\ ,\ u}\right)\right)\right)\right)\Rightarrow \exists \mathrm{x\ }\mathrm{\exists }\mathrm{y\ P}\left(\mathrm{f}\left(\mathrm{a}\right),\mathrm{\ x\ ,\ y}\right)$
ii) $\mathrm{\forall }\mathrm{x\ }\mathrm{\exists }\mathrm{y\ }\mathrm{\exists }\mathrm{z}\left(\left(\mathrm{P}\left(\mathrm{x\ ,\ y\ ,\ z}\right)\vee \neg \exists z\ \exists \mathrm{u}\left(\neg \mathrm{P}\left(\mathrm{x\ ,\ z\ ,\ u}\right)\right)\right)\Rightarrow \exists \mathrm{x\ }\mathrm{\exists }\mathrm{y\ P}\left(\mathrm{f}\left(\mathrm{a}\right),\mathrm{\ x\ ,\ y}\right)\right)$
1 فقط عبارت (i)
2 فقط عبارت (ii)
3 (i) و (ii)
4 هیچکدام
گزینه 1 صحیح است.
عبارت اول :
در این عبارت ابتدا نقیض پشت وجودی z و u را تاثیر میدهیم و سپس سورهای وجودی را با تابع یا ثابت اسکالم مناسب جایگرین میکنیم.
$\mathrm{(}\mathrm{\forall }\mathrm{x}~\mathrm{\exists }\mathrm{y}~\mathrm{\exists }\mathrm{z}\mathrm{(}\mathrm{P}\mathrm{(}\mathrm{x}~,~\mathrm{y}~,~\mathrm{z}\mathrm{)}\mathrm{\vee }\mathrm{\neg }\mathrm{\exists }z~\mathrm{\exists }\mathrm{u}\mathrm{(}\mathrm{\neg P}\mathrm{(}\mathrm{x}~,~\mathrm{z}~,~\mathrm{u}\mathrm{))))}\mathrm{\Rightarrow }\mathrm{\exists }\mathrm{x}~\mathrm{\exists }\mathrm{y}~\mathrm{P}\mathrm{(}\mathrm{f}\mathrm{(}\mathrm{a}\mathrm{),}~\mathrm{x}~,~\mathrm{y}\mathrm{)}$
$\mathrm{(}\mathrm{\forall }\mathrm{x}~\mathrm{(}\mathrm{P}\mathrm{(}\mathrm{x}~,f(x)~,~\mathrm{h(x)}\mathrm{)}\mathrm{\vee }\mathrm{\forall }z~\mathrm{\forall }\mathrm{u\ }\mathrm{(}\mathrm{P}\mathrm{(}\mathrm{x}~,~\mathrm{z}~,~\mathrm{u}\mathrm{))))}\mathrm{\Rightarrow }\mathrm{\exists }\mathrm{x}~\mathrm{\exists }\mathrm{y}~\mathrm{P}\mathrm{(}\mathrm{f}\mathrm{(}\mathrm{a}\mathrm{),}~\mathrm{x}~,~\mathrm{y}\mathrm{)}$
$\mathrm{(}\mathrm{\forall }\mathrm{x}~\mathrm{(}\mathrm{P}\mathrm{(}\mathrm{x}~,f(x)~,~\mathrm{h(x)}\mathrm{)}\mathrm{\vee }\mathrm{\forall }z~\mathrm{\forall }\mathrm{u\ }\mathrm{(}\mathrm{P}\mathrm{(}\mathrm{x}~,~\mathrm{z}~,~\mathrm{u}\mathrm{))))}\mathrm{\Rightarrow }~\mathrm{P}\mathrm{(}\mathrm{f}\mathrm{(}\mathrm{a}\mathrm{),}~c_1~,~c_2\mathrm{)}$
در این قسمت فقط بخش دوم سمت چپ گزاره را در نظر میگیریم و به عبارت زیر میرسیم. این عبارت از آنجا که میتوانیم از سور عمومی به سور وجودی برسیم برقرار است و میتوان گفت عبارت اول معتبر است.
$\mathrm{\forall }\mathrm{x}\mathrm{\forall }z~\mathrm{\forall }\mathrm{u\ }\mathrm{(}\mathrm{P}\mathrm{(}\mathrm{x}~,~\mathrm{z}~,~\mathrm{u}\mathrm{))\ }\mathrm{\Rightarrow }~\mathrm{P}\mathrm{(}\mathrm{f}\mathrm{(}\mathrm{a}\mathrm{),}~c_1~,~c_2\mathrm{)}$
عبارت دوم :
در این عبارت ابتدا نقیض پشت وجودی z و u را تاثیر میدهیم و سپس سورهای وجودی را با تابع یا ثابت اسکالم مناسب جایگرین میکنیم.
$\mathrm{\forall }\mathrm{x}~\mathrm{\exists }\mathrm{y}~\mathrm{\exists }\mathrm{z}\mathrm{((}\mathrm{P}\mathrm{(}\mathrm{x}~,~\mathrm{y}~,~\mathrm{z}\mathrm{)}\mathrm{\vee }\mathrm{\neg }\mathrm{\exists }z~\mathrm{\exists }\mathrm{u}\mathrm{(}\mathrm{\neg P}\mathrm{(}\mathrm{x}~,~\mathrm{z}~,~\mathrm{u}\mathrm{))}\mathrm{\Rightarrow }\mathrm{\exists }\mathrm{x}~\mathrm{\exists }\mathrm{y}~\mathrm{P}\mathrm{(}\mathrm{f}\mathrm{(}\mathrm{a}\mathrm{),}~\mathrm{x}~,~\mathrm{y}\mathrm{))}$
$\mathrm{\forall }\mathrm{x}~\mathrm{(\ \ \ (}\mathrm{P}\mathrm{(}\mathrm{x}~,f(x)~,~\mathrm{h(x)}\mathrm{)}\mathrm{\vee }\mathrm{\forall }z~\mathrm{\forall }\mathrm{u\ }\mathrm{(}\mathrm{P}\mathrm{(}\mathrm{x}~,~\mathrm{z}~,~\mathrm{u}\mathrm{))}\mathrm{\Rightarrow }\mathrm{P}\mathrm{(}\mathrm{f}\mathrm{(}\mathrm{a}\mathrm{),}~c_1~,~c_2\mathrm{)\ \ )}$
$\mathrm{\forall }\mathrm{x}~\mathrm{(\ \ \ (}\mathrm{P}\mathrm{(}\mathrm{x}~,f(x)~,~\mathrm{h(x)}\mathrm{)}\mathrm{\vee }\mathrm{\forall }z~\mathrm{\forall }\mathrm{u\ }\mathrm{(}\mathrm{P}\mathrm{(}\mathrm{x}~,~\mathrm{z}~,~\mathrm{u}\mathrm{))}\mathrm{\Rightarrow }\mathrm{P}\mathrm{(}\mathrm{f}\mathrm{(}\mathrm{a}\mathrm{),}~c_1~,~c_2\mathrm{)\ \ )}$
در این قسمت فقط بخش دوم سمت چپ گزاره را در نظر میگیریم و به عبارت زیر میرسیم در این حالت دیگر نمیتوان گفت این عبارت معتبر است چرا که سورعمومی روی x برای کل عبارت تعریف شده است و این عبارت فقط ارضاپذیر است.
$\mathrm{\forall }\mathrm{x}~\mathrm{(\ \ \ }\mathrm{\forall }z~\mathrm{\forall }\mathrm{u\ }\mathrm{(}\mathrm{P}\mathrm{(}\mathrm{x}~,~\mathrm{z}~,~\mathrm{u}\mathrm{))}\mathrm{\Rightarrow }\mathrm{P}\mathrm{(}\mathrm{f}\mathrm{(}\mathrm{a}\mathrm{),}~c_1~,~c_2\mathrm{)\ \ )}$
دشوار
با توجه به اینکه هر مدل (Model) برای یک گزاره، عبارت است از یک تفسیر (interpretation) از آن گزاره، که به آن گزاره ارزش "درست" (true) میدهد، عبارت $\left(\left(\left(\left(\left(\mathrm{A\ \Rightarrow\ B}\right)\mathrm{\ \land\ C} \right)\mathrm{\ \Leftrightarrow\ D} \right)\mathrm{\vee\ E} \right)\mathrm{\Leftrightarrow\ F} \right)\ $ برای مجموعه متغیرهای گزارهای $\{A,B,C,D,E,F \}$ چند مدل دارد؟
منطق گزارهای
1 63
2 32
3 16
4 2
گزینه 2 صحیح است.
این سوال از ما تعداد حالتهای ممکن برای مقداردهی به متغیرها که عبارت داده شده برقرار باشد را خواسته است. میدانیم برای اینکه یک عبارت دوطرفه برقرار باشد باید هر دو طرف آن T یا F باشند. یک روش برای حل این سوال این است که از بین ۶۴ حالت ممکن برای این گزاره بررسی کنیم که کدام یک این عبارت را برقرار میسازد اما این سوال با توجه به عبارتی که داده شده است راهحل سادهتری نیز دارد. در این سوال متغیر f فقط در یک سمت عبارت بکار رفته است و سمت دیگر آن یک عبارت که تابعی از ۵ متغیر است و ۳۲ حالت دارد قرار دارد. در این حالت ما میتوانیم مسئله را به این صورت در نظر بگیریم که هر کدام از این ۳۲ حالت که True بودند f را نیز True در نظر بگیریم و هر کدام False بودن f را هم False در نظر بگیریم در این صورت دو طرفه بودن عبارت برقرار است و از آنجایی که f را درسمت چپ عبارت نداریم مشکلی نیز پیش نمیآید و میتوان گفت این عبارت ۳۲ مدل دارد.
دشوار
در صورتی که بخواهیم با استفاده از روش رزولوشن (Resolution) نوع عبارت گزارهای زیر را تعیین کنیم، کدام مورد در خصوص نوع این عبارت درست است؟
منطق گزارهای
$\left(\mathrm{P\ \Rightarrow}\left(\mathrm{Q\ \Rightarrow\ R}\right)\right)\Rightarrow\left(\left(\mathrm{P\ \Rightarrow\ Q}\right)\Rightarrow\left(\mathrm{P\ \Rightarrow\ R}\right)\right)\ $
1 غیرقابل ارضاء (Unsatisfiable) است.
2 ارضاپذیر (Satisfiable) است.
3 نامعتبر (Invalid) است.
4 معتبر (Valid) است.
گزینه 4 صحیح است.
یکی از راهحلهای این سوال استفاده از قوانین استنتاج و اثبات معتبر بودن عبارت داده شده است اما از آنجایی که این عبارت فقط ۳ متغیر دارد و در کل ۸ حالت داریم میتوانیم با بررسی تک تک حالات نیز سوال را حل کنیم.
| Result |
Right side |
Left side |
R |
Q |
P |
| T |
T |
T |
F |
F |
F |
| T |
T |
T |
T |
F |
F |
| T |
T |
T |
F |
T |
F |
| T |
T |
T |
T |
T |
F |
| T |
T |
T |
F |
F |
T |
| T |
T |
T |
T |
F |
T |
| T |
F |
F |
F |
T |
T |
| T |
T |
T |
T |
T |
T |
تست های درس شبکه های کامپیوتری کنکور کامپیوتر ۱۳۹۷ به همراه جواب تشریحی
متوسط
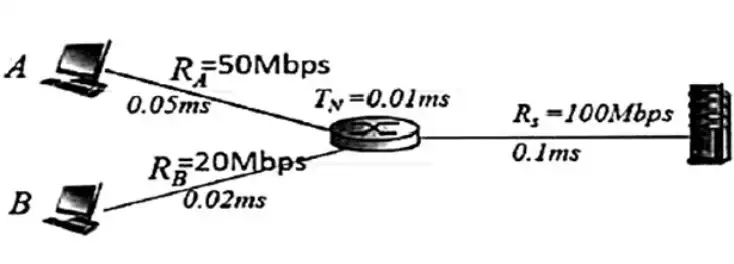
در شبکه زیر، سرور 100 بسته به کامپیوتر A و 100 بستۀ دیگر به کامپیوتر B ارسال میکند. سرور بستهها را یک در میان برای کامپیوتر A و سپس برای کامپیوتر B ارسال میکند. بهعبارت دیگر، ابتدا یک بسته به کامپیوتر A ارسال شده سپس یک بسته به کامپیوتر B ارسال میشوذ و کار تا ارسال 100 بسته برای A و 100 بسته برای B ادامه مییابد. مسیریاب برای هربسته زمان TN=0.01ms را صرف مسیریابی و سوئیچینگ میکند. اندازه هربسته 1000 بایت است. آخرین بستۀ ارسالی برای کامپیوتر B در صف مسیریاب چند میلیثانیه معطل میماند؟
(مقادیری که زیر هر لینک نوشته شده است زمان انتشار (propagation) برحسب میلیثانیه است.)
اصول و مقدمات شبکههای کامپیوتری
1 21.13 m sec
2 23.76 m sec
3 24.13 m sec
4 25.1 m sec
بسته های A روی لینک خودشان RouT می شوند و بسته های B روی لینک خودشان

یعنی بسته های A معطل بسته های A می شوند و بسته های B معطل بسته های B.

B6 در اینجا رسیده و درون صف مربوطه به لینک B می رود و چون B1 و B2 ارسال شده B3 و B4 و B5 را جلو خودش میبیند .
بعد از 2 بسته اول به ازای هر 5 بسته ای که به روتر می رسد ، 1 بسته از روتر روی لینک B گذاشته می شود.
وقتی $B_{100}$ می رسد چند بسته ارسال شده است؟
دشوار
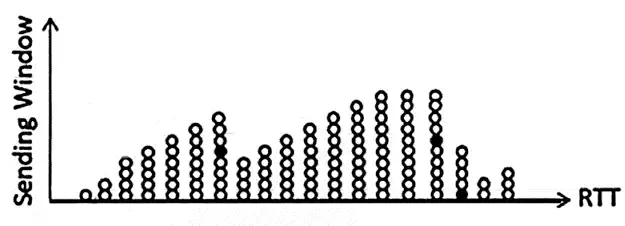
شبکهای را که در آن امکان برخورد (collision) بستهها وجود دارد و پروتکل CSMA/CD فعال است را در نظر بگیرید. در این شبکه زمان انتشار (propagation) بین نود A و نود B یک میلیثانیه (mSec) است. در لحظه $t=\circ$ نود A بستهای را با نرخ 4 مگابیت بر ثانیه ارسال میکند و در لحظه $t=0/8msec$ نود B بستهای را با نرخ 4 مگابیت بر ثانیه ارسال میکند. به ترتیب از راست به چپ حداقل اندازه بسته A چند بایت باشد که A متوجه برخورد شود و حداقل اندازه بسته B چند بایت باشد که B متوجه برخورد شود؟
لایه پیوند داده
1 1000-1000
2 600-1400
3 100-900
4 64-64
گزینه 3 صحیح است.
باتوجه به اینکه جنس لینک در طول مسیر ثابت است، پس سرعت انتشار داده در کل مسیر لینک ثابت است، کمااینکه نود صورت سؤال نیز به این موضوع اشاره کرده و گفته است که نرخ ارسال در دو نقطه A و B یکسان و برابر 4 مگابیت بر ثانیه است. با این فرض اگر بعد از 0.8 میلی ثانیه که نود A شروع به ارسال بسته کرده است، نود B نیز شروع به ارسال از سمت دیگر کند و همچنین باتوجه به اینکه تأخیر انتشار بین نود A و B 1 میلیثانیه است، پس از زمان شروع انتشار نود B، در وسط فاصله باقیمانده بین دادهای که از نود A ارسال شده و دادهای که دارد از نود B ارسال میشود، تصادم رخ میدهد که طبق شکل زیر، تصادم در زمان 0.9 میلیثانیه رخ میدهد:
حال داده اراسلی از A و B در 0.9 میلیثانیه باهم برخورد میکنند، پس هردو باید این مسیر را به سمت نودهای خود برگردند در این فاصله طول بستههای ارسالی از نودهای A و B باید بهقدری باشد که در طول زمان رفت و برگشت اولین دادههای ارسالی، ارسال بسته تمام نشود. برای طول بسته A داریم:
$= 2 ×0.9= 1.8 ms$ حداقل مدت زمانی که باید بسته A طول بکشد تا ارسال شود
$= 2 ×0.1= 0.2 ms$ حداقل مدت زمانی که باید بسته B طول بکشد تا ارسال شود
$L_A=\frac{1.8\times {10}^{-3}\times 4\times {10}^6}{8}=900\mathrm{\ }\text{بایت}$ حداقل طول بسته نود A با توجه به نرخ ارسال و زمان 1.8 میلیثانیه
$L_B=\frac{0.2\times {10}^{-3}\times 4\times {10}^6}{8}=100\mathrm{\ }\text{بایت }$ حداقل طول بسته نود B با توجه به نرخ ارسال و زمان 1.2 میلیثانیه
دشوار
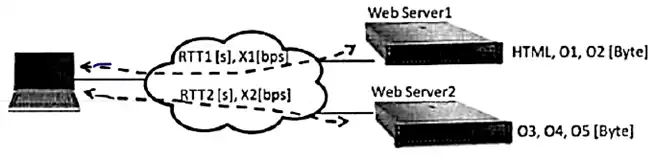
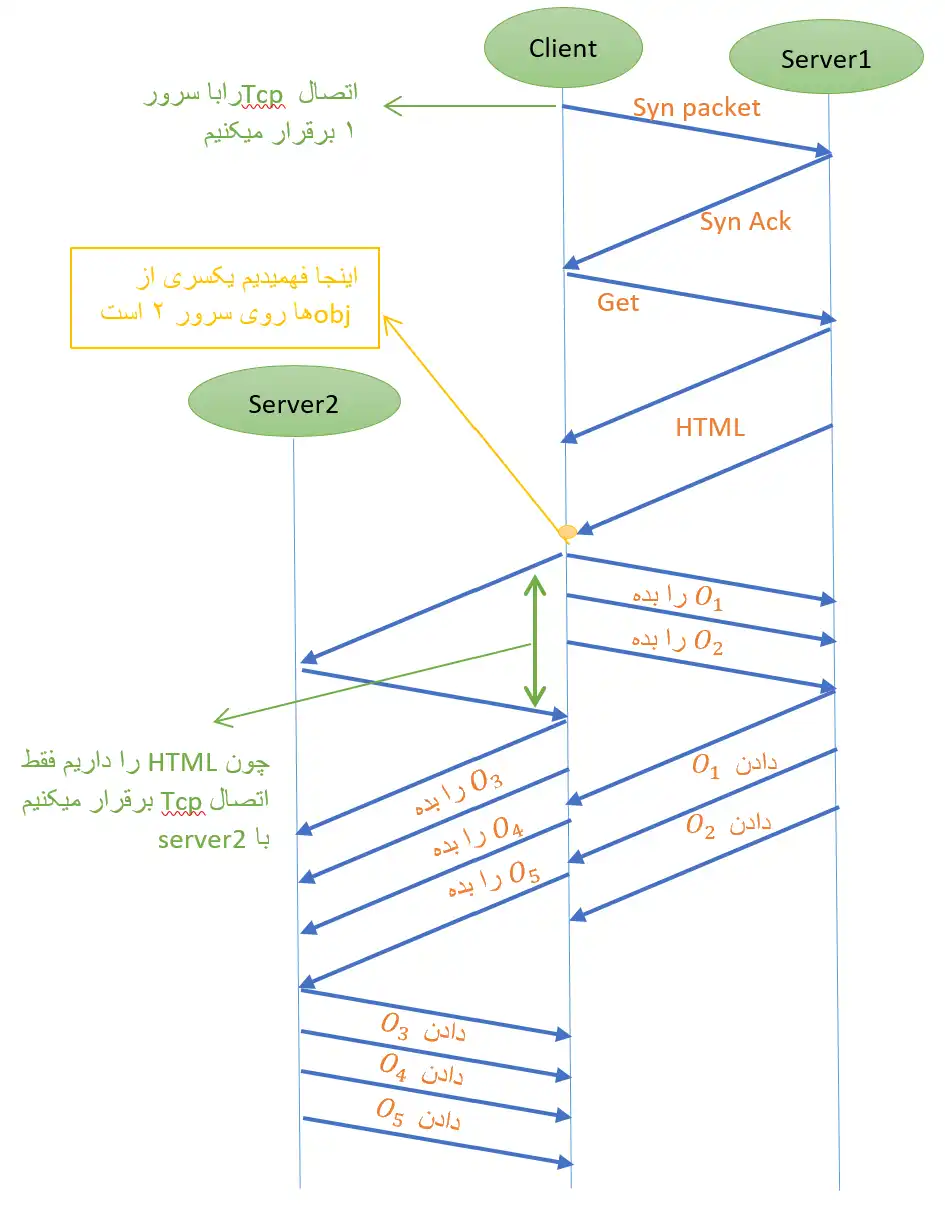
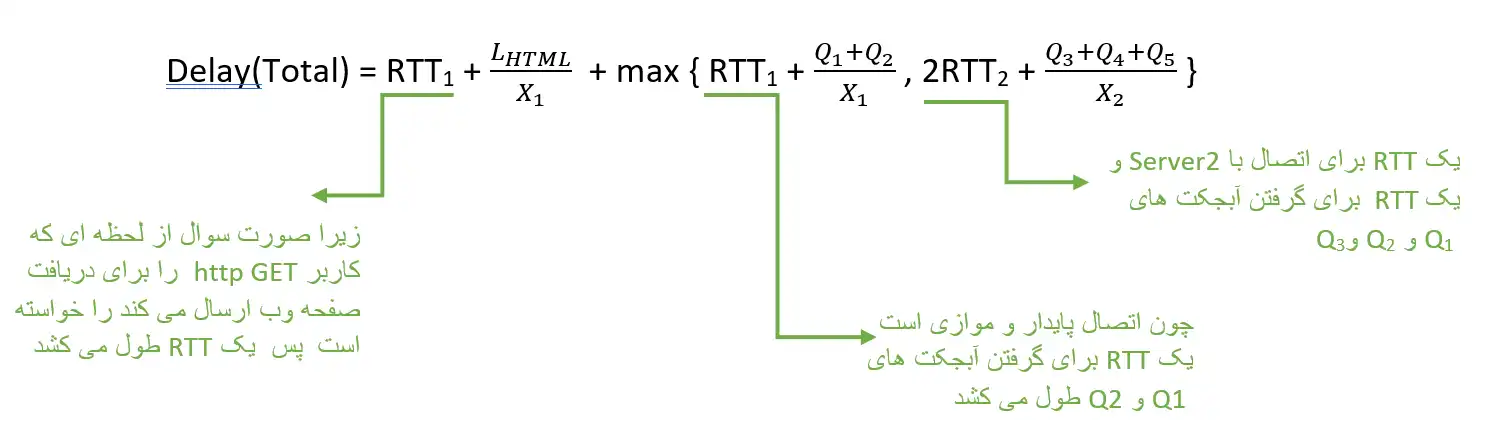
یک صفحه وب شامل یک فایل HTML و 5 آبجکت است. فایل 5000Byte =
HTMLو آبجکتهای
$Q_1$ = 5000Byte و
$O_2$ = 7000Byte روی وب سرور 1 و آبجکتهای
$O_3$ = 1000Byte و
$O_4$ = 3000Byte و
$O_5$ = 2000Byte روی وب سرور 2 قرار دارند. کاربری مایل است این صفحه وب را ببیند. زمان رفت و برگشت بین کامپیوتر کاربر و سرور 1 به اندازه
$RTT_1$ = 0/01s است. زمان رفت و برگشت بین کامپیوتر کاربر و سرور2 به اندازه
$RTT_2$ = 0/006s است. متوسط گذردهی ارتباط بین کامپیوتر کاربر و وبسرور 1 برابر با 80000=$X_1$ بیت بر ثانیه است. گذردهی ارتباط بین کامپیوتر کاربر و وب سرور 2 برابر با 60000=$X_2$ بیت بر ثانیه است.
چنانچه 1.1
http در کامپیوتر کاربر و دو وب سرور فعال باشد، از لحظهای که کاربر http GET را برای دریافت صفحه وب ارسال میکند تا زمانی که صفحه وب را کاملاً دریافت میکند. چند میلی ثانیه زمان صرف میشود؟ (توجه داشته باشید که 1.1
http به صورت persistent و pipeline کار میکند.)
لایه کاربرد
1 1/73
2 1/95
3 2/37
4 2/41
دشوار
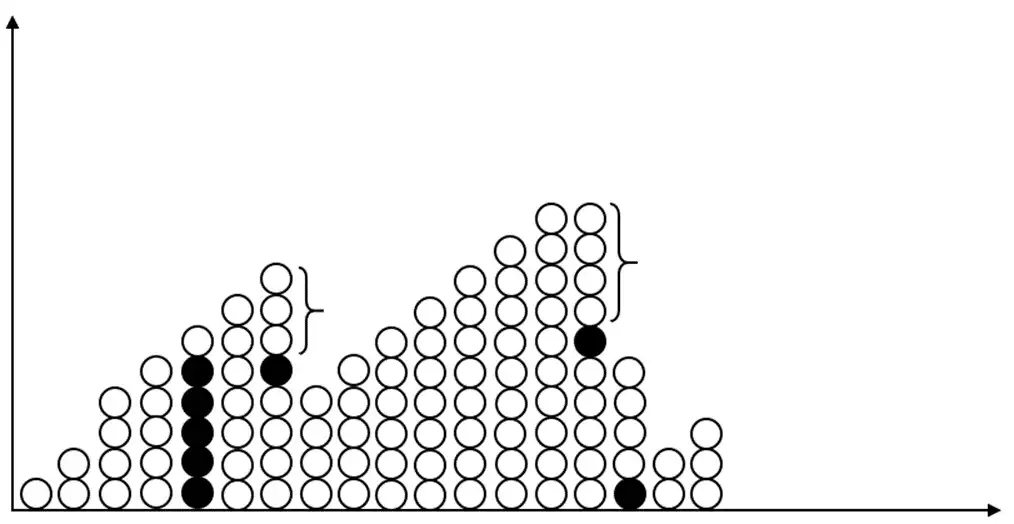
در یک ارتباط tcp، فایلی از کامپیوتر 1 به کامپیوتر 2 ارسال میشود. شکل زیر پنجرههای ارسال را در حوزه زمان نشان میدهد. در این شکل هر دایره یک بسته را نشان میدهد. دایرههای سیاه معرف بستههاییاند که به کامپیوتر 2 نرسیدهاند. اگر مکانیزم Go-Back-N فعال باشد، چند بسته بیش از یک بار به کامپیوتر 2 میرسد؟
لایه انتقال
1 7
2 9
3 11
4 14
گزینه 1 صحیح است.
بستههای مخشص شده که در کل 7 عدد هستند، بیش از یکبار به مقصد میرسند زیرا در Go-Back-n، اگر بستهای نرسد، بستههای بعدی با اینکه به مقصد رسیدهاند، دوباره ارسال میشوند. حال بستههای مشخص شده چون بعد از بسته گم شده قرار دارند، بیش از یک بار به مقصد رسیده اند.
تست های درس سیستم های عامل کنکور کامپیوتر ۱۳۹۷ به همراه جواب تشریحی
دشوار
کدام عبارت، درستتر است؟
مفاهیم سیستم عامل
1 Virtualization به شبیهسازی یک سیستم عامل وابسته به سختافزار، بر روی یک سیستم عامل وابسته به سختافزار دیگر اطلاق میشود.
2 NUMA یک حافظه توزیع شده است که در آن هر پردازنده یا هسته، به بخشهای مختلف اختصاصی دسترسی دارد.
3 System Daemon یک برنامه سیستمی مقیم در حافظه است که در صورت لزوم به صورت ناهمگام اجرا میشود.
4 Emulation به فرآیند شبیهسازی یک سیستمعامل داخل سیستمعامل دیگر اطلاق میشود.
گزینه 3 صحیح است.
بررسی گزینه 1: virtualization یک فناوری است که به ما اجازه میدهد سخت افزار یک کامپیوتر واحد را به چندین محیط اجرایی متفاوت تقسیم کنیم به طوری که هر محیط اجرایی متفاوت، یک کامپیوتر مجزا و اختصاصی به نظر برسد. در این محیط ها چندین سیستم عامل مشابه یا متفاوت میتوانند به صورت همزمان برای یک یا چند کاربر اجرا شوند. بنابراین این گزینه نادرست است.
بررسی گزینه 2: NUMA مخفف Non Uniform Memory Access به معنی دستیابی غیریکنواخت به حافظه است. در برخی از سیستمهای چندپردازنده برای جلوگیری از کاهش سرعت، به هر CPU یک حافظه تخصیص داده میشود که از طریق یک Bus کوچک به آن متصل میشوند. اما همه پردازنده ها از طریق یک سیستم میان ارتباطی مشترک به یکدیگر متصلاند طوری که به نظر میرسد همه آنها به یک حافظه مشترک بزرگ دسترسی دارند. بنابراین این گزینه نادرست است.
بررسی گزینه 4: Emulation شبیهسازی یک برنامه است که در محیط مبدا کامپایل شده و میخواهیم در محیط مقصد آن را اجرا کنیم. یعنی تنها مختص به سیستم عامل نیست. بنابراین این گزینه نادرست است.
متوسط
سیستمی با ترجمه آدرس دو – سطحی و اندازه هر صفحه 4 کیلوبایت در نظر بگیرید. اگر اندازه هر مدخل جدول صفحه برابر 2 بایت (شامل اطلاعات ترجمه و دیگر اطلاعات کنترلی لازم) باشد، چه تعداد فضای بیتی به ترتیب (از راست به چپ) برای جابهجایی (Offset)، اندیس به جدول صفحه اول و اندیس به جدول صفحه دوم برای آدرس مجازی (Virtual address) 32 – بیتی لازم است؟
حافظه مجازی
1 12، 10، 10
2 12، 11، 9
3 10، 10، 12
4 9، 11، 12
گزینه 1 صحیح است.
فرمت آدرس منطقی:
لازم است تعداد بیتهای offset را محاسبه کنیم تا بتوانیم فرمت آدرس منطقی را به دست آوریم:
$pageSize=4KB=2^2\times 2^{10}B=2^{12}B=2^x\to x=12=offset$
| $Offset=12$ |
$PT_2$ |
$PT_1$ |
بنابراین گزینه های 3 و 4 حذف میشوند.
از آنجاییکه فضای آدرس 32 بیتی است پس ${PT}_1+{PT}_2=32-12=20$
باید بین دو گزینه 1 و 2 یکی را انتخاب کنیم.
اگر فرض کنیم که منظور طراح این بوده است که هر جدول صفحه باید در یک قاب قرار بگیرد آنگاه:
تعداد سطرهای جدول صفحه جزئی $=\frac{\text{اندازه }\ \text{قاب}}{\text{عرض }\ \text{جدول }\ \text{صفحه}}=\frac{4\ KB}{2\ B}=\frac{2^2\times 2^{10}\ B}{2\ B}=2^{11}$
در این صورت ${PT}_1={PT}_2-20=20-11=9$ که در گزینه ها به ترتیب 12و 9 و11 وجود ندارد. بنابراین گزینه 1 صحیح است.
| $Off=12$ |
$PT_2=10$ |
$PT_1=10$ |
متوسط
در یک سیستم متشکل از 4 قاب که در ابتدا خالی هستند، رشته دستیابی به قابها را به ترتیب از چپ به راست 7، 6، 1، 2، 3، 2، 6، 5، 4، 3، 2، 1 در نظر بگیرید. اگر سیستم صفحهبندی تماماً مبتنی بر درخواست (pure demand paging) باشد. در صورت استفاده از الگوریتمهای FIFO و LRU به ترتیب (از راست به چپ) تعداد نقص صفحه (page fault)، کدام است؟
مدیریت حافظه
1 10، 10
2 10، 9
3 6، 6
4 6، 5
گزینه 1 صحیح است.
FIFO:
| |
1 |
2 |
3 |
4 |
5 |
6 |
2 |
3 |
2 |
1 |
6 |
7 |
| Frame$0$ |
1 |
1 |
1 |
1 |
2 |
3 |
4 |
5 |
5 |
6 |
6 |
2 |
| Frame$1$ |
|
2 |
2 |
2 |
3 |
4 |
5 |
6 |
6 |
2 |
2 |
3 |
| Frame$2$ |
|
|
3 |
3 |
4 |
5 |
6 |
2 |
2 |
3 |
3 |
1 |
| Frame$3$ |
|
|
|
4 |
5 |
6 |
2 |
3 |
3 |
1 |
1 |
7 |
| PF |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
|
+ |
|
+ |
تعداد نقص صفحه در این الگوریتم برابر با 10 تاست.
LRU:
| |
1 |
2 |
3 |
4 |
5 |
6 |
2 |
3 |
2 |
1 |
6 |
7 |
| Frame$0$ |
1 |
1 |
1 |
1 |
2 |
3 |
4 |
5 |
5 |
6 |
3 |
2 |
| Frame$1$ |
|
2 |
2 |
2 |
3 |
4 |
5 |
6 |
6 |
3 |
2 |
1 |
| Frame$2$ |
|
|
3 |
3 |
4 |
5 |
6 |
2 |
3 |
2 |
1 |
6 |
| Frame$3$ |
|
|
|
4 |
5 |
6 |
2 |
3 |
2 |
1 |
6 |
7 |
| PF |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
|
+ |
|
+ |
تعداد نقص صفحه در این الگوریتم نیز برابر با 10 تاست.
تست های درس پایگاه داده کنکور کامپیوتر ۱۳۹۷ به همراه جواب تشریحی
آسان
با توجه به گزارههای زیر کدام مورد درست است؟
پایگاه داده رابطهای
a) مدل مفهومی پایگاه داده، استقلال دادهای را افزایش میدهد.
b) اگر ${{k}_1}$ و ${{k}_2}$ ابر کلیدهای رابطه R باشند، آنگاه $k_{\mathrm{1}}\mathrm{\cap }k_{\mathrm{2}}$ یک ابر کلید R است.
c) برای اتصال به پایگاه داده، در Connection String نحوه احراز هویت کاربر مشخص میشود.
d) در رابطه R با تعداد خصیصه بزرگتر از یک، تعداد ابر کلیدها همواره از تعداد کلیدهای کاندید بیشتر است.
1 a درست، b درست
2 a درست، c درست
3 d درست، b نادرست
4 b نادرست، c نادرست
گزینه 2 صحیح است.
بررسی گزاره a: این گزاره درست است. یکی از مهمترین اهداف مدل مفهومی پایگاه داده افزایش استقلال دادهای است.
بررسی گزاره b: این گزاره نادرست است. فرض کنید جدولی به نام دانشجو داریم که شامل ستونهای کد ملی و شماره دانشجویی باشد. کد ملی به تنهایی و شماره دانشجویی نیز به تنهایی ابرکلید میباشند. اما اشتراک این دو تهی است و کلید نمیتواند تهی باشد.
بررسی گزاره c: این گزاره درست است. طبق تعریف، connection string شامل خصیصههایی مانند نام سرور و نام پایگاه داده و همچنین اطلاعات کاربر مانند نام کاربری و کلمه عبور است. بنابراین این گزاره قابلقبول است زیرا براساس اطلاعات کاربری موجود در connection string احراز هویت کاربر انجام میشود.
بررسی گزاره d: این گزاره نادرست است. اگر رابطهای تمام کلید باشد تعداد ابرکلید با تعداد کلید کاندید برابر است.
دشوار
پس از اجرای دستورات زیر (به ترتیب مشخص شده) تعداد سطرهای جدول Person کدام است؟
زبان و پرس و جوی SQL
|
create table person(
personID int,
managerID int,
level int,
primary key (personID),
foreign key (managerID) references person(personID) on delete cascade on
update restrict)
|
دستور اول |
|
insert into person values
(14, null, 1),
, (12,14,2)
,(11,12,3)
,(13,12,3)
,(15,12,3)
,(10,14,2)
,(17,10,3)
,(18,10,3)
|
دستور دوم |
| Delete from person where level = 2 |
دستور سوم |
1 6
2 8
3 1
4 0
گزینه 3 صحیح است. براساس تعریف جدول person و کلید اصلی و خارجی آن و همچنین دستور on delete cascade میتوان نتیجه گرفت که تمامی سطرهایی که شرط level=2 برای آنها برقرار است حذف میشوند و هم کلیه سطرهای ارجاع کننده به آنها نیز باید حذف شوند.بنابراین دو سطر مربوط به کارمندان با شناسه 10 و 12 در شرط داده شده صدق میکنند و حذف میشود.از طرفی سطر کارمند شماره 12 مورد ارجاع سه سطر دیگر (از طریق کد مدیر) است و سطر کارمند شماره 10 مورد ارجاع دو سطر دیگر است. در نهایت 7 سطر حذف میشوند و یک سطر باقی میماند.
دشوار
باتوجه به رابطه $R(A,B,C,D,E,F)$ و مجموعه وابستگیهای تابعی زیر، رابطه R چند کلید کاندید دارد؟
طراحی پایگاه داده
$F = \{A \to BCD , BC \to DE , B \to D , D \to A\}$
1 4
2 3
3 2
4 1
گزینه 2 صحیح است. چند نکته در رابطه با تشخیص کلید کاندید از روی مجموعه وابستگی:
1- ابتدا وابستگیهای بازتابی حذف شوند.
2- صفتی که در سمت راست هیچ وابستگی تابعی نباشد حتما در کلید است.
3- اجزا کلید به یکدیگر وابستگی تابعی ندارند.
4- صفتی که فقط در سمت راست وابستگی تابعی باشد هرگز در کلید نیست
5- اگر با این نکات کلید یافت نشد آنگاه مجموعه بسط دترمینانها محاسبه میشود و دترمینانی که کمینه باشد و همه صفات را پوشش دهد کلید کاندید است.
(بهتر است برای بررسی راحتتر، وابستگیها را زیر هم بنویسید.)
$A\to BCD$
$BC\to DE$
$B\to D$
$D\to A$
صفت F در سمت راست هیچکدام از وابستگیها نیست پس جزئی از کلید است.صفت E فقط در سمت راست وابستگیها آمده است پس نمیتواند جزئی از کلید باشد.حال باید بسط دترمینان بنویسیم:$\{AF\}+ = \{A,B,C,D,E,F\}$
چون دو صفت AF تمامی صفات را میدهد و کمینه است پس کلید کاندید است.با استفاده از قانون شبه تعدی میتوان بقیه کلیدهای کاندید را بهدست آورد.( چون D میتواند A را بدهد پس میتوان A را با D جایگزین کرد. همچنین B نیز D را میدهد پس میتوان D را با B جایگزین کرد کلیدهای کاندید عبارت اند از : AF , DF , BF
دشوار
جدول T را در نظر بگیرید که روی ستون Clustered Index ،a شده است. کدام مورد درست است؟
شاخص گذاری اطلاعات
1 اعمال سیاست شاخصگذاری، تأثیری بر حجم اطلاعات ذخیره شده بر روی دیسک ندارد.
2 با اعمال سیاست شاخصگذاری، پاسخ به Range Query های مرتبط به a، با سرعت بیشتری انجام میشود.
3 با اعمال سیاست شاخصگذاری، پاسخ به Equality Query های مرتبط به a، با سرعت کمتری انجام میشود.
4 همه موارد درست هستند.
گزینه 2 صحیح است.
بررسی گزینه 1: شاخصگذاری از هرنوعی که باشد حجم اطلاعات ذخیره شده در دیسک را افزایش میدهد، بنابراین گزینه اول نادرست است.
بررسی گزینه 2 و 3 :بطور کلی هدف از شاخص گذاری افزایش سرعت جستجو و بازیابی اطلاعات از پایگاه داده است.بنابراین اعمال سیاستهای شاخصگذاری، سرعت پردازش و پاسخ گویی به equality query و range query را افزایش میدهد، بنابراین گزینه 2 درست و گزینه 3 نادرست است.
دشوار
با توجه به گزارههای زیر، کدام مورد درست است؟
پایگاه داده رابطهای
الف) اگر رابطه R، دارای n = 2k خصیصه باشد، آنگاه تعداد کلیدهای کاندید آن حداقل یک و حداکثر $\left(\begin{matrix}n\\k\\\end{matrix}\right)$ است.
ب) اگر رابطه R دارای n خصیصه باشد، آنگاه تعداد ابرکلیدهای این رابطه حداکثر $\left(\begin{matrix}n\\\circ\\\end{matrix}\right)+\left(\begin{matrix}n\\\mathrm{1}\\\end{matrix}\right)+...+\left(\begin{matrix}n\\n\\\end{matrix}\right)$ است.
ج) تعداد ابرکلیدهای یک رابطه همواره بیشتر از تعداد کلیدهای کاندید آن رابطه است.
د) هر صفت مرکب، لزوماً تک مقداری است.
1 یک گزاره نادرست است.
2 دو گزاره نادرست است.
3 سه گزاره نادرست است.
4 چهار گزاره نادرست است.
گزینه 3 صحیح است.
بررسی گزاره a: این گزاره درست است. زیرا هر جدولی حداقل یک کلید کاندید دارد.
حالت حداکثر با توجه به مفروضات گزاره a، همواره رابطه زیر برقرار است:
$max\left(\begin{matrix}\left(\begin{matrix}n\\k\end{matrix}\right)\left(\begin{matrix}n\\2\end{matrix}\right),....,\left(\begin{matrix}n\\k\end{matrix}\right)+\left(\begin{matrix}n\\k+1\end{matrix}\right),....,\left(\begin{matrix}n\\n\end{matrix}\right)\end{matrix}\right)=\left(\begin{matrix}n\\k\end{matrix}\right)$
مثال: اگر $k=2$، آنگاه $n=2k=4$:
$max\left(\begin{matrix}\left(\begin{matrix}4\\1\end{matrix}\right)\left(\begin{matrix}4\\2\end{matrix}\right)\left(\begin{matrix}4\\3\end{matrix}\right)\left(\begin{matrix}4\\4\end{matrix}\right)\end{matrix}\right)=\left(\begin{matrix}4\\2\end{matrix}\right)$
طبق مثال واضح است که حد وسط بیشترین مقدار است.
بررسی گزاره b: این گزاره نادرست است. زیرا ما ابرکلید بدون صف نداریم پس حالت $\left(\begin{matrix}n\\0\\\end{matrix}\right)$ اضافه است.
بررسی گزاره c: این گزاره نادرست است. زیرا اگر رابطهای تمام کلید باشد تعداد ابرکلیدها با تعداد کلیدهای کاندید برابر است.
بررسی گزاره d: این گزاره نادرست است. نوع صفات مستقل از یکدیگر هستند یعنی صفتی میتواند مرکب باشد اما چند مقداری باشد.
دشوار
رابطههای جدول داده شده را در نظر بگیرید. با اجرای دستور زیر حداقل و حداکثر تعداد سطرهای خروجی کدام است؟
زبان و پرس و جوی SQL
Select * from Student left outer join Student Course
| نام جدول |
تعداد سطرها |
| Student(Stid , StName, …) |
K>0 |
| Course(Cid, CName, …) |
N>0 |
| Student Course(Stid , Cid , grade) |
M>0 |
1 حداقل K و حداکثر K + N - 1
2 حداقل 1 و حداکثر K + N - 1
3 حداقل N و حداکثر K + N
4 حداقل K و حداکثر K + N
جواب صحیح گزینه 1و 4 با تاثیر مثبت.
برای بهدست آوردن حداقل و حداکثر تعداد سطرها باید دو حالت را در نظر بگیریم:
الف) حالت حداقل: طبق صورتسوال هیچکدام از جداول خالی نیستند و حداقل یک سطر دارند. در این حالت میتوان گفت که فقط یک دانشجو یک درس را اخذ کرده و در آن نمره گرفته است. پس از اجرای پرسوجو تمام سطرهای پیوند پذیر از جدول student (یک سطر پیوند پذیر) و همه سطرهای پیوند ناپذیر (k-1 سطر) در خروجی ظاهر میشوند که برابر است با k سطر.
ب) حالت حداکثر: در این حالت میتوان گفت که همه دانشجویان همه دروس را اخذ کردهاند و در آنها نمره گرفتهاند. چون جدول student دارای k سطر و جدول course دارای N سطر است پس تعداد سطرهای پیوند پذیر برابر k*N سطر است که در هیچیک از گزینهها به آن اشاره نشده است.
کلید سازمان سنجش گزینه 1 و 4 با تاثیر مثبت است.
دشوار
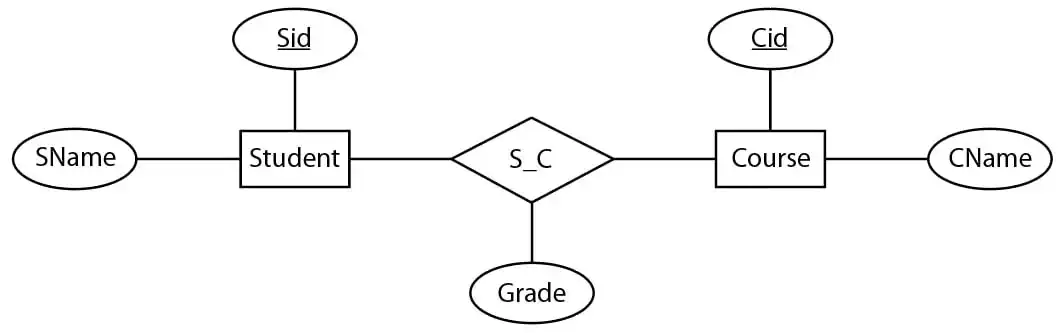
با توجه به نمودار ER داده شده، کدام مورد برای پرسوجو «نام دانشجویانی که معدل آنها از میانگین نمرات همه دروس دانشگاه بیشتر است»
نادرست است؟
طراحی پایگاه داده
1 select SName from Student T1
(select S_C.Sid from S_C
group by S_C.Sid having AVG(grade) > (Select AVG(grade) from S_C)) T2
where T1.Sid = T2.Sid
2
select SName from Student T1
where exists (select '1' from S_C
where T1.Sid = S_C.Sid
group by S_C.Sid having AVG(grade) > (Select AVG(grade) from S_C))
3
select SName from Student
where Sid in (select Sid from S_C
group by Sid having AVG(grade) > (Select AVG(grade) from S_C))
4
select SName from Studcnt,S_C
where student.sid = S_C.sid and AVG(grade) > (Select AVG(grade) from S_C)
علت نادرست بودن گزینه 4
هر چهار گزینه پرسوجو داده شده را برآورده میکنند امّا گزینه ۴ خطای نحوی دارد،
زیرا نمیتوان از توابع تجمعی در قسمت where استفاده کرد.
روش دوم: استفاده از دوره های نکته و تست درس های کنکور کامپیوتر
با استفاده از دوره های نکته و تست درس های کنکور کامپیوتر، علاوه بر دسترسی به پاسخ تشریحی تمامی تستهای آن درس، به نکات و روشهایی اشاره میشود که به درک بهتر درس و حل سریعتر تستها کمک میکند. با استفاده از لینکهای زیر میتوانید اطلاعات بیشتری کسب کنید.
پاسخ نامه کنکور ارشد کامپیوتر ۱۳۹۷
اگر میخواهید صرفاً به پاسخ کلیدی هر تست از دفترچههای کنکور دسترسی داشته باشید، میتوانید تمامی آنها را در صفحه دفترچه سوالات کنکور ارشد مهندسی کامپیوتردانلود سوالات کنکور ارشد کامپیوتر دفترچه سوالات کنکورهای ارشد کامپیوتر از اولین سال برگزاری تا کنکور 1403 به همراه کلید نهایی سازمان سنجش در این صفحه بصورت رایگان قرار داده شده است تا بتوانید به راحتی و بدون صرف زمان زیاد برای جستجو در اینترنت، از دفترچه سوالات سالهای گذشته استفاده نمایند دانلود کنید. همچنین از دانلود دفترچه کنکور کامپیوتر ۱۳۹۷ میتوانید به دفترچه و پاسخنامه کلیدی این کنکور دسترسی داشته باشید.
دفترچه سوالات کنکورهای ارشد کامپیوتر از اولین سال برگزاری تا کنکور 1403 به همراه کلید نهایی سازمان سنجش در این صفحه بصورت رایگان قرار داده شده است تا بتوانید به راحتی و بدون صرف زمان زیاد برای جستجو در اینترنت، از دفترچه سوالات سالهای گذشته استفاده نمایند دانلود کنید. همچنین از دانلود دفترچه کنکور کامپیوتر ۱۳۹۷ میتوانید به دفترچه و پاسخنامه کلیدی این کنکور دسترسی داشته باشید.
کلید کنکور ارشد کامپیوتر ۱۳۹۷
برای دسترسی به کلید کنکور ارشد کامپیوتر ۱۳۹۷ میتوانید از تصویر زیر استفاده کنید. همچنین بهتمامی پاسخهای کلیدی کنکور ارشد کامپیوترمعرفی ارشد کامپیوتر ارشد کامپیوتر چیست؟
این مقاله عالی به معرفی ارشد کامپیوتر میپردازد و درباره آینده رشته کامپیوتر و نحوه اپلای کردن توضیح میدهد میتوانید در صفحه دفترچه سوالات کنکور ارشد مهندسی کامپیوتردانلود سوالات کنکور ارشد کامپیوتردفترچه سوالات کنکورهای ارشد کامپیوتر از اولین سال برگزاری تا کنکور 1403 به همراه کلید نهایی سازمان سنجش در این صفحه بصورت رایگان قرار داده شده است تا بتوانید به راحتی و بدون صرف زمان زیاد برای جستجو در اینترنت، از دفترچه سوالات سالهای گذشته استفاده نمایند دسترسی داشته باشید.
ارشد کامپیوتر چیست؟
این مقاله عالی به معرفی ارشد کامپیوتر میپردازد و درباره آینده رشته کامپیوتر و نحوه اپلای کردن توضیح میدهد میتوانید در صفحه دفترچه سوالات کنکور ارشد مهندسی کامپیوتردانلود سوالات کنکور ارشد کامپیوتردفترچه سوالات کنکورهای ارشد کامپیوتر از اولین سال برگزاری تا کنکور 1403 به همراه کلید نهایی سازمان سنجش در این صفحه بصورت رایگان قرار داده شده است تا بتوانید به راحتی و بدون صرف زمان زیاد برای جستجو در اینترنت، از دفترچه سوالات سالهای گذشته استفاده نمایند دسترسی داشته باشید.

جمعبندی
آزمون کارشناسی ارشد کامپیوتر شامل سوالات متنوعی از جمله طراحی الگوریتمآموزش طراحی الگوریتم به زبان ساده درس طراحی الگوریتم یکی از مهمترین و بنیادیترین دروس رشته کامپیوتر است. هدف از این درس، معرفی روشهای مختلف طراحی الگوریتمها برای حل مسائل گوناگون است، در این صفحه به معرفی و آموزش طراحی الگوریتم پرداخته شده است. و ساختمان دادهآموزش ساختمان داده و الگوریتم
درس طراحی الگوریتم یکی از مهمترین و بنیادیترین دروس رشته کامپیوتر است. هدف از این درس، معرفی روشهای مختلف طراحی الگوریتمها برای حل مسائل گوناگون است، در این صفحه به معرفی و آموزش طراحی الگوریتم پرداخته شده است. و ساختمان دادهآموزش ساختمان داده و الگوریتم هر ساختمان داده یک نوع فرمت ذخیرهسازی و مدیریت دادهها در کامپیوتر است، که امکان دسترسی و اصلاح کارآمد آن دادهها را برای یکسری از الگوریتمها و کاربردها فراهم میکند، در این صفحه به بررسی و آموزش ساختمان داده و الگوریتم پرداخته شده است، شبکهجامعترین آموزش درس شبکه های کامپیوتریدرس شبکه های کامپیوتری یکی از مهمترین و بنیادیترین دروس رشته کامپیوتر است، با توجه به اینکه اینترنت امروزی بزرگترین سیستم مهندسی ساخت دست بشر در تمام طول تاریخ است، آشنایی با شبکههای کامپیوتری برای تمامی علاقهمندان و دانشجویان رشته کامپیوتر الزامی است، در این راستا در این صفحه به معرفی شبکههای کامپیوتری پرداخته شده است، هوش مصنوعیدرس هوش مصنوعیاین صفحه عالی به معرفی درس هوش مصنوعی از جمله پیش نیازهای درس هوش مصنوعی، سرفصل و منابع درس هوش مصنوعی و فیلمهای آموزشی درس هوش مصنوعی پرداخته شده و ... است. داوطلبان برای پاسخگویی به این سوالات نیاز به دانش عمیق و تسلط بر مباحث مورد نظر دارند و لازم است که از منابع مناسبی استفاده کنند پس استفاده از دوره نکته و تست و پلتفرم آزمون را به شما پیشنهاد میکنیم.
هر ساختمان داده یک نوع فرمت ذخیرهسازی و مدیریت دادهها در کامپیوتر است، که امکان دسترسی و اصلاح کارآمد آن دادهها را برای یکسری از الگوریتمها و کاربردها فراهم میکند، در این صفحه به بررسی و آموزش ساختمان داده و الگوریتم پرداخته شده است، شبکهجامعترین آموزش درس شبکه های کامپیوتریدرس شبکه های کامپیوتری یکی از مهمترین و بنیادیترین دروس رشته کامپیوتر است، با توجه به اینکه اینترنت امروزی بزرگترین سیستم مهندسی ساخت دست بشر در تمام طول تاریخ است، آشنایی با شبکههای کامپیوتری برای تمامی علاقهمندان و دانشجویان رشته کامپیوتر الزامی است، در این راستا در این صفحه به معرفی شبکههای کامپیوتری پرداخته شده است، هوش مصنوعیدرس هوش مصنوعیاین صفحه عالی به معرفی درس هوش مصنوعی از جمله پیش نیازهای درس هوش مصنوعی، سرفصل و منابع درس هوش مصنوعی و فیلمهای آموزشی درس هوش مصنوعی پرداخته شده و ... است. داوطلبان برای پاسخگویی به این سوالات نیاز به دانش عمیق و تسلط بر مباحث مورد نظر دارند و لازم است که از منابع مناسبی استفاده کنند پس استفاده از دوره نکته و تست و پلتفرم آزمون را به شما پیشنهاد میکنیم.
چه روشهایی برای دسترسی به پاسخ تشریحی تستهای کنکور کامپیوتر ۱۳۹۷ وجود دارد؟
دو روش برای این منظور وجود دارد: (۱) پلتفرم آزمون (۲) دورههای نکته و تست
آیا منابعی برای دروس کنکور کامپیوتر وجود دارد؟
بله. میتوانید از دورههای درس کنکور کامپیوتر استفاده کنید.
آیا روشی برای دسترسی به پاسخ کلیدی کنکور ارشد کامپیوتر ۱۳۹۷ وجود دارد؟
بله شما میتوانید نهتنها پاسخ کلیدی سال ۱۳۹۷ بلکه تمامی سالها را از صفحه دفترچههای کنکور ارشد کامپیوتر دانلود کنید.

اشتراکhttps://www.konkurcomputer.ir/c4cc


 از نگاه دانشجویان، قدرت بیان فوق العاده استاد رضوی و پوشش ۱۰۰ درصدی تمامی سرفصلها، نکات و تستها، ویدیوهای حل تست ساختمان داده و طراحی الگوریتم را به بهترین ویدیو حل تست کشور در درس ساختمان و الگوریتم تبدیل کرده است. این فیلم پرطرفدارترین و پرفروشترین فیلم حل تست ساختمان داده و الگوریتم کشور است و هر سال بیش از ۶۰۰۰ نفر این فیلم را تهیه میکنند
از نگاه دانشجویان، قدرت بیان فوق العاده استاد رضوی و پوشش ۱۰۰ درصدی تمامی سرفصلها، نکات و تستها، ویدیوهای حل تست ساختمان داده و طراحی الگوریتم را به بهترین ویدیو حل تست کشور در درس ساختمان و الگوریتم تبدیل کرده است. این فیلم پرطرفدارترین و پرفروشترین فیلم حل تست ساختمان داده و الگوریتم کشور است و هر سال بیش از ۶۰۰۰ نفر این فیلم را تهیه میکنند
 بهترین دوره نکته و تست هوش مصنوعی کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست هوش و نحوه استفاده از نکته و تست هوش مصنوعی گفته شده
بهترین دوره نکته و تست هوش مصنوعی کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست هوش و نحوه استفاده از نکته و تست هوش مصنوعی گفته شده
 دوره نکته و تست پایگاه داده و ویژگیها و اهمیت دوره نکته و تست پایگاه داده و نحوه استفاده صحیح از نکته و تست پایگاه داده کنکور ارشد کامپیوتر و آیتی در این صفحه عالی توضیح داده شده است
دوره نکته و تست پایگاه داده و ویژگیها و اهمیت دوره نکته و تست پایگاه داده و نحوه استفاده صحیح از نکته و تست پایگاه داده کنکور ارشد کامپیوتر و آیتی در این صفحه عالی توضیح داده شده است
 بهترین دوره نکته و تست سیستم عامل در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست سیستم های عامل و نحوه استفاده از نکته و تست سیستم عامل گفته شده
بهترین دوره نکته و تست سیستم عامل در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست سیستم های عامل و نحوه استفاده از نکته و تست سیستم عامل گفته شده
 بهترین دوره نکته و تست شبکه کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست شبکه های کامپیوتری و نحوه استفاده از نکته و تست شبکه گفته شده
بهترین دوره نکته و تست شبکه کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست شبکه های کامپیوتری و نحوه استفاده از نکته و تست شبکه گفته شده
 دوره نکته و تست نظریه زبان ها و ماشین ها در این صفحه قرار گرفته و ویژگی ها و اهمیت دوره نکته و تست نظریه زبان ها و ماشین ها بررسی شده است
دوره نکته و تست نظریه زبان ها و ماشین ها در این صفحه قرار گرفته و ویژگی ها و اهمیت دوره نکته و تست نظریه زبان ها و ماشین ها بررسی شده است
 دوره نکته و تست سیگنال و سیستم و ویژگیهای نکته و تست سیگنال و نحوه استفاده صحیح از نکته و تست سیگنال کنکور ارشد کامپیوتر در این صفحه عالی توضیح داده شده
دوره نکته و تست سیگنال و سیستم و ویژگیهای نکته و تست سیگنال و نحوه استفاده صحیح از نکته و تست سیگنال کنکور ارشد کامپیوتر در این صفحه عالی توضیح داده شده
 بهترین دوره نکته و تست مدار منطقی کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست مدار منطقی و نحوه استفاده از نکته و تست مدار منطقی گفته شده
بهترین دوره نکته و تست مدار منطقی کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست مدار منطقی و نحوه استفاده از نکته و تست مدار منطقی گفته شده
 بهترین دوره نکته و تست الکترونیک دیجیتال کشور در این صفحه معرفی شده و اهمیت دوره نکته و تست الکترونیک دیجیتال و نحوه استفاده صحیح از دوره بیان شده است
بهترین دوره نکته و تست الکترونیک دیجیتال کشور در این صفحه معرفی شده و اهمیت دوره نکته و تست الکترونیک دیجیتال و نحوه استفاده صحیح از دوره بیان شده است
 بهترین دوره نکته و تست ریاضیات گسسته کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست گسسته و نحوه استفاده از نکته و تست گسسته گفته شده
بهترین دوره نکته و تست ریاضیات گسسته کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست گسسته و نحوه استفاده از نکته و تست گسسته گفته شده




































