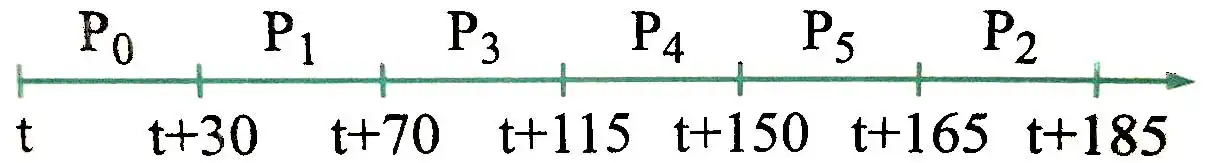در این صفحه نمونه سوالات سیستم عامل با پاسخ تشریحی برای شما عزیزان قرار داده شده است، سعی شده مثال های سیستم عامل تمامی مباحث را در بر گیرد. در صورتی که علاقه دارید تا بیشتر با درس سیستم عامل آشنا شوید و فیلم های رایگان سیستم عامل را مشاهده کنید به صفحه معرفی و بررسی الکترونیک دیجیتالمعرفی درس الکترونیک دیجیتال درس الکترونیک دیجیتال در تمامی دانشگاههای جهان به منظور آشنایی با مبانی الکترونیک و سختافزار و تکنولوژیهای استفاده شده از زمان پیدایش کامپیوتر تا کنون تدریس میشود مراجعه کنید.
درس الکترونیک دیجیتال در تمامی دانشگاههای جهان به منظور آشنایی با مبانی الکترونیک و سختافزار و تکنولوژیهای استفاده شده از زمان پیدایش کامپیوتر تا کنون تدریس میشود مراجعه کنید.
قبل از اینکه به ادامه این مقاله بپردازیم توصیه میکنیم که فیلم زیر که در خصوص تحلیل و بررسی درس سیستم عامل است را مشاهده کنید، در این فیلم توضیح داده شده که فیلم درس سیستم عامل برای چه افرادی مناسب است و همین طور در خصوص فصول مختلف درس سیستم عامل و اهمیت هر کدام از فصول آن صحبت شده است.
در ادامه این مقاله ابتدا فیلم های رایگان سیستم عامل که به آنها نیاز دارید و سپس نمونه سوالات سیستم عامل در اختیارتان قرار گرفته است.
فیلم های رایگان آموزش سیستم عامل که به آنها نیاز دارید
در حال حاضر فیلم آموزش سیستم عامل استاد رضوی پرطرفدارترین و پرفروشترین فیلم آموزشی سیستم عامل کشور است و هر سال اکثر داوطلبان کنکور ارشد کامپیوتر این فیلم را تهیه میکنند.

سیستم عامل جلسه 1

سیستم عامل جلسه 2

سیستم عامل جلسه 3

سیستم عامل جلسه 4

سیستم عامل جلسه 1 نکته و تست

سیستم عامل جلسه 2 نکته و تست

بررسی سوالات سیستم عامل کنکور ارشد کامپیوتر 1403

حل تشریحی سیستم عامل کنکور ارشد کامپیوتر 1403

حل تشریحی سیستم عامل کنکور ارشد آیتی 1403
خرید فیلم های کامل سیستم عامل

فیلم درس سیستم عامل
۱۵٪ تخفیف
950,000 تومان
810,000 تومان
رامین رضوی
۶۰ ساعت
فیلم نکته و تست سیستم عامل
۱۵٪ تخفیف
800,000 تومان
680,000 تومان
رامین رضوی
30 ساعت
نمونه سوالات فصل مفاهیم پایه درس سیستم عامل
آسان هدف اصلی از عملیات dual-mode چیست؟ مفاهیم پایه
1تشخیص خطاها
2کاهش توان مصرفی کامپیوتر
3توانایی سیستم عامل در کنترل پردازنده
4محافظت سیستم عامل از دیگر نرم افزارها
پاسخ گزینه 4 است.
چون سیستم عامل و کاربرها از منابع سختافزاری و نرمافزاری مشترکی استفاده میکنند، یک سیستم عامل مناسب باید مطمئن شود که یک برنامه خطرناک یا نادرست نتواند اختلالی در فعالیت دیگر برنامهها و خود سیستم عامل ایجاد کند. برای رسیدن به این هدف از dual-mode استفاده میشود.
متن کتاب Operating System Concepts (Abraham Silberschatz, Greg Gagne etc.):
The dual mode of operation provides us with the means for protecting the operating system from errant users—and errant users from one another.
متوسط کدام یک از گزینههای زیر صحیح است؟ مفاهیم پایه
1خواندن PSW در مود کرنل صورت میگیرد.
2ناتوان ساختن وقفهها در مود کاربر انجام میشود.
3تغییر اولویت پروسسها در مود کاربر صورت میگیرد.
4عمل تغییر وضعیت از مود کرنل به مود کاربر و بلعکس از امکانات سختافزاری است که برای کمک مستقیم به سیستم عامل طراحی شده است.
پاسخ گزینه 4 است.
به طور کلی انواع خواندن ها، نوشتن در ثبات ها و پاک کردن حافظه، در مود کاربر قرار دارد و انواع تنظیمات، تغییر اولویت فرآیند ها، تغییر بیت وقفه و مدیریت IO، در مود کرنل قرار دارد.
با توجه به توضیح بالا، گزینه های 1 و2 و3 رد میشوند. در نتیجه پاسخ گزینه 4 است.
آسان اگر نرخ انتقال اطلاعات بین حافظه اصلی و حافظه مجازی 50 MB / Sec، اندازه هر فرایند به طور متوسط 10MB و سیستم عامل چند برنامگی (Multi program) باشد که بتواند فرایندهای زیادی داخل حافظه بارگذاری کرده و همزمان با DMA اجرا نماید و هر فرایند ۲۰۰ میلی ثانیه به CPU نیاز داشته باشد، نرخ بهرهوری CPU به کدام مورد نزدیکتر است؟ مفاهیم پایه
1%100
2%75
3%50
4%25
گزینه 1 صحیح است.
بنابر اطلاعات داده شده در صورت سوال نرخ انتقال اطلاعات بین حافظه اصلی و حافظه مجازی 50 MB / Sec است. با توجه به اینکه اندازه هر فرآیند 10MB است. بنابراین انتقال هر فرآیند بین حافظه اصلی و حافظه مجازی به $\frac{10}{50}=200 msec$ زمان نیاز دارد. حال باتوجه به اینکه cpu time هر فرآیند نیز $200 msec $ است و بنابه فرض سوال فرآیندها امکان اجرای همزمان با DMA را دارند. بنابراین زمانی که یک فرآیند در حال سپری کردن زمان پردازش خودش است، DMA فرآیند دیگری را از حافظه مجازی به اصلی انتقال داده و از آنجایی که این زمان انتقال با زمان CPU فرآیند در حال اجرا برابر است، CPU به محض اتمام یک فرآیند، فرآیند دیگری برای اجرا در حافظه اصلی خواهد داشت. که در این صورت CPU هیچگاه در صورت وجود فرآیندی برای اجرا بیکار نمانده. بنابراین بهرهوری آن 100% خواهد بود.
نمونه سوالات فصل مفاهیم سیستم عامل
دشوار کدام عبارت، درستتر است؟ مفاهیم سیستم عامل
1Virtualization به شبیهسازی یک سیستم عامل وابسته به سختافزار، بر روی یک سیستم عامل وابسته به سختافزار دیگر اطلاق میشود.
2NUMA یک حافظه توزیع شده است که در آن هر پردازنده یا هسته، به بخشهای مختلف اختصاصی دسترسی دارد.
3System Daemon یک برنامه سیستمی مقیم در حافظه است که در صورت لزوم به صورت ناهمگام اجرا میشود.
4Emulation به فرآیند شبیهسازی یک سیستمعامل داخل سیستمعامل دیگر اطلاق میشود.
گزینه 3 صحیح است.
بررسی گزینه 1: virtualization یک فناوری است که به ما اجازه میدهد سخت افزار یک کامپیوتر واحد را به چندین محیط اجرایی متفاوت تقسیم کنیم به طوری که هر محیط اجرایی متفاوت، یک کامپیوتر مجزا و اختصاصی به نظر برسد. در این محیط ها چندین سیستم عامل مشابه یا متفاوت میتوانند به صورت همزمان برای یک یا چند کاربر اجرا شوند. بنابراین این گزینه نادرست است.
بررسی گزینه 2: NUMA مخفف Non Uniform Memory Access به معنی دستیابی غیریکنواخت به حافظه است. در برخی از سیستمهای چندپردازنده برای جلوگیری از کاهش سرعت، به هر CPU یک حافظه تخصیص داده میشود که از طریق یک Bus کوچک به آن متصل میشوند. اما همه پردازنده ها از طریق یک سیستم میان ارتباطی مشترک به یکدیگر متصلاند طوری که به نظر میرسد همه آنها به یک حافظه مشترک بزرگ دسترسی دارند. بنابراین این گزینه نادرست است.
بررسی گزینه 4: Emulation شبیهسازی یک برنامه است که در محیط مبدا کامپایل شده و میخواهیم در محیط مقصد آن را اجرا کنیم. یعنی تنها مختص به سیستم عامل نیست. بنابراین این گزینه نادرست است.
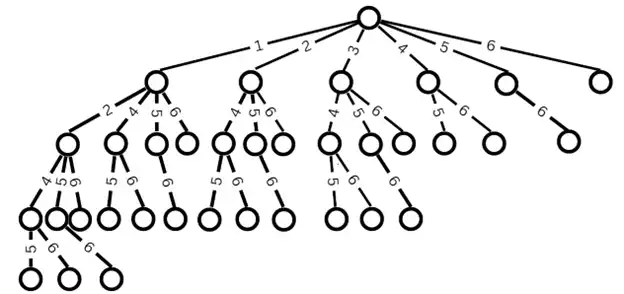
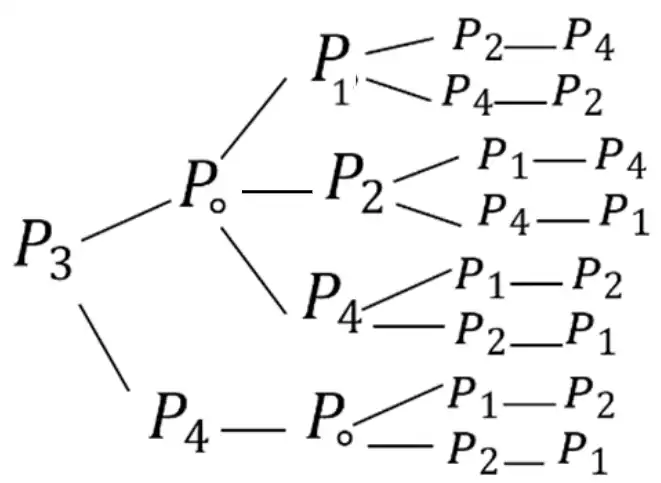
دشوار تابع ()fork وقتی صدا زده میشود یک پردازه فرزند تولید میشود که همروند با پردازه والد فراخوانده اجرا میشود که هر دو از دستور بعدی اجرا میشود. چنانچه این تابع در هر فراخوانی مقدار صفر برای فرآیند فرزند و مقدار مثبت برای فرآیند والد تولید کند، تکه برنامه زیر چندبار Hello چاپ میکند؟
مفاهیم سیستم عامل
if (fork( ) & fork ( ))
fork ( );
if (fork ( ) | fork ( ))
fork ( );
printf (“Hello”);
.
.
.
120
225
330
435
دستور () fork دستوری در سیستمعاملها میباشد که برای ایجاد فرآیندهای جدید استفاده میشوند. در زمان اجرای این دستور برای والد عدد مثبت، برای فرزند صفر و اگر اروری رخ دهد عدد منفی بازمیگرداند.
برای حل این سؤال ابتدا جهت راحتی کار دستورات fork را به ترتیب آمده در شکل زیر شمارهگذاری میکنیم.
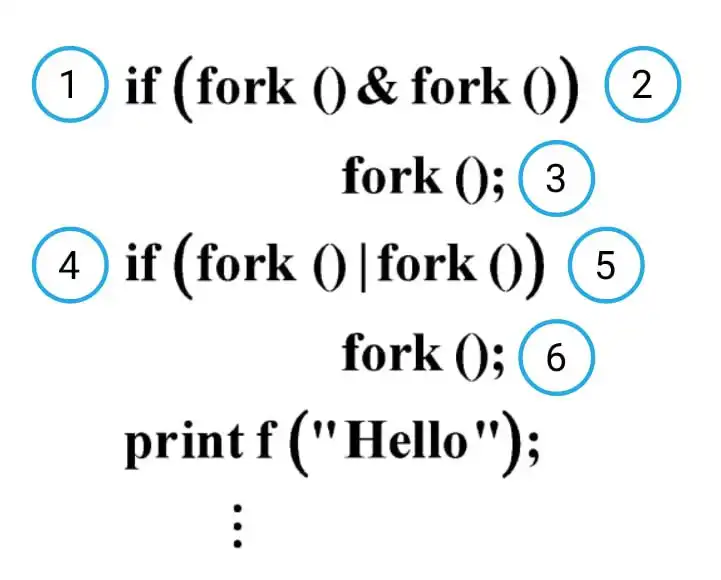
حال به بررسی دستورات fork از پایین به بالا میپردازیم و در نهایت درخت اجرای فرآیندها را رسم میکنیم.
اگر شماره ۶ اجرا شود دیگر forkای اجرا نشده و ۱ بار اجرای پرینت داریم.
اگر شماره ۵ اجرا شود دو حالت پیش میآید:
1. اگر fork شماره ۴ در هنگام اجرا ۱ برگردانده باشد ۶ نیز اجرا شد و در مجموع ۲ بار اجرای پرینت بیشتر داریم.
2. اگر fork شماره ۴ در هنگام اجرا ۰ برگردانده باشد ۶ دیگر اجرا نشده و فقط ۱ پرینت اضافه داریم. این حالت فقط زمانی اتفاق میافتد که این fork از فرزندان فرآیندی باشد که آن نیز فرزند ایجاد شده توسط اجرای fork شماره ۴ است.
اگر شماره ۴ اجرا شود، پس از آن ۵ و ۶ اجرا میشوند که چون شماره ۴ اجرا شده و ۰ برگردانده است هر کدام از دو دستور دیگر ۵ و ۶ یک پرینت اضافه دارند.
اگر شماره ۳ اجرا شود، سه fork، ۴ و ۵ و ۶ اجرا میشوند که نحوه اجرای آنها به شکل بیان شده در ۳ مورد قبل است.
اگر شماره ۲ اجرا شود، عملکرد کاملا مشابه اجرای fork شماره ۳ است.
اگر شماره ۱ اجرا شود، چهار fork، ۲ و ۴و ۵ و ۶ پس از آن به نحو بیان شده در بالا اجرا میشوند. شماره ۳ اجرا نمیشود زیرا با اجرای ۱ شرط if اول نقض میشود.
در نهایت درخت فرآیندهای اجرایی به شکل زیر میشود (هر گره نشانگر یک فرآیند است و برروی یالها شماره fork اجرا شده آمده است). اگر تعداد گرهها را بشمارید تعداد فرآیندهای اجرا شده ۳۵ تا میباشد که هر کدام ۱ بار Hello را پرینت کرده است.
سنجش گزینه 1 و 4 را با تاثیر مثبت اعلام کرده است.
علت آن هم این است که اگر فرض کنیم برنامه طوری است که در and و orدو طرف عملگر در هر حالتی اجرا میشوند (طوری که در اینجا براساس آن عمل شد) تعداد print ها برابر ۳۵ میشود. امّا اگر or به گونهای باشد که اگر عملوند اول ۱ شد عملوند دوم اجرا نشود و اگر and به گونهای باشد که اگر عملوند اول 0 شد عملوند دوم اجرا نشود تعداد printها برابر ۲۰ میشود.
احتمالا چون سنجش در سؤال این موضوع را مشخص نکرده سوال به صورت تاثیر مثبت در آمده است.
برای اینکه این ۲۰ تا را ببینید در درخت بالا شاخههای ۲ که شاخه ۱ در همسایگی ندارند را حذف کنید (به همراه تمام فرزندان منتهی به آن شاخه) همچنین اگر در همسایگی شاخه ۵، شاخه ۴ وجود داشت آن شاخه ۵ (به همراه تمام فرزندان منتهی به آن شاخه) را حذف کنید.
دشوار در چه صورتی یک فرایند فرزند که Zombie شده است، تبدیل به یک فرایند Orphan (یتیم) میشود؟ مفاهیم سیستم عامل
1در صورتی که فرایند پدر، دستور (terminate) را برای فرایند فرزند اجرا نکرده باشد.
2در صورتی که فرایند پدر برای فرایند فرزند، دستور (wait) را اجرا نکرده باشد.
3چنین حالتی هیچگاه در سیستم عامل رخ نمیدهد.
4درصورتی که فرایند فرزند دچار بنبست شود.
فرآیند zombie: فرآیندی است که وظیفهاش را به طور کامل انجام داده است اما هنوز در جدول فرآیند یک entry دارد. فرآیندی که زامبی شده است امکان از بین بردن خودش را ندارد. بنابراین فرآیند پدر بایستی اجرا شده و دستور از بین بردن فرآیند فرزند zombie شده خود را صادر کند. در صورتی که فرآیند پدر این دستور را صادر نکند، فرآیند فرزند zombie شده باقی خواهد ماند.
فرآیند orphan: فرآیند فرزندی که والدش پس از اتمام کار و یا از بین رفتن منتظر اجرای فرآیند فرزند نمانده و فرآیند فرزند پس از آن همچنان در حال اجراست. بنابراین اگر فرآیند والد دستور wait را برای فرآیند فرزند zombie شده خود صادر نکند و خودش از بین برود، فرآیند zombie شده به orphan تبدیل میشود.
آسان پروسس (فرآیند یا پردازه) فرزند، کدام یک از موارد زیر را از پروسس پدر به ارث نمیبرد؟ مفاهیم سیستم عامل
1تایمر
2دایرکتوری جاری
3نام کاربر اجرا کننده
4توصیفگر فایلهای باز
پاسخ گزینه 1 است.
چون باید تایمر هر فرآیند به صورت جداگانه در نظر گرفته شود، بنابراین فرآیند فرزند نمیتواند این مورد را از پدر به ارث ببرد. ولی سایر موارد میتواند به صورت اشتراکی بین فرآیند های پدر و فرزند استفاده شود.
آسان فرض کنید دو فرآیند $P_{\mathrm{1}}$ و $P_{\mathrm{2}}$ روی یک سیستم multitask قرار داشته باشند. اگر فرآیند $P_{\mathrm{1}}$ وظیفه مرتب کردن لیستی بزرگ از دادهها با طول دلخواه را بر عهده داشته باشد و فرآیند $P_{\mathrm{2}}$ یک عملیات محاسباتی دیگر روی هر کدام از دادههای لیست مرتب شده انجام دهد، کدام یک از روشها برای تبادل اطلاعات بین این دو فرآیند مناسبتر است؟ مفاهیم سیستم عامل
1ارتباط از طریق pipe
2حافظه مشترک (shared memory)
3تبادل پیغام (message passing)
4مدل سرویس گیر - سرویس گر (client-server)
گزینه 2 صحیح است.
فرآیند P1 باید دادهها را مرتب کند و بعد از آن فرآیند P2 داده ها را پردازش میکند. چون سیستم از نوع multitask هست، بهترین روش، استفاده از حافظه مشترک است زیرا سربار کمتری دارد و هسته سیستم عامل را هم درگیر نمیکند.
آسان کدامیک از موارد زیر در یک سیستم real time درست است؟ مفاهیم سیستم عامل
1تنها ملاک درستی انجام یک کار، آن است که در زمان مشخصی انجام شود.
2از حافظه مجازی به دلیل آن که زمان پردازش را طولانی میکند استفاده نمیشود.
3برای آن که بتوان به کارهای با اولویت بالاتر پاسخ داد، یک پردازنده نمیتواند مدت زمان زیادی در kernel باشد.
4اگر یک کار deadline نداشته باشد، ممکن است هیچگاه CPU را در اختیار نگیرد یعنی گرسنگی حاصل شود.
عوامل مختلفی بیانگر درستی انجام یک کار در سیستم های بلادرنگ است بنابراین گزینه 1 که گفته است "تنها ملاک" رد می شود.
برای مثال دو مورد از عوامل عبارتند از:
انجام شدن کار قبل از deadline
استفاده نشدن از حافظه مجازی به دلیل طولانی کردن زمان پردازش
گزینه ۳ نادرست است
گزینه های 2 و 4 درست هستند ولی گزینه 4 پاسخ بهتری است.
دشوار با توجه به بحث Copy-On-Write بین فرآیندهای پدر (Parent) و فرزند (Child) در فراخوان سیستمی fork، در راستای افزایش کارایی، کدام جمله در مورد تقدم و تأخر اجرای این فرآیندها در لحظه ایجاد فرآیند فرزند صحیح است؟ مفاهیم سیستم عامل
1با توجه به آگاهی زمانبند از محتوای (برنامهی) فرآیند پدر، بهتر است فرآیند فرزند زودتر اجرا شود.
2با توجه به آگاهی زمانبند از محتوای (برنامهی) فرآیند پدر، بهتر است فرآیند پدر زودتر اجرا شود.
3با توجه به عدم آگاهی زمان بند از محتوای (برنامهی) فرآیند فرزند، بهتر است فرآیند پدر زودتر اجرا شود.
4با توجه به عدم آگاهی زمانبند از محتوای (برنامهی) فرآیند فرزند، بهتر است فرآیند فرزند زودتر اجرا شود.
بررسی گزینهها:
گزینه 1: در سیستمعامل، زمانبند از محتوای فرآیند پدر اطلاعی ندارد. بنابراین این گزاره نادرست است.
گزینه 2: این گزینه نیز به همان دلیل بیان شده در گزینه 1، نادرست است.
گزینه 3: اگر فرآیند پدر زودتر اجرا شود، از آنجایی که شرایط بحث ما تکنیک Copy-On-Writre است به ازای هر تغییر بایستی یک کپی جدید گرفته شود در این حالت ممکن است به دلیل این تغییرات چندین کپی گرفته شود. حال اگر یک فرزند اجرا شده و سپس به اتمام برسد و فرآیند دیگری جایگزین این فرزند شود، تعداد زیادی کپی بیهوده گرفته شده. بنابراین این گزینه از لحاظ کارایی و بهرهوری بهینه نیست. به همین دلیل این گزینه نادرست است.
گزینه 4: اگر ابتدا فرزند اجرا شود، در این حالت به ازای هر فرزند جدید تنها یک کپی جدید خواهیم داشت و اگر این فرزند پس از اتمام با فرآیند دیگری نیز جایگزین شود. اتلاف ما نسبت به حالت قبل بسیار کمتر است. از طرفی معمولا فرزندان از طرف والد و برای انجام خدماتی به فرآیند والد فراخوانی میشوند و گاهی اوقات حتی ممکن است فرآیند والد منتظر پاسخ فرزند خود بماند و اجرای خود را متوقف کند. بنابراین با توجه به توضیحات داده شده این گزینه هم از نظر کارایی و عملی بودن درست است.
نمونه سوالات فصل زمانبندی درس سیستم عامل
متوسط میانگین زمان انتظار فرآیندهای $P_{\mathrm{1}}$ تا $P_{\mathrm{4}}$ را طبق الگوریتم زمانبندی HRRN به دست آورید.
فرآیندها و زمانبندی پردازندهها
| زمان اجرا |
زمان ورود |
فرآیند |
7
6
4
2 |
0
1
4
7 |
$P_{\mathrm{1}}$ $P_{\mathrm{2}}$ $P_{\mathrm{3}}$ $P_{\mathrm{4}}$ |
|
|
|
15
25/25
35/5
45/75
گزینه ۴ صحیح است.
الگوریتم HRRN (Highest Response Ratio Next) فرآیندی را برای اجرا انتخاب میکند که در لحظه انتخاب بیشترین مقدار $\frac{S+W}{S}$ را داشته باشد (اصطلاحا به این مقدار response ratio گفته میشود). در این فرمول S برابر زمان اجرا و W برابر مدت زمان انتظاری است که فرآیند تا آن لحظه داشته است. توجه شود این الگوریتم non-preemptive است، به این معنا که اگر فرآیندی برای اجرا انتخاب شد تا زمانی که کارش تمام نشود فرآیند دیگر نمیتواند جایش را بگیرد.
در لحظه شروع چون تنها فرآیند P1 وجود دارد این فرآیند اجرا میشود و تا لحظه 7 ادامه مییابد.
در لحظه ۷ همهی ۳ فرآیند دیگر حضور دارند برای هر کدام response ratio را حساب میکنیم:
$S_2 = 6, W_2=7-1=6 \rightarrow R_2 = \frac{6+6}{6} = 2, S_3 = 4, W_3=7-4=3 \rightarrow R_3 = \frac{4+3}{4} = 1.75, S_4 = 2, W_4=7-7=0 \rightarrow R_2 = \frac{2}{2} = 1$
در نتیجه فرآیند بعدی P2 میباشد.
در لحظه ۱۳ دوباره response ratio را برای دو فرآیند باقیمانده حساب میکنیم:
$S_3 = 4, W_3=13-4=9 \rightarrow R_3 = \frac{4+9}{4} = 3.25, S_4 = 2, W_4=13-7=6 \rightarrow R_2 = \frac{2+6}{2} = 4$
فرآیند P4 در این لحظه انتخاب میشود.
در لحظه ۱۵ چون تنها P3 باقیمانده است، انتخاب میشود.
| |
$P_{\mathrm{3}}$ |
$P_{\mathrm{4}}$ |
$P_{\mathrm{2}}$ |
$P_1$ |
0 7 13 15 19
زمانهای انتظار و میانگین:
$W_1 = 0, W_2 = 7 - 1 = 6, W_3 = 15 - 4 = 11, W_4 = 13 - 7 = 6 \rightarrow W_{avg} = \frac{0+6+11+6}{4} = \frac{23}{4} = 5.75$
متوسط اطلاعات چهار فرآیند در یک سیستم در زیر آمده است. اگر از الگوریتم Round Robin (با برش زمانی 3 میلیثانیه) و زمان تعویض متن یک میلیثانیه استفاده نماییم، میانگین زمان پاسخ کدام است؟
فرآیندها و زمانبندی پردازندهها
| زمان اجرا (دقیقه) |
زمان ورود (دقیقه) |
#P |
|
4
6
6
4
|
0
2
2
10
|
${\mathrm{P}}_{\mathrm{1}}$
${\mathrm{P}}_{\mathrm{2}}$
${\mathrm{P}}_{\mathrm{3}}$
${\mathrm{P}}_{\mathrm{4}}$
|
118/5
219
319/5
420
بیایید این سؤال سخت را ذهنی حل کنیم!
چون زمان اجرا به دقیقه و زمان کوانتوم به میلیثانیه است این سؤال را از روش CPU Sharing حل میکنیم. چون کوانتوم 3 میلیثانیه و سوئیچ 1 میلیثانیه است:
اولاً: یک چهارم زمانها هدر رفته و سه چهارم مفید است.
ثانیاً: زمان مفید سه برابر زمانهای هدر رفته است.
از دقیقه 0 تا 2 فقط فرآیند اول اجرا میشود و چون تنها است همه زمانها مفید است و 2 دقیقه از آن کم میشود و 2 دقیقه باقی میماند.
از دقیقه 2 تا 10 سه فرآیند اول تا سوم اجرا میشوند که جمعاً 8 دقیقه است. چون یک چهارم زمانها هدر رفته و سه چهارم مفید است 6 دقیقه مفید به این سه فرآیند میرسد (هر کدام دو دقیقه).
پس فرآیند اول در دقیقه 10 خارج میشود. از دقیقه 10 به بعد سه فرآیند 2 تا 4 هر کدام 4 دقیقه باید اجرا شوند که جمعاً 12 دقیقه میشود. چون زمان مفید سه برابر زمانهای هدر رفته است باید یک سوم این زمان یعنی 4 دقیقه هم هدر برود. این 12 + 4 یعنی 16 دقیقه 0 را با 10 جمع میکنیم و زمان خروج سه فرآیند 2 تا 4 به دست میآید.
$\mathrm{ART\ =\ }\frac{\left(\mathrm{10}-\mathrm{\circ }\right)+\left(\mathrm{26}-\mathrm{2}\right)+\left(\mathrm{26}-\mathrm{2}\right)+\left(\mathrm{26}-\mathrm{10}\right)}{\mathrm{4}}=\frac{\mathrm{74}}{\mathrm{4}}=\mathrm{18/5}$
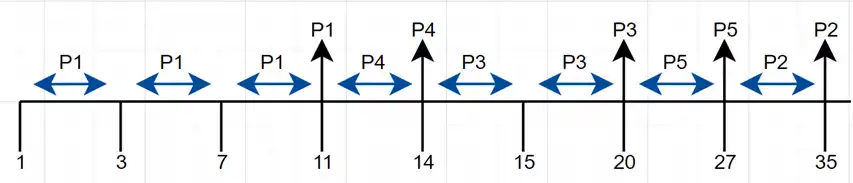
متوسط با توجه به جدول ذیل، متوسط زمان برگشت (Turnaround Time) و زمان انتظار (Waiting Time) پردازههای زیر را به ازای الگوریتم Preemptive Shortest Remaining Job First چه عددی است؟
فرآیندها و زمانبندی پردازندهها
| زمان مورد نیاز برای اجرا |
زمان ورود به سیستم |
پردازه |
| 10 |
1 |
$P_1$ |
| 8 |
3 |
$P_2$ |
| 6 |
7 |
$P_3$ |
| 3 |
11 |
$P_4$ |
| 7 |
15 |
$P_5$ |
114 و 6/2
216 و 6/2
314 و 7/2
416 و 7/2
گزینه 3 صحیح است.
در الگوریتم SRJF (Shortest Remaining Job First) اولویت با فرایندی است که زمان اجرای کمتری دارد. توجه کنید که این الگوریتم قبضه شدنی است.
نمودار گانت آن به صورت زیر است:
در زمان 1 تنها فرایند P1 وارد شده است.
میانگین زمان بازگشت فرایندها $=ATT=\frac{\sum^n_1 (\text{زمان}\mathrm{\ }\text{خروج}\mathrm{)-(}\text{زمان}\ ورود)}{n}$
$ATT=\frac{\left(11-1\right)+\left(35-3\right)+\left(20-7\right)+\left(14-11\right)+(27-15)}{5}=14$
میانگین زمان انتظار فرایندها $=AWT=\frac{\sum^n_1{\mathrm{(}\text{زمان}\mathrm{\ }\text{خروج}\mathrm{)-(}\text{زمان}\mathrm{\ }ورود\mathrm{)}-\mathrm{(}\text{زمان}\mathrm{\ }\text{پردازش}\mathrm{)}}}{n}$
$AWT=\frac{\left(11-1-10\right)+\left(35-3-8\right)+\left(20-7-6\right)+\left(14-11-3\right)+(27-15-7)}{5}=7.2$
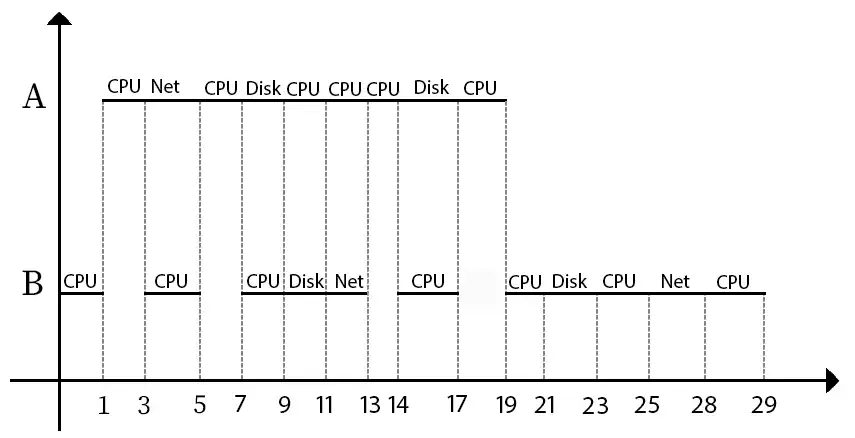
دشوار ۲ پروسس A و B را در نظر بگیرید که از مراحل زیر تشکیل شدهاند. مقادیر CPU نشاندهنده زمان اجرای پروسس بر روی CPU و DISK و NET نشاندهنده عملیات DISK و NETWORK است. عملیات DISKو NETWORK بصورت nonpreemptive انجام میشوند. چنانچه پروسسهای A و B در زمانهای ۱ و $\emptyset$ (صفر) به سیستم رسیده باشند، درصد استفاده از
(Cpu utilization)، Cpu در طول اجرا پروسها کدامیک از گزینههای زیر خواهد بود؟ فرض کنید سیستم سیاست Shortest Job First) SJF Preemptive) را در زمانبندی Cpu اعمال میکند. چنانچه که ۲ پروسس همزمان به Cpu نیاز داشته باشند و زمان Job آنها مساوی باشد، A اول پذیرفته میشود.
فرآیندها و زمانبندی پردازندهها
| A |
|
B |
| Cpu 2 |
|
Cpu 5 |
| NET 2 |
|
Disk 2 |
| Cpu 2 |
|
NET 2 |
| Disk 2 |
|
Cpu 5 |
| Cpu 5 |
|
Disk 2 |
| Disk 3 |
|
Cpu 2 |
| Cpu 2 |
|
NET 3 |
| |
|
Cpu 1 |
1%83
2%90
3%95
4%100
برطبق فرضیات سوال عملیات در Disk و Network به صورت انحصاری (Nonpreemptive) است و در بخش Cpu، سیاست SJF غیرانحصاری (Preemptive) و در شرایط برابر با اولویت بالاتر برای A اعمال میشود.
نمودار تخصیص منابع به این 2 فرآیند به صورت زیر خواهد بود:
$\frac{CPU\ time}{Total\ time}=\frac{24}{29}\approx83%$ = درصد استفاده از CPU
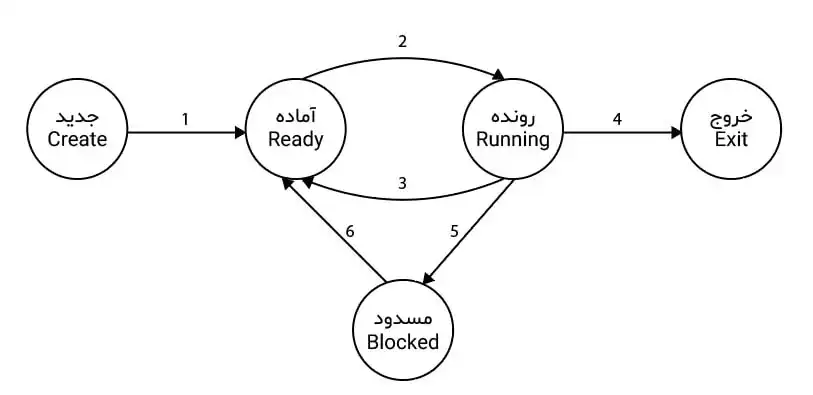
متوسط شکل زیر ۵ حالت اصلی فرآیند (Process) را نمایش میدهد. در این شکل رویدادها (events) با شمارههای ۱ تا ۶ نشان داده شده اند. کدام گزینه رویدادهای صحیح را بیان میکند؟
فرآیندها و زمانبندی پردازندهها
1 رویداد ۶ درخواست آماده بودن است که فرآیند مسدود شده به سیستم عامل می دهد.
رویداد 1 درخواست ایجاد فرایند جدید است که هر فرآیندی میتواند از سیستم عامل درخواست نماید.
رویداد 4 درخواست کاربر برنامه در حال اجرا از سیستم عامل است.
2 رویداد ۴ درخواست کاربر برنامه در حال اجرا از سیستم عامل است.
رویداد ۵ وقفه درخواست ورودی است.
رویداد ۲ عبارت است از: (رویداد ۵) OR (رویداد ۴) OR (رویداد ۳)
3 رویداد ۵ وقفه درخواست ورودی است.
رویداد ۳ وقفه پایان سهم زمانی است.
رویداد ۶ درخواست آماده بودن است که فرآیند مسدود شده به سیستم عامل میدهد.
4 رویداد 1 درخواست ایجاد فرآیند جدید است که هر فرآیندی میتواند از سیستم عامل درخواست نماید.
رویداد ۲ عبارت است از: (رویداد ۵) OR (رویداد ۴) OR (رویداد ۳)
رویداد 3 وقفه پایان سهم زمانی است.
پاسخ گزینه 4 است.
زمانی سیستم عامل فرآیند جدیدی را به حالت رونده (2) میبرد، که فرآیند قبلی توسط یکی از حرکت های 3 یا 4 یا 5 تغییر حالت داده باشد و فرآیند جدید جایگزین آن شود. (رد گزینه های 1 و 3)
واضح است که حرکت شماره 3 وقفه پایان سهم زمانی است و فرآیند از حالت رونده به آماده تغییر میکند. (رد گزینه 2)
آسان جدول زیر، اطلاعات 4 فرایند را نشان می دهد. میانگین زمان برگشت (Turnaround Time) کدام الگوریتم از بقیه کمتر است؟
فرآیندها و زمانبندی پردازندهها
| زمان اجرا (ثانیه) |
زمان ورود به سیستم |
#P |
| 200 |
0 |
P1 |
| 300 |
0 |
P2 |
| 100 |
0 |
P3 |
| 400 |
0 |
P4 |
1FCFS
2SJF
3Round Robin با برش زمانی 10 ثانیه
4Round Robin با برش زمانی 100 ثانیه
این سوال باید ذهنی حل شود. بدیهی است SJF نیازی به محاسبه ندارد و کمترین است (اگرچه در زیر محاسبه شده است).
${ATT}_{FCFS}=\frac{200+500+600+1000}{4}=\frac{2300}{4}=575$
${ATT}_{SJF}=\frac{100+300+600+1000}{4}=\frac{2000}{4}=500$
${ATT}_{RR-100}=\frac{300+500+800+1000}{4}=\frac{2600}{4}=650$
${ATT}_{RR-10}=\frac{390+680+890+1000}{4}=\frac{2960}{4}=740$
دشوار اگر در یک سیستم دو فرآیند $P_\mathrm{1}$ و $ \ P_\mathrm{2}$ داشته باشیم که jobهای فرآیند ${\ P}_\mathrm{1}$ و بهصورت دوره ای هر ۵ ثانیه یکبار و jobهای فرآیند ${\ P}_\mathrm{2}$ بهصورت دورهای هر ۴ ثانیه یکبار به سیستم وارد شوند و زمان اجرای هر job از فرآیند $P_\mathrm{1}$ برابر با ۳ ثانیه و زمان اجرای هر job از فرآیند $P_\mathrm{2}$ برابر با ۱ ثانیه باشد، بهرهوری (utilization) و میانگین زمان پاسخ (Average response time) سیستم به ترتیب چه اعدادی خواهند بود؟ الگوریتم زمانبندی RR با برش زمانی ۱=q است و اگر در لحظه t یک job به سیستم وارد شود و در همین لحظه یک job دیگر پردازنده را ترک کرده و به صف آمادگی (ready queue) منتقل شود، اولویت با job قبلی موجود در سیستم است که تازه پردازنده را رها کرده است. زمان پاسخ، تأخیر بین ورود هر job و اولین زمان در اختیار گرفتن پردازنده توسط آن job است.) فرآیندها و زمانبندی پردازندهها
185% , $\frac{\mathrm{5}}{\mathrm{9}}$
285% , $\frac{\mathrm{1}}{\mathrm{3}}$
390% , $\frac{\mathrm{1}}{\mathrm{3}}$
490% , $\frac{\mathrm{5}}{\mathrm{9}}$
با توجه به اینکه سوال در مورد لحظه شروع $(t=0)$ اطلاعاتی نداده است. بنابراین ما فرض را بر این میگذاریم که در لحظه شروع هر دو این jobها وارد سیستم شدهاند و اولویت اجرا را هم به فرآیند $P_1$ اختصاص میدهیم. بنابراین با توجه به توضیحات داده شده نمودار گانت سوال به صورت زیر خواهد بود:
بنابراین بهرهوری CPU برابر است با:
\[\mathrm{Utilization\ =\ }\mathrm{1\ -\ }\frac{\text{زمان}\mathrm{\ }\text{بیکاری}\mathrm{\ }\text{پردازنده}}{\text{زمان}\mathrm{\ }\text{یک}\mathrm{\ }\text{تناوب}}=\frac{17}{20}=85\%\]
و با توجه به تعریف ارائه شده در متن سوال برای زمان پاسخ و همچنین زمانهای پاسخ jobهای دو فرآیند که در زیر آورده شدهاند. میانگین زمان پاسخ سیستم برابر است با:
زمانهای پاسخ برای 4 job وارد شده فرآیند $P_1$ به ترتیب برابر است با: 0,0,0,0
زمانهای پاسخ برای 5 job وارد شده فرآیند $P_2$ به ترتیب برابر است با: 1,0,0,1,1
و میانگین زمان پاسخ سیستم برابر است با: $\frac{1+1+1}{9}=\frac{3}{9}=\frac{1}{3}$
آسان در سیستمهای تعبیه شده بیدرنگ سخت که پاسخ در زمانی مشخص باید تضمین شود، کدام روش نگاشت ریسمانهای کاربر به ریسمانهای سیستمی، مناسب است؟ فرآیندها و زمانبندی پردازندهها
1یک به یک
2چند به یک
3چند به چند
4دوسطحی
پاسخ گزینه 4 است.
نخهای دوسطحی نوع خاصی از سیستمهای چندنخی چند به چند هستند که با روشهایی مانند LWP پیادهسازی میشود. این مدل نخها برای سیستمهای بیدرنگ مناسب است.
آسان کدام مورد باعث افزایش درجه توازی اجرای برنامهها نمیشود؟ فرآیندها و زمانبندی پردازندهها
1استفاده از مدل چندنخی یک به یک به جای مدل چندنخی چند به یک
2استفاده از مدل چندنخی چند به چند به جای مدل چندنخی چند به یک
3استفاده از برنامهنویسی آسنکرون به جای سنکرون
4استفاده از پارتیشنبندی ایستا به جای پویا در مدیریت حافظه
1) در مدل چندنخی یک به یک (سطح هسته) درجه توازی به تعداد نخ سطح کاربر است و در مدل چندنخی چند به یک (سطح کاربر) اصلاً توازی نداریم (درجه 1).
2) در مدل چندنخی چند به چند (مثل LWP) درجه چندبرنامگی به تعداد LWP است و در مدل چندنخی چند به یک (سطح کاربر) اصلاً توازی نداریم (درجه 1).
3) استفاده از برنامهنویسی آسنکرون (ناهمگام) به دلیل فراخوانهای سیستمی غیر مسدودکننده توازی را افزایش میدهد.
4) استفاده از پارتیشنبندی ایستا به جای پویا در مدیریت حافظه توازی را کاهش میدهد.
متوسط کدام عبارت دربارۀ نخها درست نیست؟ فرآیندها و زمانبندی پردازندهها
1نخهای یک پردازه، دارای برنامۀ مخصوص به خود هستند.
2نخهای یک پردازه، از فضای heap مشترک استفاده میکنند.
3نخهای یک پردازه، از فضای آدرس یکسان استفاده میکنند.
4نخهای یک پردازه، از یک پشته مشترک استفاده میکنند.
پاسخ گزینه 4 است.
نخهای یک پردازه از heap و فضای آدرس مشترک استفاده میکنند اما دارای برنامه و Stack مخصوص به خود هستند.
نمونه سوالات فصل انحصار متقابل درس سیستم عامل
متوسط در مسأله غذا خوردن فیلسوفها، 5 فیلسوف دور میزی نشستهاند و بین هر دو فیلسوف یک چنگال قرار دارد و هر فیلسوف برای غذا خوردن به دو چنگال نیاز دارد. فرض کنید دو نوع فیلسوف داریم: فیلسوفان چپ دست که ابتدا چنگال سمت چپ خود را بر میدارند و فیلسوفان راست دست که ابتدا چنگال سمت راست خود را بر میدارند. فرض کنید که در بین 5 فیلسوف، حداقل یک فیلسوف چپ دست و یک فیلسوف راست دست موجود است. با توجه به توضیحات فوق، کدام عبارت صحیح است؟ انحصار متقابل
1اگر دو تا فیلسوف چپ دست یا دو فیلسوف راست دست در کنار هم باشند بن بست رخ میدهد.
2مستقل از نحوه نشستن فیلسوفان چپ دست و راست دست، هیچگاه بن بست رخ نمیدهد.
3اگر از یک نوع فیلسوف، دو تا و از نوع دیگر سه تا داشته باشیم بن بست رخ میدهد.
4اگر همگی فیلسوفها با هم همزمان اولین چنگالها را بردارند، بن بست رخ میدهد.
در مسئله غذا خوردن فیلسوفها در 2 صورت بنبست رخ میدهد:
1- همه فیلسوفها همزمان راست دست باشند و چنگال سمت راست خود را بردارند.
2- همه فیلسوفها همزمان چپ دست باشند و چنگال سمت چپ خود را بردارند.
در این سوال چون حداقل یک فیلسوف چپدست و یک فیلسوف راستدست داریم بنابراین حالتی را نمیتوان یافت که همه فیلسوفان فقط یک چنگال داشته باشند، در هر صورت حداقل 1 چنگال بعد از برداشتن همه چنگالها بر روی میز باقی میماند که فیلسوف مورد نظر میتواند این چنگال را برداشته و بعد از خوردن غذا این منابع را آزاد کند. بنابراین بنبستی در این سیستم رخ نمیدهد.
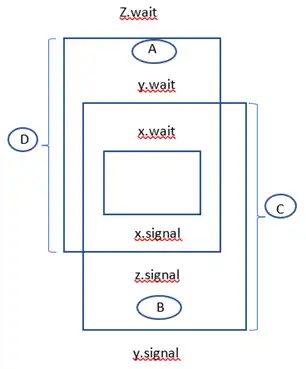
دشوار سه سمافور با مقدار اولیه $\mathrm{x\ =\ 1}$، $\mathrm{y\ =\ 5}$ و $\mathrm{z\ =\ 10}$ در نظر بگیرید. قطعه کد زیر توسط 20 پردازه (Process) اجرا میشود، حداکثر طول صفی که برای سمافور y تشکیل میشود، چقدر است؟
انحصار متقابل
…
z.wait();
…
y.wait();
…
x.wait();
…
x.signal();
…
z.signal();
…
y.signal();
14
25
39
410
گزینه 4 صحیح است.
از دید سمافور y در ناحیه C و به تبع آن در ناحیه B حداکثر 5 فرایند (برابر با مقدار اولیه سمافور y) میتوانند حضور داشته باشند. فرض کنید الان این 5 فرایند در ناحیه B حضور دارند. پس ورود فرایند جدید به ناحیه C غیرممکن است. از طرفی قسمت زیر ناحیه A از ناحیه D خالی است. (وگرنه تعداد فرایندهای درون ناحیه C بیشتر از 5 میشود). حال از دید سمافور 10 ،z فرایند جدید میتوانند وارد ناحیه A شوند. اگر این 10 فرایند بخواهند وارد ناحیه C شوند همگی در صف سمافور Y میخوابند.
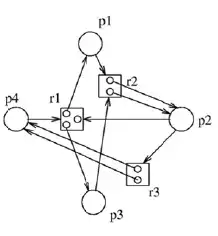
دشوار کدام مورد سیستمعامل را مجبور میکند دستورات $s_4،~ s_3، ~ s_2،~ s_1$ که به ترتیب در پردازههای همروند $p_4، ~p_3، ~ p_2، ~p_1$ قرار دارند به همان ترتیب $s_4،~ s_3، ~ s_2،~ s_1$ اجرا کند؟
انحصار متقابل
(مقدار اولیه سمافورها ∘ = a = b = c)
1
| $P_4$ |
$P_3$ |
$P_2$ |
$P_1$ |
|
Wait(c)
$S_4$
|
Wait(b)
$S_3$
Signal(c)
|
Wait(a)
$S_2$
Signal(b)
|
$S_1$
Signal(a)
|
2
| $P_4$ |
$P_3$ |
$P_2$ |
$P_1$ |
|
Wait(a)
Wait(b)
$S_4$
|
Wait(a)
$S_3$
Signal(b)
|
Wait(b)
$S_2$
Signal(a)
|
$S_1$
Signal(a)
Signal(b)
|
3
| $P_4$ |
$P_3$ |
$P_2$ |
$P_1$ |
|
Wait(a)
Wait(a)
Wait(a)
$S_4$
Signal(a)
Signal(a)
Signal(a)
Signal(a)
|
Wait(a)
Wait(a)
$S_3$
Signal(a)
Signal(a)
Signal(a)
|
Wait(a)
$S_2$
Signal(a)
Signal(a)
|
$S_1$
Signal(a)
|
4
| $P_4$ |
$P_3$ |
$P_2$ |
$P_1$ |
|
Wait(a)
Signal(b)
Signal(c)
$S_4$
|
Wait(a)
Signal(b)
$S_3$
Signal(c)
|
Wait(a)
$S_2$
Signal(b)
Signal(c)
|
$S_1$
Wait(a)
Signal(b)
Signal(c)
|
گزینه 1 صحیح است.
با توجه به مقادیر اولیه سمافورها ($a=b=c=0$) فقط دستور $S_1$ در ابتدا میتواند اجرا شود.
بررسی گزینه 1: این گزینه صحیح است. زیرا اجرای فرایندهای $P_3$ ، $P_2$ ، $P_1$ و $P_4$ فقط منجر به اجرای دستورات $S_3$ ، $S_2$ ، $S_1$ و $S_4$ به همین ترتیب میشود.
علت رد گزینه 2: میتوان سناریویی را پیدا کرد که اجرای فرایندهای $P_3$ ، $P_2$ ، $P_1$ و $P_4$ منجر به اجرای دستورات به ترتیب $S_2$ ، $S_3$ ، $S_1$ و $S_4$ شود. (در صورتی که فرایندها به این ترتیب اجرا شوند: $P_2$ ، $P_3 $ ، $P_1$ و $P_4$)
علت رد گزینه 3: در این گزینه اجرای فرایندهای $P_3$ ، $P_2$ ، $P_1$ و $P_4$ میتواند منجر به اجرای دستورات $S_3$ ، $S_2$ ، $S_1$ و $S_4$ به همین ترتیب شود. اما سناریوی دیگری را میتوان یافت که تمامی فرایندها پس از اجرای فرایند 1 به خواب ابدی بروند. (در صورتی که فرایند ها به این ترتیب اجرا شوند: $P_2$ ، $P_3$ ، $P_1$ و $P_4$)
علت رد گزینه 4: این گزینه نادرست است زیرا اجرای فرایندهای $P_3$ ، $P_2$ ، $P_1$ و $P_4$ منجر به خواب ابدی میشود.
دشوار اگر دو پروسس $P1$ و $P2$ آمده در زیر به طور همروند اجرا شوند، کدامیک در موارد ذیل صحیح است؟
انحصار متقابل
$N1,~N2:integer:=0;$
$task~body~P2~is:$$~~~$
$begin$$~~~$
$loop$$~~~~~~~$
$Non-Critical-Section-2;$$~~~~~~~~~~$
$N2:=1;$$~~~~~~~~~~$
$N2:=N1+1;$$~~~~~~~~~~$
$loop~exit~when~N1=0~or~N2~<N1;end~loop;$$~~~~~~~~~~$
$Critical-Section-2;$$~~~~~~~~~~$
$end~loop;$$~~~~~~$
$end~P2;$
$task~body~P1~is:$
$begin$
$loop$$~~~~$
$Non-Critical-Section-1;$$~~~~~~~$
$N1:=1;$$~~~~~~~$
$N1:=N2+1;$$~~~~~~~$
$loop~exit~when~N2=0~or~N1~<=N2;end~loop;$$~~~~~~~$
$Critical-Section-1;$$~~~~~~~$
$end~loop;$$~~~$
$end~P1;$
1انحصار متقابل تأمین میشود.
2انحصار متقابل تأمین نمیشود.
3انحصار متقابل تأمین میشود ولی امکان بنبست وجود دارد.
4انحصار متقابل تأمین میشود ولی امکان گرسنگی وجود دارد.
گزینه 1 صحیح است.
برای حل این سوال، سناریو های مختلف برای ورود به ناحیه ی بحرانی را بررسی می کنیم:
سناریو اول:
فرض کنید در فرآیند P1، متغیر N1=1 شود و بعد فرآیند P2 اجرا شود و متغیر N2=1 شود. مجددا پردازنده را به فرآیند P1 می دهیم و N1=N2+1=1+1=2 شود. حال ادامه فرآیند P2 را اجرا می کنیم و N2= N1+1=2+1=3 شود. در ادامه شرط خروج از حلقه در فرآیند P2 رعایت نمی شود و در نتیجه نمی تواند وارد ناحیه بحرانی شود ولی فرآیند دیگر می تواند از حلقه خارج شود و وارد ناحیه بحرانی شود. پس در این سناریو شرط انحصار متقابل تامین می شود.
سناریو دوم:
در فرآیند P1، متغیر N1=1 می شود و در ادامه این فرآیند، مقدار آن تغییر می کند و N1=N2+1=0+1=1 می شود. حال پردازنده به فرآیند P2 اختصاص می دهیم و N2=1 می شود و در ادامه این متغیر تغییر می کند N2=1+1=2 می شود. فرآیند P2 موفق به خروج از حلقه خود نمی شود و نمی تواند وارد ناحیه بحرانی شود ولی اگر پردازنده به P1 اختصاص داده شود، شرط خروج از حلقه آن رعایت شده و وارد ناحیه بحرانی می شود. در نتیجه مانند سناریو قبل، شرط انحصار متقابل تامین می شود.
سناریو سوم:
فرآیند P1 اجرا شود، N1=1 شود و بعد پردازنده به فرآیند P2 اختصاص داده شود، مقدار N2=1 شود، مجددا این متغیر، تغییر کند و N2=N1+1=1+1=2 شود و بعد ادامه فرآیند P1 اجرا شود، و N1= N2+1=2+1=3 می شود. فرآیند P1 پشت حلقه گیر می کند ولی اگر ادامه P2 اجرا شود، از حلقه خارج شده و وارد ناحیه بحرانی می شود. پس شرط انحصار متقابل تامین می شود.
سناریو چهارم:
فرآیند P1 اجرا می شود و در نهایت N1=1 می شود و چون فرآیند P2 را اجرا نکردیم، N2=0 است و این فرآیند می تواند از حلقه عبور کند و وارد ناحیه بحرانی شود. اکنون فرآیند P2 را شروع می کنیم و N2=1 می شود و در ادامه N2=N1+1=1+1=2 می شود و پشت حلقه گیر می کند. پس شرط انحصار متقابل تامین می شود.
با توجه به بررسی هر حالت ممکن، متوجه می شویم که امکان وقوع بن بست و گرسنگی وجود ندارد.
دشوار کد زیر برای حل مشکل تولید کننده / مصرف کننده پیشنهاد شده است. count یک متغیر سراسری و N تعداد خانه های بافر است،کدام گزینه صحیح است؟
انحصار متقابل
void consumer (void)
{
while(TRUE)
{if(count == 0)sleep() ; else{ remove - item() ; count = count - 1 ; if(count == N - 1) wakeup(producer) ; } } }
void producer (void)
{
while(TRUE)
{produce - item ; if (count ==N) sleep() ; else{ enter -- item(); count = count + 1 ; if (count ==1) wakeup(consumer) ; } } }
1امکان دسترسی همزمان توسط تولید کننده و مصرف کننده به بافر وجود دارد ولی امکان بنبست وجود ندارد.
2امکان دسترسی همزمان توسط تولیدکننده و مصرفکننده به بافر وجود دارد و امکان بنبست (dead lock) نیز وجود دارد.
3امکان نوشتن در بافر پر وجود ندارد و انحصار متقابل تأمین میشود.
4امکان خواندن از بافر خالی وجود ندارد، انحصار متقابل تأمین نمیشود و امکان وقوع بنبست وجود ندارد.
حالتی را فرض میکنیم که در آن مقدار متغیر count برابر عددی بین 1 و N باشد. در این حالت اگر ابتدا مصرفکننده اجرا شود به علت اینکه مقدار count مخالف صفر است وارد ناحیه بحرانی میشود حال اگر در این لحظه CPU از مصرفکننده گرفته شده و به تولیدکننده داده شود به علت اینکه مقدار count برابر N نیست تولیدکننده نیز وارد ناحیه بحرانی میشود. بنابراین در راهحل بیان شده امکان دسترسی همزمان تولیدکننده و مصرفکننده به بافر وجود دارد.
حالت دیگری را تصور کنید که در آن مقدار متغیر count برابر 0 باشد در این حالت اگر ابتدا مصرفکننده اجرا شود و در بخش if بالایی کد مصرف کننده بعد از اینکه مقدار count که برابر صفر است خوانده شده و قبل از بررسی شرط حلقه، CPU از مصرفکننده گرفته شده و به تولیدکننده داده شود. تولیدکننده پس از تولید یک item مقدار count را یک واحد افزایش داده و مقدار جدید count برابر 1 خواهد شد بنابراین شرط if انتهایی تولیدکننده برقرار شده و یک wakeup به مصرفکننده داده میشود ولی از آنجایی که مصرفکننده هنوز به خواب نرفته است این wakeup از دست میرود. حال اگر CPU دوباره به مصرفکننده داده شود، مصرفکننده مقدار قبلی خوانده شده متغیر count یعنی صفر را دارد بنابراین شرط if برقرار شده و به خواب میرود. با به خواب رفتن مصرفکننده، تولید کننده آنقدر اجرا میشود تا بافر را پر کند و خودش نیز به خواب رود. بنابراین هم مصرفکننده و هم تولیدکننده به خوابرفته و راهحل دچار بنبست میشود.
بنابراین گزینه 2 پاسخ سوال ما خواهد بود.
متوسط در خصوص الگوریتم زیر، که برای پیادهسازی ناحیه بحرانی بین دو پردازه i و j ارائه شده است، کدام مورد درست است؟ (الگوریتم برای پردازه i است و مشابه آن برای j هم وجود دارد.)
انحصار متقابل
While (true) {
Flag [i] = True
Turn = j
While (Flag[i] && Turn == j)
/* critical Section */
Flag [i] = false
}
1انحصار متقابل دارد، پیشرفت ندارد، انتظار محدود دارد.
2انحصار متقابل دارد، پیشرفت دارد، انتظار محدود ندارد.
3انحصار متقابل ندارد، پیشرفت دارد، انتظار محدود ندارد.
4انحصار متقابل ندارد، پیشرفت ندارد، انتظار محدود ندارد.
شرط پیشرفت: فرض کنید فرایند i فلگ خود را true میکند ($flag\left[i\right]=true$) و $turn=j$ میشود. در همین لحظه به فرایند j سوییچ میشود و این فرایند نیز فلگ خود را true میکند ($flag\left[j\right]=true$) و $turn=i$ میشود. در این لحظه فرایند j وارد ناحیه بحرانی خود میشود(شرط حلقه true میشود) و هنگام خروج از ناحیه بحرانی فلگ خودرا false میکند. اما فرایند i به دلیل اینکه شرط حلقه برای آن true نمیشود نمیتواند وارد ناحیه بحرانی خود شود. بنابراین فرایند j در ناحیه بحرانی نیست اما مانع ورود فرایند i به ناحیه بحرانی میشود. پس شرط پیشرفت را ندارد.
شرط انحصار متقابل: با توجه به اینکه در این الگوریتم از متغیر اولویت (turn) استفاده شده است بنابراین انحصار متقابل در این الگوریتم رعایت میشود و این دو فرایند همزمان نمیتوانند وارد ناحیه بحرانی شوند. پس شرط انحصار متقابل را دارد.
شرط انتظار محدود: با توجه به اینکه یک فرآیند بعد از خروج از ناحیه بحرانی نمیتواند دوباره وارد ناحیه بحرانی خود شود (به دلیل وجود متغیر turn که مربوط به فرآیند دیگری است) پس این الگوریتم شرط انتظار محدود را دارد.
این الگوریتم انحصار متقابل را دارد، پیشرفت ندارد، انتظار محدود دارد.
نمونه سوالات فصل بن بست درس سیستم عامل
آسان فرض کنید یک سیستم با 4 فرآیند و 3منبع به صورت گراف زیر داشته باشیم:
بن بست
در این صورت کدامیک از گزینههای زیر صحیح است؟
1در این سیستم چرخه انتظاری وجود ندارد و در آن بنبست نیز وجود ندارد.
2در این سیستم دو چرخه انتظار وجود دارد ولی در آن بنبست وجود ندارد.
3در این سیستم سه چرخه انتظار وجود دارد ولی در آن بنبست وجود ندارد.
4در این سیستم بنبست رخ داده است.
در این سیستم چرخه انتظار وجود ندارد زیرا پردازه $P_{\mathrm{4}}$ منابع مورد نیاز خود را میتواند در دسترس داشته باشد و منتظر آزادسازی آن توسط پردازههای دیگر نمیباشد. سایر پردازهها نیز بدون $P_{\mathrm{4}}$ چرخه انتظاری را ایجاد نمیکنند.
دشوار سيستمي متشكل از 5 فرآيند و 3 منبع در حالت زير قرار دارد:
بن بست
| $R_3$ |
$R_2$ |
$R_1$ |
$R_\circ$ |
| $2$ |
$4$ |
$3$ |
$5$ |
كل موجودي اوليه
| $R_3$ |
$R_2$ |
$R_1$ |
$R_\circ$ |
| $\circ$ |
$\circ$ |
$1$ |
$1$ |
| $2$ |
$1$ |
$1$ |
$2$ |
| $\circ$ |
$\circ$ |
$1$ |
$3$ |
| $\circ$ |
$1$ |
$\circ$ |
$\circ$ |
| $\circ$ |
$1$ |
$1$ |
$2$ |
منابع هنوز مورد نياز
| $R_3$ |
$R_2$ |
$R_1$ |
$R_\circ$ |
|
| $1$ |
$1$ |
$\circ$ |
$3$ |
$P_\circ$ |
| $\circ$ |
$\circ$ |
$1$ |
$\circ$ |
$P_1$ |
| $\circ$ |
$1$ |
$1$ |
$\circ$ |
$P_2$ |
| $1$ |
$\circ$ |
$1$ |
$1$ |
$P_3$ |
| $\circ$ |
$\circ$ |
$\circ$ |
$\circ$ |
$P_4$ |
منابع تخصيص يافته
تعداد مسيرهاي امن را بيابيد:
16 مسير
28 مسير
310 مسير
412 مسير
متوسط مشخصات 5 فرآیند به شرح زیر است:
بن بست
|
Free Resources
|
| $R_3$ |
$R_2$ |
$R_1$ |
|
| 9 |
6 |
8 |
$P_0$ |
| 2 |
10 |
9 |
$P_1$ |
| 8 |
11 |
9 |
$P_2$ |
| 9 |
7 |
6 |
$P_3$ |
| 9 |
8 |
4 |
$P_4$ |
Max
|
| $R_3$ |
$R_2$ |
$R_1$ |
|
| 6 |
4 |
5 |
$P_0$ |
| 2 |
5 |
7 |
$P_1$ |
| 5 |
1 |
6 |
$P_2$ |
| 7 |
4 |
2 |
$P_3$ |
| 3 |
5 |
4 |
$P_4$ |
Allocation
|
در صورت اجابت کردن کدام درخواست، سیستم به حالت ناامن خواهد رفت؟
1$P_1$ درخواست 2 عدد $R_1$ بدهد.
2$P_0$ درخواست 3 عدد $R_1$ بدهد.
3$P_2$ درخواست 4 عدد $R_2$ بدهد.
4$P_3$ درخواست 2 عدد $R_3$ بدهد.
گزینه 3 صحیح است.
در صورت سوال به ما ماتریس نیاز و بردار منابع اولیه را نداده است بنابراین باید ابتدا این دو را محاسبه کنیم. می دانیم که ماتریس Need از تفاضل ماتریس Max و ماتریس Allocation بدست میآید. پس:
| R3 |
R2 |
R1 |
|
| 3 |
2 |
3 |
P0 |
| 0 |
5 |
2 |
P1 |
| 3 |
10 |
3 |
P2 |
| 2 |
3 |
4 |
P3 |
| 6 |
3 |
0 |
P4 |
همچنین بردار منابع اولیه از جمع منابع اختصاص یافته به فرآیندها با منابع آزاد به دست میآید:
|
منابع اولیه
|
R1 = 4+5+7+6+2+4=28
R2 = 5+4+5+1+4+5=24
R3 = 6+6+2+5+7+3=29 |
طبق الگوریتم بانکداری، سیستم قبل از اجابت درخواستها دارای دنباله امن P0,P1,P2,P3,P4 (از چپ به راست) است. بنابراین سیستم در حالت امن قرار دارد.
بررسی گزینه اول: در صورت اجابت گزینه اول ماتریس نیاز و بردار منابع آزاد به صورت زیر تغییر میکنند:
|
|
| R3 |
R2 |
R1 |
|
| 3 |
2 |
3 |
P0 |
| 0 |
5 |
0 |
P1 |
| 3 |
10 |
3 |
P2 |
| 2 |
3 |
4 |
P3 |
| 6 |
3 |
0 |
P4 |
نیاز
|
در این شرایط طبق بردار منابع آزاد، فرآیند P1 یا P4 قابل اجرا هستند و در نهایت میتوان حداقل یک دنباله امن برای این گزینه ارائه داد در نتیجه اجابت این گزینه باعث ناامن شدن سیستم نمیشود.
دنباله امن: P1,P0,P2,P3,P4 (از چپ به راست)
بررسی گزینه دوم: این گزینه مانند گزینه اول رد میشود. دنباله امن: P0,P1,P2,P3,P4
بررسی گزینه چهارم: این گزینه هم مانند گزینه اول و دوم رد میشود. دنباله امن: P0,P1,P2,P3,P4
بررسی گزینه سوم: در صورت اجابت گزینه سوم شرایط ماتریسها به صورت زیر میشود:
|
منابع آزاد
|
| R3 |
R2 |
R1 |
|
| 3 |
2 |
3 |
P0
|
| 0 |
5 |
2 |
P1 |
| 3 |
6 |
3 |
P2 |
| 2 |
3 |
4 |
P3 |
| 6 |
3 |
0 |
P4 |
|
با توجه به ماتریس منابع آزاد، متوجه میشویم که منابع کافی برای اجرا هیچ کدام از فرآیندها موجود نیست. بنابراین دنباله امنی برای این گزینه پیدا نمیشود و سیستم در این شرایط در حالت ناامن قرار میگیرد.
نکته: ناامنی به معنی وقوع بن بست به صورت حتمی نیست، بلکه به معنی احتمال وقوع بن بست است. بنابراین الگوریتم بانکداری احتمال وقوع بن بست را تشخیص میدهد.
متوسط در سیستمی با چهار پردازه (Process) و سه نوع منبع (Resource)، وضعیت تخصیص منابع و درخواستهای داده شده، به شکل زیر است:
بن بست
درخواست فعلی
| C |
B |
A |
| 1 |
0 |
0 |
| 0 |
0 |
1 |
| 0 |
0 |
1 |
| 1 |
0 |
0 |
تخصیص یافته
| C |
B |
A |
|
| 0 |
1 |
0 |
$P_0$ |
| 3 |
0 |
2 |
$P_1$ |
| 0 |
2 |
3 |
$P_2$ |
| 2 |
0 |
0 |
$P_3$ |
کدام گزینه نشاندهندهی این وضعیت است؟
1امن است.
2بنبست نیست.
3فرآیندهای ${\mathrm{P}}_{\mathrm{1}}$ و ${\mathrm{P}}_{\mathrm{2}}$ دچار بنبست شدهاند.
4ناامن است.
این مسئله الگوریتم بانکدار نیست و به امن و ناامنی سیستم ربطی ندارد و گزینههای 1 و 4 با یک نگاه حذف میشوند.
درخواست فعلی
| C |
B |
A |
| 1 |
0 |
0 |
| 0 |
0 |
1 |
| 0 |
0 |
1 |
| 1 |
0 |
0 |
تخصیصیافته
| C |
B |
A |
|
| 0 |
1 |
0 |
${\mathrm{P}}_{\mathrm{\circ }\mathrm{\ }}$ |
| 3 |
0 |
2 |
${\mathrm{P}}_{\mathrm{1}}$ |
| 0 |
2 |
3 |
${\mathrm{P}}_{\mathrm{1}}$ |
| 2 |
0 |
0 |
${\mathrm{P}}_{\mathrm{1}}$ |
| 5 |
3 |
5 |
$P$ |
با بردار $\mathrm{A\ =}\left(\mathrm{\circ },\mathrm{\ }\mathrm{1}\mathrm{,\ }\mathrm{2}\right)$ فقط درخواستهای ${\mathrm{P}}_{\mathrm{\circ }}$ و ${\mathrm{P}}_{\mathrm{3}}$ قابل انجام هستند و با اجرای این دو فرآیند هیچ منبع A آزاد نمیشود. بنابراین ${\mathrm{P}}_{\mathrm{1}}$ و ${\mathrm{P}}_{\mathrm{2}}$ در بنبست هستند.
نمونه سوالات فصل دیسک و مدیریت ورودی و خروجی درس سیستم عامل
دشوار در یک دیسک 16050 سیلندر به همراه 8 صفحه وجود دارد و در هر شیار تعداد 127 سکتور قرار گرفته است. اگر زمان حرکت بین دو شیار همسایه برابر 4 میلی ثانیه باشد و سرعت چرخش دیسک برابر RPM 6000 در نظر گرفته شود. زمان خواندن کل دیسک تقریباً چقدر است؟ (وضعیت هد جاری شیار صفر است) مدیریت I/O و دیسک
122.5 دقیقه
230.6 دقیقه
325.8 دقیقه
418.4 دقیقه
در این مسئله باید ابتدا زمان خواندن شیارها محاسبه گردد. سپس کل زمان حرکت هد محاسبه شود و در نهایت مجموع زمانها محاسبه شود. با توجه بهRPM 6000 میتوان نتیجه گرفت هر شیار در زمان معادل 10 میلی ثانیه خوانده میشود.
تعداد شیار = 16050 * 8 * 10 = 1284000 = 1284 ثانیه
کل زمان جستجو = 16049 * 4 = 64196 = 64 ثانیه
کل زمان = 1284 + 64 = 1348 ثانیه = 22.46 دقیقه
متوسط دیسکی با شیارهای ۰ تا ۲۵۵ را در نظر بگیرید که در آن بازوی دیسک در شیار ۴۵ باشد و در جهت افزایش شماره شیارها حرکت میکند. در این دیسک درخواست شیار به ترتیب از راست به چپ ۴۰، ۶۷، ۱۱، ۲۴۰ و ۸۷ میرسند. کدام گزینه درباره روش و تعداد شیارهایی که بازوی دیسک طی میکند، نادرست است؟ فرض کنید Scan از دو طرف تا انتها میرود. مدیریت I/O و دیسک
1505 , C - scan
2453 , C - look
3456 , scan
4424 , look
$C-\ scan:\ \mathrm{45}{{\stackrel{\ \ \ \mathrm{22\ \ \ }}{\longrightarrow}}}\mathrm{67}\stackrel{\ \ \ \mathrm{20\ \ \ }}{\longrightarrow}\mathrm{87}\stackrel{\ \ \ \mathrm{153\ \ \ }}{\longrightarrow}\mathrm{\ 240}\stackrel{\ \ \ \mathrm{15\ \ \ }}{\longrightarrow}\mathrm{255}\stackrel{\ \ \ \mathrm{225\ \ \ }}{\longrightarrow}0\stackrel{\ \ \ \mathrm{11\ \ \ }}{\longrightarrow}\mathrm{11}\stackrel{\ \ \ \mathrm{29\ \ \ }}{\longrightarrow}\mathrm{40}$
$T=\mathrm{22}\mathrm{+}\mathrm{20}\mathrm{+}\mathrm{153}\mathrm{+}\mathrm{15}\mathrm{+}\mathrm{255}\mathrm{+}\mathrm{11}\mathrm{+}\mathrm{29}\mathrm{=}\mathrm{505}$
$or\ T=(\mathrm{255}\mathrm{-}\mathrm{45})+(\mathrm{255}\mathrm{-}0)+(\mathrm{40}\mathrm{-}0)=\mathrm{210}+\mathrm{255}+\mathrm{40}\mathrm{=}\mathrm{505}$
$C-\ look:\ \mathrm{45}{{\stackrel{\ \ \ \mathrm{22\ \ \ }}{\longrightarrow}}}\mathrm{67}\stackrel{\ \ \ \mathrm{20\ \ \ }}{\longrightarrow}\mathrm{87}\stackrel{\ \ \ \mathrm{153\ \ \ }}{\longrightarrow}\mathrm{\ 240}\stackrel{\ \ \ \mathrm{229\ \ \ }}{\longrightarrow}\mathrm{11}\stackrel{\ \ \ \mathrm{29\ \ \ }}{\longrightarrow}\mathrm{40}$
$T=\mathrm{22}\mathrm{+}\mathrm{20}\mathrm{+}\mathrm{153}\mathrm{+}\mathrm{229}\mathrm{+}\mathrm{29}\mathrm{=}\mathrm{453}$
$or\ T=(\mathrm{240}\mathrm{-}\mathrm{45})+(\mathrm{240}\mathrm{-}\mathrm{11})+\mathrm{29}=\mathrm{195}+\mathrm{229}+\mathrm{29}\mathrm{=}\mathrm{453}$
$Scan:\ \mathrm{45}{{\stackrel{\ \ \ \mathrm{22\ \ \ }}{\longrightarrow}}}\mathrm{67}\stackrel{\ \ \ \mathrm{20\ \ \ }}{\longrightarrow}\mathrm{87}\stackrel{\ \ \ \mathrm{153\ \ \ }}{\longrightarrow}\mathrm{\ 240}\stackrel{\ \ \ \mathrm{15\ \ \ }}{\longrightarrow}\mathrm{255}\stackrel{\ \ \ \mathrm{215\ \ \ }}{\longrightarrow}\mathrm{40}\stackrel{\ \ \ \mathrm{29\ \ \ }}{\longrightarrow}\mathrm{11}$
$T=\mathrm{22}\mathrm{+}\mathrm{20}\mathrm{+}\mathrm{153}\mathrm{+}\mathrm{15}\mathrm{+}\mathrm{215}\mathrm{+}\mathrm{29}\mathrm{=}\mathrm{454}$
$or\ T=(\mathrm{255}\mathrm{-}\mathrm{45})+(\mathrm{255}\mathrm{-}\mathrm{11})=\mathrm{210}+\mathrm{244}\mathrm{=}\mathrm{454}$
$Look:\ \mathrm{45}{{\stackrel{\ \ \ \mathrm{22\ \ \ }}{\longrightarrow}}}\mathrm{67}\stackrel{\ \ \ \mathrm{20\ \ \ }}{\longrightarrow}\mathrm{87}\stackrel{\ \ \ \mathrm{153\ \ \ }}{\longrightarrow}\mathrm{\ 240}\stackrel{\ \ \ \mathrm{200\ \ \ }}{\longrightarrow}\mathrm{40}\stackrel{\ \ \ \mathrm{29\ \ \ }}{\longrightarrow}\mathrm{11}$
$T=\mathrm{22}\mathrm{+}\mathrm{20}\mathrm{+}\mathrm{153}\mathrm{+}\mathrm{200}\mathrm{+}\mathrm{29}\mathrm{=}\mathrm{424}$
$or\ T=(\mathrm{240}\mathrm{-}\mathrm{45})+(\mathrm{240}\mathrm{-}\mathrm{11})=\mathrm{195}+\mathrm{229}\mathrm{=}\mathrm{424}$
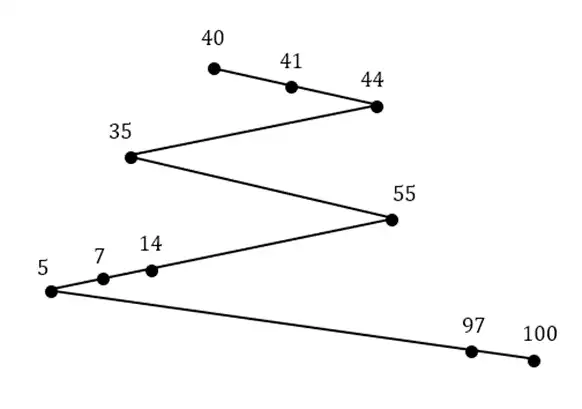
متوسط فرض کنید در سیستمی، مدیریت دیسک یکبار از زمانبندی SSTF ( کوچکترین زمان دستیابی اول) و یکبار از FIFO (به ترتیب در خواست ) استفاده کند. در صورتی که جابجایی بین هر دو شیار مجاور زمانی ثابت (2ms) طول بکشد و نوک خواندن - نوشتن روی شیار ۴۰ قرار داشته باشد، زمان جابجایی بین شیارها برای سرویسدهی به درخواستهای زیر در هر دو زمانبندی FIFO و SSTF به ترتیب چند میلی ثانیه است و کدام زمانبندی بهتر عمل میکند؟ ترتیب درخواستها برای شیارها (از راست به چپ): ۴۱ , 44 , 7 , 14 , 5 , 35 , 55 , ۱۰۰ , ۹۷ است. مدیریت I/O و دیسک
1۳۱۰، ۲۶۰ و زمانبندی SSTF از FIFO بهتر عمل میکند.
2۱۵۵، ۱۷۸ و زمانبندی FIFO از SSTF بهتر عمل میکند.
3۳۱۰، ۳۱۰ و SSTF مشابه FIFO عمل میکند.
4۳۱۰، ۳۵۶ و زمانبندی FIFO از SSTF بهتر عمل میکند.
گزینه 4 صحیح است.
SSTF
(44 – 40) + (44 – 35) + (55 – 35) + (55 – 5) + (100 – 5) = 178 بار جابهجایی
178 × 2 = 356ms
FIFO
(44 – 40) + (44 – 7) + (14 – 7) + (14 – 5) + (100 – 5) + (100 – 97) = 155 تعداد جابهجایی
155 × 2 = 310ms
در اینگونه سوالات ابتدا میزان جابهجایی کل نوک خواندن-نوشتن را محاسبه میکنیم و سپس عدد بدست آمده را در زمان لازم برای هر حرکت ضرب میکنیم.
در روش SSTF در هر انتخاب آدرسی را انتخاب میکنیم که به محل فعلی نوک نزدیکتر است.
در روش FIFO مانند صف عمل میکنیم و به آدرسی میرویم که زودتر از بقیه آمدهاست.
نکته: برای محاسبه سریعتر میتوانیم به جای محاسبه تک تک جابهجاییها بین آدرسها، میزان جابهجایی بین چرخشها را حساب کنیم. مثلا بهجای آنکه ابتدا فاصله بین آدرس 41 تا 40 را محاسبه کنیم و سپس فاصله بین 44 تا 41 را محاسبه کنیم، از ابتدا فاصله بین 44 و 40 را حساب میکنیم چون در این دو آدرس جهت حرکت نوک به یک سمت است و پس از 44 یک چرخش رخ داده و نوک به سمت چپ حرکت میکند.
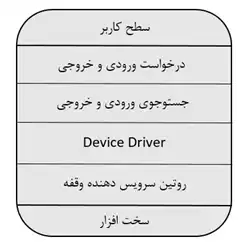
دشوار برای خواندن از دیسک، در کدام لایه نرم افزاری محاسبات مربوط به شیار (Track)، قطاع (Sector) و هد دیسک صورت میپذیرد؟ مدیریت I/O و دیسک
1لایه Device Driver
2لایه روتین سرویسدهی به وقفه
3لایه مدیریت دستگاههای سیستم عامل
4لایه نخ سطح هسته که برنامه سطح کاربر را اجرا میکند
گزینه 2 صحیح است.
Device driver لایه ای است که با دستگاه ارتباط بر قرار میکند و اطلاعات را با آن رد و بدل میکند.
روتین سرویس دهنده وقفه (ISR) پس از انجام عملیات ورودی و خروجی، درخواست های فرآیند ها را مدیریت کرده و ورودی خروجی مورد نیاز آن ها را تحویل میدهد.
حل کامل را در تست 9 فصل بن بست استاد رضوی میتوانید مشاهده کنید.
متوسط کدام گزینه در مورد الگوریتم های حرکت دیسک صحیح است؟ مدیریت I/O و دیسک
1قحطی زدگی در الگوریتم SSTF همواره بیشتر از الگوریتم C-SCAN است.
2 اگر درخواست ها به ترتیب صعودی و همگی بزرگتر از هد جاری باشند خروجی الگوریتم FIFO و SCAN-UP یکسان است.
3 چگالی پاسخگویی به درخواست های واقع در سیلندرهای بیرونی و داخلی در الگوریتم SCAN بیش از میانی است.
4 هدف اصلی از طراحی الگوریتم های حرکت هد کاهش پارامتر Rotation Time دیسک میباشد.
قحطی زدگی در الگوریتم های SSTF , SCAN وجود دارد و نمی توان قطعی گفت کدام یک بیشتر است و این مقایسه بستگی به دنباله درخواست ها دارد(رد گزینه اول). در خصوص فراوانی پاسخگویی به درخواست ها در الگوریتم SCAN نمی توان نظر مشخصی داد و وابستگی به دنباله درخواست ها دارد(رد گزینه 3). هدف اصلی از بکارگیری الگوریتم های حرکت هد کاهش زمان جستجوی هد یا همان Seek time است(رد گزینه 4).
نمونه سوالات فصل مدیریت حافظه درس سیستم عامل
دشوار حافظه اصلی با وضعیت نشان داده شده در شکل را در نظر بگیرید. اگر مدیریت حافظه اصلی براساس اختصاصدهی پویا باشد و اختصاصدهی فضای خالی به فرآیندها براساس Next-fit انجام گیرد و فرآیندهای
${\ P}_\mathrm{5},....., P_\mathrm{1} ,P_\mathrm{0}$ جهت اجرا شدن، مطابق با اطلاعات جدول زیر وارد سیستم شوند. با فرض اینکه از بین فضاهای پرشماره ۱ تا ۴، فقط فضای پر ۳ در لحظه ۲۰+t آزاد گردد (دیگر فضاهای پر تا اتمام اجرای فرآیندهای فوق آزاد نمیگردند)، متوسط زمان بازگشت (turn around) و متوسط زمان انتظار فرآیندهای فوق در روش FCFS به ترتیب چقدر است؟
مدیریت حافظه
| فضای پر ۱ (۳۰ KB) |
| فضای خالی ۱ (20 KB) |
| فضای پر ۲ (10 KB) |
| فضای خالی ۲ (40 KB) |
| فضای پر ۳ (20 KB) |
| فضای خالی ۳ (۳۰ KB) |
| فضای پر ۴ (40 KB) |
| فضای خالی ۴ (۳۰ KB) |
| زمان سرویس |
حافظه مورد نیاز (KB) |
زمان ورود |
فرآیند |
| 30 |
25 |
$t$ |
$p_0$ |
| 40 |
20 |
$t +1$ |
$p_1$ |
| 20 |
40 |
$t +2$ |
$p_2$ |
| 45 |
25 |
$t +3$ |
$p_3$ |
| 35 |
10 |
$t +4$ |
$p_4$ |
| 15 |
35 |
$t +5$ |
$p_5$ |
1 109/5 , 85/83
2 109/5 , 78/67
3 110/83 , 80
4 116/67 , 85/83
با توجه به فرض سوال مدیریت حافظه اصلی براساس اختصاصدهی پویا و براساس الگوریتم Next Fit انجام میشود. با توجه به این فرض تخصیص فضایهای خالی براساس زمان در جدول زیر آورده شده:
E
(30KB) |
F
(40KB) |
E
(30KB) |
E
(30KB) |
E
(40KB) |
F
(10KB) |
E
(20KB)
|
F
(30KB)
|
T= 0 |
E
(30KB) |
F
(40KB) |
E
(30KB) |
F
(20KB) |
E(15) |
F(25) |
F
(10KB) |
E
(20KB)
|
F
(30KB)
|
T= t |
E
(30KB) |
F
(40KB) |
E(10) |
F(20)
$p_1$ |
F
(20KB) |
E(15) |
F(25) |
F
(10KB) |
E
(20KB) |
F
(30KB)
|
T= t+1 |
E
(30KB) |
F
(40KB) |
E(10) |
F(20)
$p_1$ |
F
(20KB) |
E(15) |
F(25) |
F
(10KB) |
E
(20KB) |
F
(30 KB)
|
T= t+2 |
| E(5) |
F(250)
$p_3$ |
F
(40KB) |
E(10) |
F(20)
$p_1$ |
F
(20KB) |
E(15) |
F(25) |
F
(10KB) |
E
(20KB) |
F
(30 KB)
|
T= t+3 |
| E(5) |
F(250)
$p_3$ |
F
(40KB) |
E(10) |
F(20)
$p_1$ |
F
(20KB) |
E(15) |
F(25) |
F
(10KB) |
E(10) |
E(10)
$p_4$
|
F
(30KB)
|
T= t+4 |
| E(5) |
F(250)
$p_3$ |
F
(40KB) |
E(10) |
F(20)
$p_1$ |
F
(20KB) |
E(15) |
F(25) |
F
(10KB) |
E(10) |
E(10)
$p_4$
|
F
(30KB)
|
T= t+5 |
| E(5) |
F(250)
$p_3$ |
F
(40KB) |
E(10) |
F(20)
$p_1$ |
E(35) |
F(25) |
F
(10KB) |
E(10) |
E(10)
$p_4$
|
F
(30KB)
|
T= t+20 |
| E(5) |
F(250)
$p_3$ |
F
(40KB) |
E(10) |
F(20)
$p_1$ |
E(35) |
F(35) |
F
(10KB) |
E(10) |
E(10)
$p_4$ |
F
(30KB)
|
T= t+20 |
| E(30) |
F
(40KB) |
E(30) |
(E(20 |
F(40)
$p_2$ |
F
(10KB) |
E(20)
|
F
(30KB)
|
T= t+165 |
با توجه نمودار تخصیص فوق و الگوریتم زمانبندی بیان شده در سوال (FCFS) نمودار گانت سیستم به صورت زیر خواهد بود:
با توجه به نمودار گانت فوق متوسط زمان انتظار و متوسط زمان بازگشت به صورت زیر به دست میآید: (t=0 فرض شد)
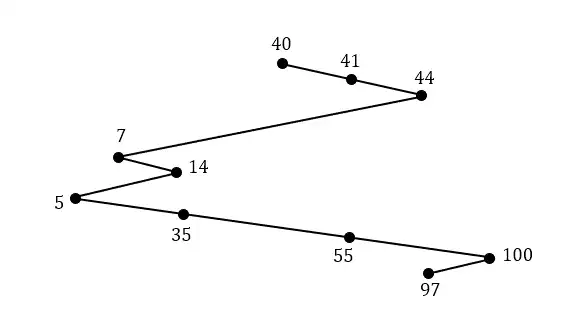
متوسط زمان انتظار=$\frac{\left(30-0-30\right)+\left(70-1-40\right)+\left(115-3-45\right)+\left(150-4-35\right)+\left(165-5-15\right)+\left(185-2-20\right)}{6}=\frac{515}{6}=85.83$
متوسط زمان بازگشت=$\frac{\left(30-0\right)+\left(70-1\right)+\left(115-3\right)+\left(150-4\right)+\left(165-5\right)+\left(185-2\right)}{6}=\frac{700}{6}=116.67$
متوسط در یک سیستم مدیریت حافظه صفحه بندی بر حسب تقاضا (Demand Paging)، اندازه حافظه سه قاب صفحه (Page Frame) و اندازه هر قاب 64 بایت است و این سیستم از الگوریتم جایگزینی LRU استفاده میکند. یک پردازه به اندازه 940 بایت وجود دارد. با فرض این که هنگام اجرا، به ترتیب (چپ به راست) به این آدرسها در پردازه (Process) مراجعه شود، درصد Page Fault چند درصد خواهد بود؟
مدیریت حافظه
810 / 670 / 800 / 480 / 300 / 830 / 160 / 350 / 20 / 240 / 40
(آدرسها نسبت به ابتدای برنامه ذکر شده است.)
1 82 %
2 73 %
3 64 %
4 55 %
چون آدرس را داده است لازم است شماره صفحات متناظر با آنها را بیابیم. از آنجاییکه هر صفحه 64 بایت است شماره صفحات به صورت زیر است:
$40{{\stackrel{\text{شماره}}{\longrightarrow}}}\left\lfloor \frac{40}{64}\right\rfloor =0 , 240{{\stackrel{\text{شماره}}{\longrightarrow}}}\left\lfloor \frac{240}{64}\right\rfloor =3 , 20{{\stackrel{\text{شماره}}{\longrightarrow}}}\left\lfloor \frac{20}{64}\right\rfloor =0 ,$
$360{{\stackrel{\text{شماره}}{\longrightarrow}}}\left\lfloor \frac{350}{64}\right\rfloor =5 , 160{{\stackrel{\text{شماره}}{\longrightarrow}}}\left\lfloor \frac{160}{64}\right\rfloor =2 , 830{{\stackrel{\text{شماره}}{\longrightarrow}}}\left\lfloor \frac{830}{64}\right\rfloor =12$
$300{{\stackrel{\text{شماره}}{\longrightarrow}}}\left\lfloor \frac{300}{64}\right\rfloor =4 , 480{{\stackrel{\text{شماره}}{\longrightarrow}}}\left\lfloor \frac{480}{64}\right\rfloor =7 , 800{{\stackrel{\text{شماره}}{\longrightarrow}}}\left\lfloor \frac{800}{64}\right\rfloor =12$
$760{{\stackrel{\text{شماره}}{\longrightarrow}}}\left\lfloor \frac{760}{64}\right\rfloor =11 , 810{{\stackrel{\text{شماره}}{\longrightarrow}}}\left\lfloor \frac{810}{64}\right\rfloor =12$
حال که شماره صفحات را به دست آوردیم الگوریتم LRU را اجرا میکنیم:
| 12 |
11 |
12 |
7 |
4 |
12 |
2 |
5 |
0 |
3 |
0 |
|
| 7 |
7 |
4 |
12 |
2 |
5 |
0 |
3 |
3 |
0 |
0 |
Frame 0 |
| 11 |
12 |
7 |
4 |
12 |
2 |
5 |
0 |
0 |
3 |
|
Frame 1 |
| 12 |
11 |
12 |
7 |
4 |
12 |
2 |
5 |
|
|
|
Frame 2 |
| |
+ |
|
+ |
+ |
+ |
+ |
+ |
|
+ |
+ |
PF |
تعداد نقص صفحه برابر با 8 است. تعداد کل مراجعات 11 تاست بنابراین:
درصد نقص صفحه $=\frac{8}{11}× 100%=73% $
زمان پردازش تمام کارها برابر با 35 ثانیه است.
دشوار به فرآیندی 4 قاب (frame) تخصیص یافته است. (تمام اعداد دهدهی هستند و همه شمارهگذاریها از صفر شروع شده است). زمان آخرین بار شدن یک صفحه در یک قاب، زمان آخرین دستیابی به صفحه، شماره صفحه مربوط به هر قاب، بیتهای مراجعه (R) و تغییر (m) برای هر قاب جدول زیر نشان داده شدهاند (زمانها بر حسب ضربان ساعت و از شروع فرآیند در زمان صفر است.)
مدیریت حافظه
| شماره صفحه |
شماره قاب |
زمان بارشدن صفحه در حافظه
|
زمان آخرین مراجعه
|
بیت مراجعه (R) |
بیت تغییر (M) |
| 2 |
0 |
60 |
160 |
0 |
1 |
| 1 |
1 |
130 |
161 |
0 |
0 |
| 0 |
2 |
26 |
163 |
1 |
0 |
| 3 |
3 |
20 |
162 |
1 |
1 |
یک خطای صفحه برای صفحه 4 رخ داده است. برای هر یک از سیاستهای مدیریت حافظه FIFO و LRU و clock (اشارهگر روی صفحه صفر است و اولویت با انتخاب صفحه تغییر نیافته است) به ترتیب چه صفحهای برای جایگزینی انتخاب میشود؟
1 0 و 1 و 1
2 1 و 0 و 2
3 3 و 2 و 1
4 1 و 1 و 2
گزینه 3 صحیح است.
میدانیم در روش FIFO، صفحهای که زود تر از بقیه وارد شدهاست برای جایگزینی استفاده میشود. پس، مطابق با اطلاعات مربوط به زمان بار شدن صفحات در حافظه، صفحه شماره 3 در این روش انتخاب میشود.
در الگوریتم LRU، صفحهای که زمان آخرین مراجعه کمتری دارد، به عنوان صفحه برای جایگزینی انتخاب میشود پس در این روش صفحه شماره 2 انتخاب میشود.
در الگوریتم Clock، مانند الگوریتم FIFO عمل میکنیم با این تفاوت که قبل از خارج کردن صفحه بیت R آن را چک میکنیم اگر R=1 بود یک شانس به آن صفحه میدهیم و آنرا خارج نمیکنیم در غیر اینصورت صفحه جایگزین میشود. اما دقت کنید که طراح در صورت سوال یک شرط دیگر هم اضافه کرده است و اولویت انتخاب صفحه جایگزینی با صفحهای است که تغییر نکرده باشد (M=0)باشد.
ترتیب ورود صفحات به حافظه از چپ به راست 3،0،2،1 است و با توجه به صورت سوال، اشارهگر روی صفحه شماره صفر قرار دارد. چون بیت R=1 است پس صفحه شماره صفر را خارج نمیکنیم.
اشارهگر جلو میرود و روی صفحه شماره 2 قرار میگیرد. بیت R=0 است پس باید شرط بعدی را هم بررسی کنیم و چون بیت M=1 است، این صفحه هم خارج نمیشود.
مجددا اشاره گر جلو میرود و روی صفحه شماره 1 قرار میگیرد و هر دو بیت R=0 و M=0 است پس این صفحه جایگزین میشود.
نمونه سوالات فصل حافظه مجازی درس سیستم عامل
متوسط به پردازه A، چهار قاب اختصاص یافته است. اگر این پردازه به صفحات خود به صورت دنبال، 4، 8، 9، 6، 3، 7، 4، 6، 8، 6، 3، 4، 5 (به ترتیب از چپ به راست) دسترسی داشته باشد، با کدام یک از الگوریتمهای جایگزینی صفحه زیر به نقص صفحه (Page fault) کمتری برخورد میکند؟ حافظه مجازی
1 FIFO
2 LRU
3 Second-Chance
4 LFU
در ابتدا که قابها خالی هستند و برای هر ۴ درخواست اول به نقص صفحه برخورد میکنیم. اما با توجه به الگوریتمهای جایگزینی صفحات در قاب داریم:
FIFO: برای صفحه شماره ۸ یک نقص صفحه و برای 7 یک نقص صفحه و برای ۹ یک نقص صفحه و برای ۴ یک نقص صفحه = ۴+۴ نقص صفحه
LRU: برای صفحه شماره ۸ یک نقص صفحه و برای 7 یک نقص صفحه و برای ۳ یک نقص صفحه و برای ۹ یک نقص صفحه و برای 8 به یک نقص صفحه و برای ۴ یک نقص صفحه = 4+6 نقص صفحه Second-cliance: صفحه شماره ۸ یک نقص صفحه و برای 7 یک نقص صفحه و برای3 یک نقص صفحه و برای ۹ یک نقص صفحه و برای ۸ یک نقص صفحه و برای ۴ یک نقص صفحه = 4+6 نقص صفحه
LFU: صفحه شماره ۸ یک نقص صفحه و برای ۷ یک نقص صفحه و برای ۶ یک نقص صفحه و برای ۹ یک نقص صفحه و برای ۴ یک نقص صفحه =4+5 نقص صفحه
متوسط سیستمی علاوه بر ذخیره جدول صفحه در حافظه اصلی، از جدول TLB نیز با نرخ miss برابر %10 استفاده میکند. اگر خواندن از حافظه اصلی 2ns زمان بردارد و میانگین زمان مراجعه به حافظه در صورت استفاده کردن از جدول TLB، 20% کاهش یابد، خواندن از TLB چند نانوثانیه زمان لازم دارد؟ حافظه مجازی
1 1
2 0/5
3 0/8
4 0/9
$H_{TLB}\mathrm{=}{\mathrm{1}\mathrm{-}Miss}_{TLB}=\mathrm{1}\mathrm{-}\circ .\mathrm{1}\mathrm{=}\mathrm{0/9}$
$T_{Total-TLB}=T_{Translation}+T_{Mem}=(T_{TLB}+(\mathrm{1}\mathrm{-}H_{TLB})\times T_{Mem})+T_{Mem}$
$T_{Total-TLB}=(T_{TLB}+\mathrm{0.1}\mathrm{\times }T_{Mem})+T_{Mem}=T_{TLB}+\mathrm{1.1}\mathrm{\times }T_{Mem}$
$T_{Total-No-TLB}\mathrm{=}T_{Translation}+T_{Mem}=\mathrm{2}\mathrm{\times }T_{Mem}$
$T_{Total-TLB}\mathrm{=}\mathrm{0.8}\mathrm{\times }T_{Total-No-TLB}$
$T_{TLB}+\mathrm{1.1}\mathrm{\times }T_{Mem}\mathrm{=}\mathrm{0.8}\mathrm{\times }\mathrm{2}\mathrm{\times }T_{Mem}$
$T_{TLB}\mathrm{=}\mathrm{1.6}\mathrm{\times }T_{Mem}-\mathrm{1.1}\mathrm{\times }T_{Mem}=\mathrm{0.5}\mathrm{\times }T_{Mem}=\mathrm{0.5}\mathrm{\ \times }\mathrm{\ 2}\mathrm{ns\ =}\mathrm{1}\mathrm{ns}$
متوسط در یک سیستم حافظه مجازی از نوع قطعه - صفحهای، بخشی از جدول TLB به صورت زیر است. اگر تعداد کلمات هر صفحه 4096 باشد، حجم حافظه مجازی چند برابر حافظه اصلی است؟
حافظه مجازی
| $\gets 12 \to$ |
$\gets 12 \to$ |
$\gets 4 \to$ |
| بلوک |
صفحه |
قطعه |
| 012 |
2FF |
1 |
| |
|
|
| 2A5 |
02A |
5 |
| |
|
|
1 16
2 8
3 4
4 2
گزینه 1 صحیح است.
با توجه به اینکه در هر صفحه 4096 کلمه وجود دارد بنابراین تعداد بیتهای offset برابر است با:
$4096=2^{12}=2^x\to x=12=offset$
فرمت آدرس منطقی به صورت زیر است:
تعداد بیتهای Seg# و P# از روی جدول موجود در صورت سوال به دست آمده است.
فرمت آدرس فیزیکی به صورت زیر است:
منظور از بلوکهای حافظه همان قاب (frame) است.
اندازه حافظه مجازی برابر است با $2^{28}$ و اندازه حافظه فیزیکی برابر است با $2^{24}$
نسبت حجم حافظه مجازی به حافظه فیزیکی برابر است با: $\frac{2^{28}}{2^{24}}=2^4=16$
متوسط سیستمی علاوه بر ذخیره جدول صفحه در حافظۀ اصلی، از جدول TLB نیز با نرخ miss برابر 20% استفاده میکند. اگر خواندن از حافظۀ اصلی 100ns زمان بردارد و درصد کارایی سیستم در صورت استفاده نکردن از جدول TLB برابر با 80% باشد، خواندن از TLB چند نانوثانیه زمان لازم دارد؟ حافظه مجازی
1 20
2 40
3 50
4 60
گزینه 2 صحیح است.
$H_{TLB}=1-{Miss}_{TLB}=1-0.2=0.8$
$T_{No\ TLB}=T_{translation}+T_{mem}=T_m+T_m=2T_m=200\ ns$
$T_{total\ TLB}=T_{translation}+T_{mem}=\left(T_{TLB}+\left(1-H_{TLB}\right)\times T_{mem}\right)+T_{mem}$
$T_{total\ TLB}=\left(T_{TLB}+\left(0.2\right)\times T_{mem}\right)+T_{mem}=T_{TLB}+{1.2T}_{mem}$
$T_{total\ TLB}=0.8\times T_{No\ TLB}=0.8\times 200\ ns=160\ ns$
$160\ ms=T_{TLB}+{1.2T}_{mem}=T_{TLB}+120\to T_{TLB}=40\ ns$
دفترچه سنجش زمان دسترسی به حافظه را به اشتباه به جای نانو ثانیه میلی ثانیه تایپ کرده بود، که اصلاح در سوال انجام شده است.
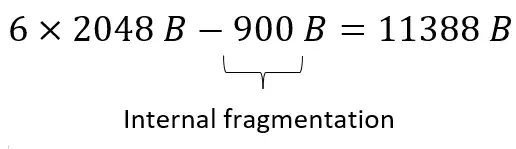
دشوار در یک سیستم که تخصیص حافظه در آن بر اساس صفحه بندی (Paging) انجام میشود، اندازه هر فریم (Frame) برابر 2048 بایت است. شکل زیر، حافظه اصلی سیستم است، که قسمتهای خاکستری فریمهای تخصیص داده شده به یک پردازه هستند. اگر Internal Fragmentation برابر 900 بایت باشد، اندازه پردازه و External Fragmentation چند بایت است؟
حافظه مجازی
1 اندازه پردازه برابر 12288 بایت و اندازه External Fragmentation برابر 14336 بایت است.
2 اندازه پردازه برابر 12288 بایت و اندازه External Fragmentation برابر صفر است.
3 اندازه پردازه برابر 11388 بایت و اندازه External Fragmentation برابر صفر است.
4 اندازه پردازه برابر 6 بایت و اندازه External Fragmentation برابر 7 بایت است.
نکته: در روش صفحهبندی External fragmentation نداریم و فقط Internal fragmentation داریم. براین اساس گزینه 1 و 4 رد میشوند.
در صفحهبندی اندازه صفحه با اندازه قاب برابر است. پس اندازه صفحه برابر است با: $PageSize=2048\ B$
از آنجاییکه تعداد قابهای تخصیص داده شده به یک پردازه 6 تا است پس اندازه پردازه برابر است با:
آسان یک سیستم کامپیوتری دارای حافظه پنهان، حافظه اصلی و دیسک برای استفاده از حافظه مجازی است. اگر کلمه مورد مراجعه در حافظه پنهان باشد، 20 نانوثانیه برای دستیابی لازم است. اگر کلمه موردنظر در حافظه اصلی باشد و در حافظه پنهان نباشد، 60 نانوثانیه برای انتقال آن به حافظه پنهان نیاز است و سپس دستیابی آغاز میشود. اگر کلمه در حافظه اصلی نباشد، 12 میلیثانیه لازم است تا در حافظه اصلی کپی شود و در پی آن 60 نانوثانیه برای انتقال به حافظه پنهان مورد نیاز است و سپس دستیابی آغاز میشود. نرخ اصابت برای حافظه پنهان 0.9 و برای حافظه اصلی 0.6 است. میانگین زمان دستیابی یک کلمه در این سیستم چند نانوثانیه است؟ حافظه مجازی
1 480021.6
2 480025.2
3 480023.6
4 480026
گزینه 4 صحیح است.
در دستیابی به یک کلمه در حافظه ۳ حالت رخ میدهد:
1. اگر کلمه در حافظه نهان باشد مدت زمان مصرف شده تنها ۲۰ نانوثانیه میباشد. احتمال این حالت 0.9 است.
2. اگر کلمه در حافظه اصلی باشد و در حافظه نهان نباشد زمان مصرف شده برابر با ۶۰ نانوثانیه جابهجایی به علاوه ۲۰ نانوثانیه چککردن حافظه نهان در ابتدای بررسی میباشد. احتمال این حالت $0.1×0.6$ است (ضرب وجود و عدم وجود کلمه مورد نظر به ترتیب در حافظه اصلی و حافظه نهان).
3. اگر کلمه در حافظه اصلی و نهان نباشد ۲۰ نانوثانیه صرف چککردن حافظه نهان، ۱۲ میلیثانیه یعنی ۱۲۰۰۰۰۰۰ نانوثانیه زمان صرف جابهجایی آن کلمه از دیسک به حافظه اصلی و ۶۰ نانوثانیه صرف جابهجایی از حافظه اصلی به حافظه نهان میشود که در مجموع ۱۲۰۰۰۰۸۰ نانوثانیه است. احتمال این حالت $0.1×0.4$ است (ضرب عدم وجود کلمه در دو حافظه اصلی و نهان).
زمان میانگین با ضرب زمان هر قسمت در احتمال آن و در نهایت جمع تمام حالات بدست میآید:
$0.9×20+0.1×0.6×(60+20)+0.1×0.4×(12000000+60+20)=480026$
متوسط کامپیوتری با یک فضای آدرسپذیر مجازی 64 بیتی را که صفحات آن هر یک 2048 بایت ظرفیت دارند، در نظر بگیرید. اندازه هر مدخل جدول صفحه 4 بایت است. به دلیل آنکه هر جدول باید داخل یک صفحه جای گیرد، یک جدول صفحه چند سطحی استفاده شده است، به نظر شما چند سطح مورد نیاز است؟ حافظه مجازی
1 3 سطح
2 4 سطح
3 6 سطح
4 9 سطح
فضای آدرس مجازی ما 64 بیت است.
سایز هر صفحه ما برابر 2048 بایت یا به عبارتی برابر $2^{11}$ بایت است بنابراین افست ما 11 بیتی خواهد بود.
بنابراین فرمت کلی آدرس مجازی به فرم زیر خواهد بود:
| offset |
Page Table n |
.... |
Page Table 2 |
Page Table 1 |
که n تعداد سطحها مورد نیاز است. بنابر اطلاعات داده شده در سوال میدانیم که هر جدول صفحه باید در یک صفحه جای گیرد از طرفی اندازه مدخل هر جدول صفحه برابر است با 4 بایت است بنابراین در هر سطح جدول صفحه $\frac{2^{11}}{2^2}=2^9$ درایه وجود خواهد داشت. پس برای آدرسدهی به هر سطح از جدول صفحه به 9 بیت نیاز خواهیم داشت بنابراین 53 بیت باقی مانده از آدرس مجازی برای آدرس دهی به $\left\lceil\frac{53}{9}\right\rceil=6$ سطح کافی خواهند بود.
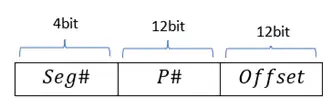
دشوار یک حافظه به اندازه 8KB و با صفحات ۵۱۲ بایتی را در نظر بگیرید که با روش قطعات صفحهبندی شده (Segmentation with paging) مدیریت میشود. اگر آدرسها را ۱۴ بیتی در نظر بگیریم که ۹ بیت کم ارزش آن (از بیت ◦ تا ۸) مربوط به افست درون صفحه، ۳ بیت بعدی (از بیت ۹ تا ۱۱) مربوط به شماره صفحه یک سگمنت، و ۲ بیت پرارزش (از بیت ۱۲ تا ۱۳) مربوط به شماره سگمنت باشند، با توجه به وضعیت زیر از حافظه، آدرس فیزیکی متناظر با آدرس مجازی $15{AC}^H$ کدام گزینه است: (PTBA: Page Table Base Address)
حافظه مجازی
| Limit |
PTBA |
|
| ${\mathrm{8}}^H$ |
${\circ \circ \mathrm{8} \circ}^H$ |
0 |
| ${\mathrm{8}}^H$ |
${\circ \circ \mathrm{88}}^H$ |
1 |
| ${\mathrm{8}}^H$ |
${\circ \circ \mathrm{9} \circ}^H$ |
2 |
| ${\mathrm{8}}^H$ |
${\circ \circ \mathrm{98}}^H$ |
3 |
| Segment table |
|
| |
${\circ \circ \mathrm{98}}^H$ |
${\circ \circ \mathrm{9} \circ}^H$ |
${\circ \circ \mathrm{88}}^H$ |
${\circ \circ \mathrm{8} \circ}^H$ |
| |
$\searrow $ |
$\searrow $ |
$\searrow $ |
$\searrow $ |
| ${\mathrm{5}}^H$ |
${\mathrm{7}}^H$ |
${\mathrm{3}}^H$ |
${\mathrm{3}}^H$ |
|
| ${\mathrm{7}}^H$ |
${\mathrm{5}}^H$ |
${\mathrm{5}}^H$ |
${\mathrm{5}}^H$ |
|
| ${\mathrm{3}}^H$ |
${\mathrm{3}}^H$ |
${\mathrm{9}}^H$ |
${\mathrm{7}}^H$ |
|
| ${\mathrm{9}}^H$ |
${\mathrm{9}}^H$ |
${\mathrm{7}}^H$ |
${\mathrm{9}}^H$ |
|
| ${\mathrm{5}}^H$ |
${\mathrm{7}}^H$ |
${\mathrm{3}}^H$ |
${\mathrm{3}}^H$ |
|
| ${\mathrm{7}}^H$ |
${\mathrm{5}}^H$ |
${\mathrm{5}}^H$ |
${\mathrm{5}}^H$ |
|
| ${\mathrm{3}}^H$ |
${\mathrm{3}}^H$ |
${\mathrm{9}}^H$ |
${\mathrm{7}}^H$ |
|
| ${\mathrm{9}}^H$ |
${\mathrm{9}}^H$ |
${\mathrm{7}}^H$ |
${\mathrm{9}}^H$ |
|
| بخشی از Physical Memory |
|
1 $13{AC}^H$
2 $0{BAC}^H$
3 $07{AC}^H$
4 $0{FAC}^H$
گزینه 1 صحیح است.
طبق صورت سوال، میدانیم ساختار آدرس مجازی به صورت زیر است:
همانطور که مشخص است، جدول صفحه دو سطحی داریم که در سطح اول، جدول صفحه خارجی و در سطح دوم جدول صفحه حاوی متن برنامه قرار دارد. حال با توجه به آدرس مجازی داده شده توسط سوال و ساختار آن داریم:
15ACH = 0001 0101 1010 1100 : آدرس مجازی (منطقی)
110101100 :آفست, 010 :شماره صفحه, 01 :سگمنت
متوجه شدیم که باید دنبال قطعه شماره یک باشیم که مقدار داخل آن برابر 0088H است. در مرحله بعدی باید در ستون مربوط به 0088H، شماره صفحه مطلوب را پیدا کنیم که با توجه به آدرس مجازی، شماره صفحه $2 = 2_(010)$ است. مقدار درون صفحه شماره 2 برابرست با 9H، بنابراین برای محاسبه آدرس فیزیکی باید مقدار آفست را به انتهای 9H اضافه کنیم:
$9H = (1001)_2 → {\text{آدرس}\ \text{فیزیکی}:} 1001 110101100 =$$13ACH$
آسان از ویژگیهای پردازندههای RISC میتوان تعداد دستورالعملهای ............. در معماری مجموعه دستورالعملها و میانگین تعداد عملیات .............. برای اجرا نام برد. طراحی کامپیوتر
1 کم، زیاد
2 کم، کم
3 زیاد، کم
4 زیاد، زیاد،
از ویژگیهای پردازندههای RISC میتوان تعداد دستورالعملهای کم در معماری مجموعه دستورالعملها و میانگین تعداد عملیات زیاد برای اجرا نام برد.
اشتراکhttps://www.konkurcomputer.ir/e568