پاسخ تشریحی کنکور ارشد کامپیوتر 1400 در این صفحه بصورت رایگان قرار گرفته و روش های دسترسی به پاسخ های سایر سال های کنکور ارشد کامپیوتر گفته شده است
مطالعه با حل تمرین و تست تکمیل میشود. دانشجویان پس از حل تست باید به رفع اشکال آن بپردازند. ازاینرو، در اختیار داشتن پاسخنامه تشریحی تستها بسیاری مهم است. این مقاله به بررسی پاسخ تشریحی کنکور ارشد کامپیوتر ۱۴۰۰ میپردازد. در انتهای مقاله نحوه دسترسی به پاسخ کلیدی کنکور کامپیوتر ۱۴۰۰ را نیز بیان خواهیم کرد.
روش های دسترسی به پاسخ تشریحی تست های کنکور ارشد کامپیوتر ۱۴۰۰
شما میتوانید به یک از دو روش زیر به پاسخ تشریحی تست های کنکور ارشد ۱۴۰۰ دسترسی داشته باشید:
روش اول: استفاده از پلتفرم آزمون کنکور کامپیوتر
پلتفرم آزمون و بانک تست و مجموعه سوالات کنکور ارشد کامپیوتر و آیتی
سیستم قدرتمند آزمون کنکور کامپیوتر - اولین و تنها سیستم آزمون رشته کامپیوتر
داوطلبین کنکور ارشد کامپیوتر و آیتی، با این پلتفرم نیازی به تهیه هیچ کتابی ندارید، بهتر از هر کتاب مجموعه سوالات
در زیر پاسخ تشریحی تست های کنکور کامپیوتر ۱۴۰۰ برای درسهای هوش مصنوعی، سیستم عامل، پایگاه داده و نظریه زبانها و ماشینها به همراه پاسخ تشریحی آمده است:
جواب تشریحی تستهای درس هوش مصنوعی کنکور کامپیوتر ۱۴۰۰
متوسط در حل یک مسئله ارضای قیود، از الگوریتم AC-3 استفاده شده است. فرض کنید هر قید شامل دو متغیر است و اندازه دامنه متغیرها، یکسان و برابر با d است. همینطور تعداد متغیرها برابر با n است. هر یال گراف قیود حداکثر چندبار نیاز به سازگار شدن دارد؟ مسائل ارضای محدودیت
1 1
2 d
3 n
4 n - 1
گزینه 2 صحیح است.
در این روش تعداد دفعاتی که یک یال نیاز به سازگار شدن دارد برابر همان دامنه متغیرهاست چرا که در صورتی که تغییری در دامنه یکی از این متغیرها ایجاد شود همه یالهای وارد شونده به آن دوباره به صف وارد میشوند و این تغییرات برای یک یال حداکثر برابر تعداد مقادیر دامنه متغیر یعنی d است.
متوسط محیط زیر با کنشهای (action) بالا U، پایین D، چپ L و راست R را در نظر بگیرید. کنشهایی که باعث ورود به خانه S5 میشوند پاداش برابر با 10 دارند و خود S5 خانه وضعیت پایان است. سایر کنشها پاداش $-1$ دارند. مقدار ضریب تخفیف (discount factor) برابر γ=0.9 را در نظر بگیرید. کدام گزینه صحیح است؟ عدم قطعیت
مقادیر V و Q خواسته شده در این سؤال برابر تابع سیاست بهینه میباشند. (علامت ستاره بالای هر کدام بیانگر این موضوع است.)
تابع سیاست بهینه با شروع از حالت S1 ابتدا به یکی از حالات S2 یا S4 میرود و سپس به حالت نهایی S5 میرود. پاداش حرکت اول برابر -1و پاداش حرکت دوم برابر ۱۰ است که با احتساب ضریب تخفیف داریم:
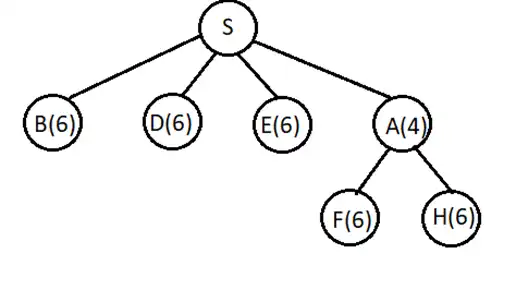
متوسط محیط زیر با وضعیت شروع S و وضعیت هدف G را در نظر بگیرید. فرض کنید خانههای خاکستری مسدود هستند و نمیتوان به آنها وارد شد. همچنین در هر وضعیت چهار کنش بالا U، راست R، پایین D و چپ L با هزینه برابر قابل انجام هستند. اولویت انتخاب کنشها هم در شرایط یکسان به ترتیب از راست به چپ D، R، U و L خواهد بود. اگر کنشی منجر به برخورد به خانههای مسدود یا دیوارها شود، عامل (agent) سر جایش میماند. اگر جستجو گرافی (graph search) انجام شود، خانه A در شکل زیر چندمین گره برداشته شده از صف برای گسترش در روشهای DFS و BFS خواهد بود؟ الگوریتم های جستجوی ناآگاهانه
A
S
G
1 2: DFS و 2: BFS
2 2: DFS و 6: BFS
3 6: DFS و 2: BFS
4 6: DFS و 6: BFS
گزینه 2 صحیح است.
شکل زیر را در نظر بگیرید :
روش BFS :
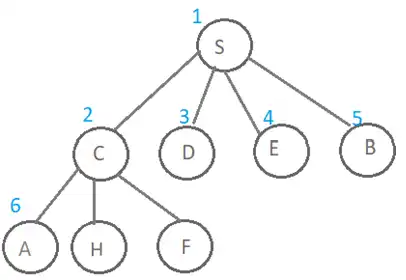
درخت حاصل از جستجو به این روش و ترتیب بسط گرهها در ادامه نمایش داده شده است. همانطور که در شکل زیر مشخص است پس از S تمامی فرزندان آن بسط داده میشوند و درنهایت نوبت به فرزندان گره C میرسد و گره A از فرزندان این گره چون کنش UP اولویت بیشتر دارد زودتر به صف اضافه شده و در نتیجه زودتر هم نوبت به بسط آن میرسد و به عنوان گره ۶ ام بسط داده میشود.
روش DFS :
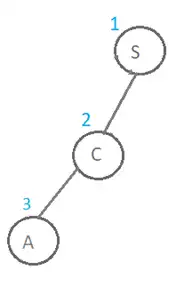
درخت حاصل از جستجو به این روش و ترتیب بسط گرهها در ادامه نمایش داده شده است. همانطور که در شکل زیر مشخص است پس از S فرزند اول آن یعنی C و پس از آن گره A بسط پیدا میکند و در واقع گره A به عنوان گره ۳ ام بسط داده میشود.
اعداد بدست آمده در هیچکدام از گزینهها موجود نیستند اما میتوان با اغماض گزینه دوم را بعنوان پاسخ سوال در نظر گرفت.
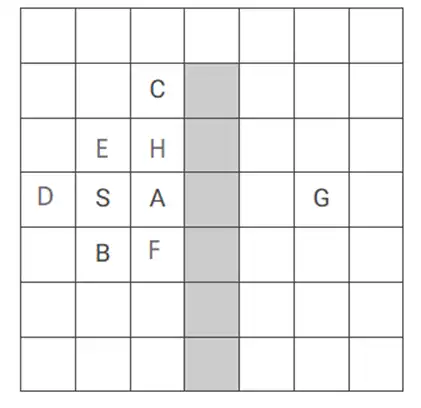
متوسط محیط زیر با وضعیت شروع S و وضعیت هدف G را درنظر بگیرید. فرض کنید خانههای خاکستری مسدود هستند و نمیتوان به آنها وارد شد. همچنین در هر وضعیت چهار کنش بالا U، راست R، پایین D و چپ L با هزینه برابر واحد قابل انجام هستند. اولویت انتخاب کنشها هم در شرایط یکسان به ترتیب از راست به چپ U ،L ،D و R خواهد بود و برای برداشته شدن از صف هم در شرایط کاملاً یکسان از نظر معیار صف اولویت گرهای که زودتر در صف گذاشته شده برداشته میشود. اگر کنشی منجر به برخورد به خانههای مسدود یا دیوارها شود، عامل (agent) سر جایش میماند. اگر جستجو گرافی (graph search) با روش \( {A}^* \) با تابع ابتکاری (heuristic) فاصلهی منهتن تا هدف انجام شود، کدام ترتیب در برداشته شدن از صف جهت گسترش گرههای مشخص B ،A و C (از چپ به راست) درست است؟ الگوریتم های جستجوی آگاهانه
C
G
A
S
B
1 A-B-C
2 A-C-B
3 B-A-C
4 B-C-A
گزینه 1 صحیح است.
با توجه به شکل زیر درخت حاصل از جستجو A* در این سوال در ادامه رسم شده است. برای اجرای این روش در این مسئله باید توجه داشت که اولویت انتخاب کنشها در شرایط یکسان به ترتیب از راست به چپ U ،L ،D و R خواهد بود و برای برداشته شدن از صف هم در شرایط کاملاً یکسان از نظر معیار صف اولویت گرهای که زودتر در صف گذاشته شده برداشته میشود. همچنین در محاسبه فاصله منهتن برای خانهها به عنوان تابع ابتکاری دیوار را در نظر نمیگیریم.
در مرحله اول از بین فرزندان خانه S، به خانه A میرویم که f(n) کمتری دارد (در هر گره در درخت زیر مقدار f(n) در کنار نام گره نوشته شده است). پس از آن فرزندان گره A نیز به صف اضافه میشوند و در این مرحله از آنجایی که مقدار f(n) برای تمامی گرهها یکسان است گرهای که زودتر در صف قرار داده شده است یعنی گره B انتخاب میشود. پس در کل ابتدا گره A و سپس گره B انتخاب شد و پاسخ سوال گزینه ۱ میباشد.
متوسط در کدام یک از گرافهای قیود زیر با n رأس، الزاماً میتوان مسئله ارضای قیود را در زمان چندجملهای نسبت به تعداد متغیرها و اندازهی مجموعه مقادیر مجاز متغیرها حل کرد؟ مسائل ارضای محدودیت
1 گرافی با دو مؤلفه همبندی
2 گرافی با فقط یک دور
3 گراف کامل
4 هیچکدام
گزینه 2 صحیح است.
پیچیدگی محاسباتی مسئله ارضا محدودیت در صورتی که گراف مسئله به شکل درخت باشد از مرتبه $O(nd^2)$ که برحسب تعداد رئوس و دامنه مقادیر مجاز چندجملهای است اما در حالتی که گراف با فقط یک دور نیز داشته باشیم میتوانیم از طریق حذف گره و با استفاده از روش cutset مسئله را حل کنیم. در این مسئله میتوان با حذف یک گره که در دور گراف قرار دارد، یک درخت و یک مجموعه cutset ساخت و مرتبه زمانی حل این مسئله با این روش از مرتبه $O((n-c)d^{2+c})$ میباشد که در آن c تعداد اعضای cutset میباشد که در اینجا برابر با ۱ است و همچنین بخش $O((n-c)d^2)$ مرتبه زمانی حل درخت حاصل و $O(d^c)$ مرتبه زمانی مقداردهی به اعضای cutset میباشد.
دشوار برای حل یک مسئلهی جستجو، از روشهای محلی تپهنوردی استفاده کردهایم. فرض کنید احتمال موفقیت در جستجویی که از یک حالت تصادفی شروع میشود، برابر با 25 درصد است. زمانی که جستجو موفقیتآمیز باشد، به صورت متوسط نیاز به طی کردن 7 گام دارد و در صورتی که به یک کمینه محلی غیر بهینه همگرا شود، به صورت متوسط 9 گام طی میشود. به منظور حصول اطمینان از به جواب رسیدن روش، در صورت همگرایی به کمینه محلی غیر بهنیه، از حالت تصادفی اولیه دیگری جستجو را آغاز میکنیم. به صورت متوسط چند گام برای رسیدن به پاسخ بهینه سراسری باید طی شود؟ مسائل ارضای محدودیت
1 27
2 28
3 34
4 43
گزینه 3 صحیح است.
نکات :
اگر احتمال موفقیت الگوریتم جستجو محلی با شروع مجدد تصادفی در هر بار برابر p باشد آنگاه متوسط تعداد دفعات شروع مجدد برای رسیدن به پاسخ بهینه عمومی در این الگوریتم برابر $\frac{1}{p}$ میباشد.
(برای اثبات نکته بالا باید از تعریف امید ریاضی برای متغیر دارای توزیع هندسی کمک گرفت :
اگر احتمال موفقیت الگوریتم جستجو محلی با شروع مجدد تصادفی در هر بار برابر p باشد آنگاه تعداد گامهای مورد انتظار برای رسیدن به پاسخ بهینه برابر است با:
تعداد کل گامها : ( تعداد گامها در تپهنوردی در حالت موفق) + (تعداد گامها در تپهنوردی در حالت ناموفق) $(\frac{1}{p}-1)$
پاسخ سوال :
احتمال موفقیت = 0.25= p
تعداد گامها در تپهنوردی در حالت ناموفق = 9
تعداد گامها در تپهنوردی در حالت موفق = 7
تعداد کل گامها = $(4-1) × 9+7=34$
متوسط فرض کنید برای حل یک مسئلهی جستجوی خصمانه از روش درخت min-max با هرس α - β استفاده میکنیم. در یکی از مراحل میانی که مقدار max را تخمین میزنیم، مقدار α برابر با 4، مقدار β برابر با 3 و تخمین فعلی حالت max برابر با صفر است. فرض کنید در این مرحله، مقدار یکی از حالتهای بعدی حالت max مذکور را به صورت بازگشتی محاسبه کردهایم. به ازای کدام مقدار برای حالت بعدی، حالت max مذکور را هرس میکنیم؟ بازی های رقابتی
1 0
2 1
3 2
4 4
گزینه 4 صحیح است.
در این سوال گفته شده است که مقدار آلفا برابر ۴ و مقدار بتا برابر ۳ میباشد و این به این معنی است که در همین حالت نیز شرط هرس برقرار است و نیازی به بررسی حالات بعدی نیست و میتوان حالت max مذکور را هرس کرد. اما بیاید فرض کنیم که در صورت سوال مقدار آلفا داده نشده است در این صورت برای اینکه بخواهیم شرط هرس برقرار شود باید مقدار تخمینی برای گره بعدی بیشتر مساوی ۳ باشد تا پس از بررسی این حالت مقدار آلفا برای حالت max برابر با این عدد شده و امکان هرس برای حالت max مذکور در شاخهای که مقدار تخمینی آن صفر است اتفاق بیفتد.
دشوار کدام گزینه در مورد حل مسائل CSP درست است؟ مسائل ارضای محدودیت
1 استفاده از forward checking در طول الگوریتم معادل با استفاده از AC3 قبل از اجرا و فیلتر کردن دامنههاست.
2 استفاده از پیشپردازش و فیلتر کردن دامنهها توسط AC3 ممکن است باعث شود که برخی از جوابهای مسأله CSP را از دست بدهیم.
3 برای مسائل CSP که جواب ندارند پیشپردازش صورت گرفته توسط AC3 همیشه به دامنهی تهی حداقل یکی از متغیرها منجر میشود.
4 اگر در یک مسئله CSP دنبال همهی جوابها باشیم، استفاده از تکنیک ترتیب مقادیر (value ordering) تأثیری در بهبود سرعت نخواهد داشت.
گزینه 4 صحیح است.
گزینه ۱ : این گزینه نادرست است چرا که در AC سازگاری یالها بررسی میشود در حالیکه در forward check در هر مرحله با مقداردهی به یکی از متغیرها، دامنه سایر متغیرها با توجه به این مقداردهی بروز شده و مقادیر متناقض حذف میشوند.
گزینه ۲ : این گزینه نادرست است و استفاده از این روشها منجر به از دست رفتن راهحلها نمیشود.
گزینه ۳ : ممکن است علت عدم وجود راه حل برای این نوع مسائل وجود محدودیتها بیش از دوتایی باشد و این نوع محدودیتها در روش AC3 کشف نمیشوند و نمیتوان گفت در حالتی که راهحل وجود ندارد این الگوریتم آن را یافت میکند و به دامنه تهی میرسد.
گزینه ۴ : در مسائل ارضا محدودیت در حالتی که بدنبال تمام جوابهای مسئله باشیم استفاده از تکنیک مشخص کننده ترتیب مقادیر تاثیر در بهبود جواب ندارد چرا که باید در نهایت همه مقادیر ممکن برای یک متغیر بررسی شوند اما تکنیک مشخص کننده ترتیب انتخاب متغیرها میتواند مفید باشد و باعث شود مسیرهایی که به جواب نمیرسند زودتر پیدا شده و حذف شوند.
توضیح: گزینه 4 در دفترچه بصورت زیر بوده است که ما برای درست شدن این تست گزینه 4 را تغییر دادهایم
اگر در یک مسئله CSP دنبال همهی جوابها باشیم، استفاده از تکنیکهای مشخصکنندهی ترتیب متغیرها (variable ordering) و ترتیب مقادیر (value ordering) تأثیری در بهبود سرعت نخواهد داشت.
پاسخ این سوال در ابتدا گزینه ۱ اعلام شده بود و سپس این سوال حذف شد.
جواب تشریحی تستهای درس سیستمهای عامل کنکور کامپیوتر ۱۴۰۰
آسان کدام سطح از RAID را Disk mirroring میگویند؟ مدیریت I/O و دیسک
1 0
2 1
3 2
4 3
گزینه 2 صحیح است.
RAID مخفف (redundant Array of Independent) است. از تکنیک RAID برای افزایش سرعت خواندن و نوشتن، افزایش تحملپذیری در برابر خطا و افزایش فضای ذخیرهسازی استفاده میشود. سطوح مختلفی از مکانیسم RAID وجود دارد که هفت سطح آن مورد توافق همه است. (از 0 تا 6)
در RAID چهار تکنیک (برای تحقق اهداف RAID) مورد استفاده قرار میگیرد و یکی از این تکنیکها mirroring است. از این تکنیک برای افزایش قابلیت اطمینان استفاده میشود. به این صورت که دادههای اصلی روی دو دیسک به طور یکسان نوشته میشوند. و در صورت خرابی یک دیسک، دادهها از بین نمیروند.
تکنیکهای دیگر عبارت اند از: Striping, Parity, Hamming code
هریک از این تکنیکها در سطوح مختلف مورد استفاده قرار میگیرند. Mirroring در RAID سطح 1 استفاده میشود.
دشوار کدام مورد سیستمعامل را مجبور میکند دستورات $s_4،~ s_3، ~ s_2،~ s_1$ که به ترتیب در پردازههای همروند $p_4، ~p_3، ~ p_2، ~p_1$ قرار دارند به همان ترتیب $s_4،~ s_3، ~ s_2،~ s_1$ اجرا کند؟ (مقدار اولیه سمافورها ∘ = a = b = c) انحصار متقابل
1
$P_4$
$P_3$
$P_2$
$P_1$
Wait(c)
$S_4$
Wait(b)
$S_3$
Signal(c)
Wait(a)
$S_2$
Signal(b)
$S_1$
Signal(a)
2
$P_4$
$P_3$
$P_2$
$P_1$
Wait(a)
Wait(b)
$S_4$
Wait(a)
$S_3$
Signal(b)
Wait(b)
$S_2$
Signal(a)
$S_1$
Signal(a)
Signal(b)
3
$P_4$
$P_3$
$P_2$
$P_1$
Wait(a)
Wait(a)
Wait(a)
$S_4$
Signal(a)
Signal(a)
Signal(a)
Signal(a)
Wait(a)
Wait(a)
$S_3$
Signal(a)
Signal(a)
Signal(a)
Wait(a)
$S_2$
Signal(a)
Signal(a)
$S_1$
Signal(a)
4
$P_4$
$P_3$
$P_2$
$P_1$
Wait(a)
Signal(b)
Signal(c)
$S_4$
Wait(a)
Signal(b)
$S_3$
Signal(c)
Wait(a)
$S_2$
Signal(b) Signal(c)
$S_1$
Wait(a)
Signal(b)
Signal(c)
گزینه 1 صحیح است.
با توجه به مقادیر اولیه سمافورها ($a=b=c=0$) فقط دستور $S_1$ در ابتدا میتواند اجرا شود.
بررسی گزینه 1: این گزینه صحیح است. زیرا اجرای فرایندهای $P_3$ ، $P_2$ ، $P_1$ و $P_4$ فقط منجر به اجرای دستورات $S_3$ ، $S_2$ ، $S_1$ و $S_4$ به همین ترتیب میشود.
علت رد گزینه 2: میتوان سناریویی را پیدا کرد که اجرای فرایندهای $P_3$ ، $P_2$ ، $P_1$ و $P_4$ منجر به اجرای دستورات به ترتیب $S_2$ ، $S_3$ ، $S_1$ و $S_4$ شود. (در صورتی که فرایندها به این ترتیب اجرا شوند: $P_2$ ، $P_3 $ ، $P_1$ و $P_4$)
علت رد گزینه 3: در این گزینه اجرای فرایندهای $P_3$ ، $P_2$ ، $P_1$ و $P_4$ میتواند منجر به اجرای دستورات $S_3$ ، $S_2$ ، $S_1$ و $S_4$ به همین ترتیب شود. اما سناریوی دیگری را میتوان یافت که تمامی فرایندها پس از اجرای فرایند 1 به خواب ابدی بروند. (در صورتی که فرایند ها به این ترتیب اجرا شوند: $P_2$ ، $P_3$ ، $P_1$ و $P_4$)
علت رد گزینه 4: این گزینه نادرست است زیرا اجرای فرایندهای $P_3$ ، $P_2$ ، $P_1$ و $P_4$ منجر به خواب ابدی میشود.
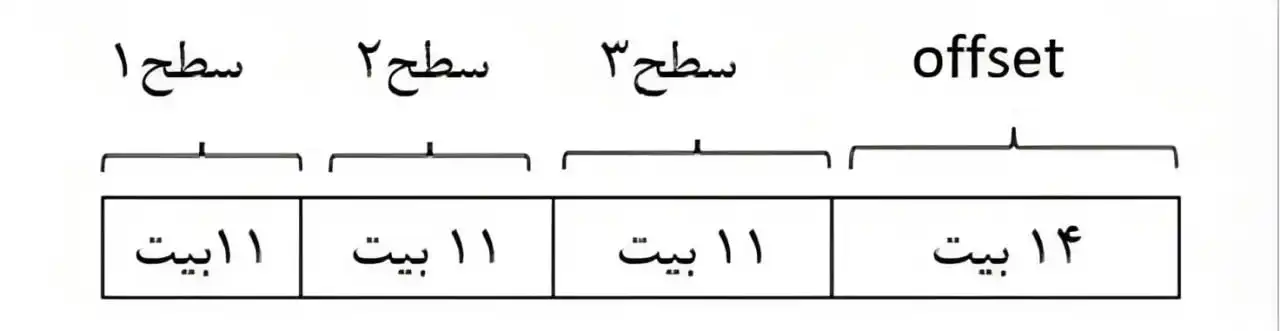
متوسط فرض کنید که طول آدرس مجازی 47 بیت و اندازه صفحه 16KB و هر مدخل از جدول صفحه 8 بایت باشد. اگر بخواهیم هر جدول صفحه تنها در یک صفحه ذخیره شود، از جدول صفحه چند سطحی استفاده شود؟ حافظه مجازی
1 2
2 3
3 4
4 5
گزینه 2 صحیح است.
فرمت آدرس منطقی:
$Offset$
$PT_n$
...
$PT_2$
$PT_1$
با توجه به صورت سوال هر جدول صفحه جزئی باید در یک قاب قرار گیرد. برای محاسبه تعداد سطرهای جدول صفحه جزئی باید اندازه قاب را (که برابر است با اندازه جدول صفحه جزئی) بر اندازه عرض جدول صفحه ($=e$ مدخل) تقسیم کنیم:
برای محاسبه تعداد سطوح جدول صفحه کافیست از سمت راست به اندازه تعداد بیتهایی که برای نشان دادن سطرهای جدول صفحه جزئی استفاده میکنیم (در اینجا 11 بیت با توجه به محاسبات بالا) جدا کنیم:
تعداد سطوح برابر با 3 است.
توجه: در مجموع طول آدرس منطقی با توجه به گفته سوال باید 47 بیت شود.
دشوار الگوریتم زیر برای حل مسئله ناحیه بحرانی (Critical-Problem) را در نظر بگیرید. در این الگوریتم، در حالتی که تنها دو پردازه ∘P و P1 وجود داشته باشد، متغیرهای flag و turn بین این دو پردازه مشترک هستند: انحصار متقابل
Boolean flag [2]:/*initially false*/
Int turn;
با فرض اینکه ساختار پردازه $(i=0\;\; OR\;\; 1) P_i$ به صورت زیر باشد، کدام گزینه صحیح است؟
do{
Flag[i]=true;
While (flag[j]) {
If (turn==j) {
flag[i]=false;
while (turn==j)
:/*do nothing*/
Flag[i]=true;
}
}
/*critical section*/
Turn = j;
flag[i]=false;
/*remainder section*/
} while (true);
1 شرط پیشرفت ممکن است نقض شود.
2 شرط انتظار محدود ممکن است نقض شود.
3 شرط انحصار متقابل ممکن است نقض شود.
4 هر سه شرط انحصار متقابل، انتظار محدود و پیشرفت همواره تضمین میشود.
گزینه 4 صحیح است.
این الگوریتم تلاش چهارم Dekker است. مراحل این الگوریتم به صورت زیر است:
1- Set کردن flag فرایند و کنترل flag فرایند مقابل.
2- اگر flag مقابل بالا بود به اندازه زمان تصادفی flag فرایند پایین میرود (false میشود) و مجدد بالا میرود.
3- در نهایت ورود به ناحیه بحرانی.
این الگوریتم تمامی شروط انحصار متقابل، انتظار محدود و پیشرفت را تضمین میکند.
آسان یک کامپیوتر دارای m چاپگر از یک نوع است. این چاپگرها به وسیله 3 پردازه A و B و C استفاده میشوند که در زمان بیشترین نیاز (حداکثر تقاضا) به ترتیب به 3 و 4 و 6 چاپگر نیاز دارند. کمترین مقدار m که برای آن هیچ وقت در این کامپیوتر بن بست پیش نیاید چند است؟ بن بست
1 10
2 11
3 12
4 13
گزینه 2 صحیح است.
راه حل بدون استفاده از فرمول:
فرض کنید همه فرآیندها منابع خود به جز یک منبع را در اختیار دارند یعنی فرایند A دو منبع، B سه منبع و C پنج منبع در اختیار دارند که جمعا 10 منبع میشود. اگر یک منبع دیگر اضافه شود یکی از فرایندها میتواند کار خود را به اتمام برساند و منابعی که در اختیار دارد را آزاد کند.
بنابراین حداقل 11 منبع نیاز است که بنبستی رخ ندهد.
راه حل با استفاده از فرمول:
در یک سیستم با n فرایند و m منبع از یک نوع، اگر شرط زیر برقرار باشد بنبست رخ نمیدهد:
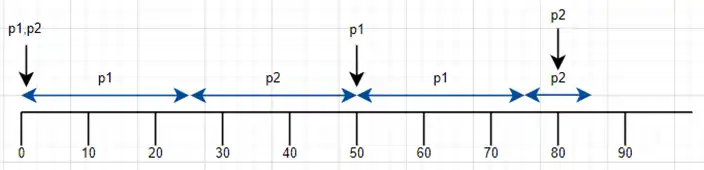
آسان دو پردازه متناوب با مشخصات زیر مفروض است. کدام گزینه بزرگترین مقدار x را برای پردازه 2 نشان میدهد به نحوی که زمانبندی قبضهای (نرخ یکنواخت) Rate Monotonic امکان پذیر باشد؟ فرآیندها و زمانبندی پردازندهها
Cpu Time
Period
25
50
$P_1$
x
80
$P_2$
1 20
2 25
3 30
4 35
گزینه 3 صحیح است.
زمانبندی تمام وقایع متناوب در یک سیستم بیدرنگ بر اساس رابطه زیر ممکن است قابل انجام باشد:
$\sum^m_{i=1}{\frac{t_i}{p_i}}\le 1$
در این رابطه m تعداد فرایندها، $t_i$ مدت زمان اجرای فرایند و $p_i$ دوره تناوب فرایند است.
توجه: یک سیستم بیدرنگ اگر با محاسبه این فرمول قابل زمانبندی نباشد به صورت عملی نیز قابل زمانبندی نیست. اما اگر در این فرمول صدق کند، به طور قطع نمیتوان گفت که این سیستم قابل زمانبندی است و باید برای آن نمودار گانت بکشیم و بررسی کنیم.
در این سوال چون بزرگترین مقدار x را خواسته بهتر است از گزینههایی که بیشترین مقدار را دارند بررسی را شروع کنیم.
این مقادیر از لحاظ تئوری درست است. برای اینکه ببینیم از لحاظ عملی نیز قابل زمانبندی است یا خیر، نمودار گانت میکشیم.
با توجه به این نمودار واضح است که این زمانبندی قابل انجام نیست. زیرا فرایند p2 باید در لحظه 80 کار خود را به پایان میرساند، نه 85. (چون دوره تناوب این فرایند 80 ثانیه است و در لحظه 80 رویداد راه انداز p2 مجدد رخ میدهد)
این مقادیر از لحاظ تئوری درست است. برای اینکه ببینیم از لحاظ عملی نیز قابل زمانبندی است یا خیر، نمودار گانت میکشیم.
با توجه به نمودار بالا مهلتهای زمانی فرایندها برآورده شده است زیرا در لحظه 400 به تناوب رسیدهاند و فرایندها مجدد یکدیگر را ملاقات کردهاند.
چون در صورت سوال بزرگترین x را خواسته و گزینههای دیگر از 30 کمترند، پس پاسخ سوال گزینه 3 است.
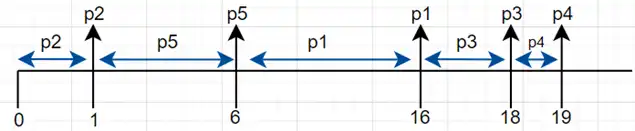
متوسط در یک الگوریتم برنامه ریزی اولویتدار که پنج پردازه و اولویتهای آنها به صورت زیر است، وجود دارد. میانگین زمان انتظار چند میلی ثانیه است؟ فرآیندها و زمانبندی پردازندهها
فرض کنید که هر چه مقدار اولویت کمتر باشد، اولویت پردازه بیشتر است. یعنی پردازه $P_4$ دارای کمترین اولویت و پردازه $P_2$ دارای بیشترین اولویت است.
پردازه
زمان
اولویت
$P_1$
$10_{ms}$
3
$P_2$
$1_{ms}$
1
$P_3$
$2_{ms}$
4
$P_4$
$1_{ms}$
5
$P_5$
$5_{ms}$
2
1 $7_{ms}$
2 $8_{ms}$
3 $8/2_{ms}$
4 $7/75_{ms}$
اگر زمان ورود فرایند ها را ندادند، صفر در نظر بگیرید.
نمودار گانت این فرایند به صورت زیر است:
میانگین زمان انتظار فرایندها $=\frac{\sum^n_1{\mathrm{(}\text{زمان}\mathrm{\ }\text{خروج}\mathrm{)-(}\text{زمان}\mathrm{\ }ورود\mathrm{)}-\mathrm{(}\text{زمان}\mathrm{\ }\text{پردازش}\mathrm{)}}}{n}$
میانگین زمان انتظار فرایندها $=\frac{\left(16-10-0\right)+\left(1-1-0\right)+\left(18-2-0\right)+\left(19-1-0\right)+(6-5-0)}{5}=\frac{6+0+16+18+1}{5}=8.2$
پاسخ تشریحی تستهای درس پایگاه داده کنکور کامپیوتر ۱۴۰۰
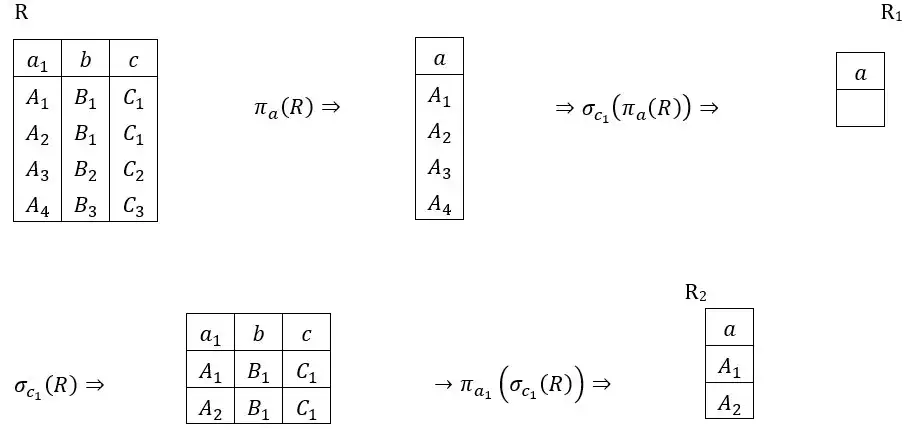
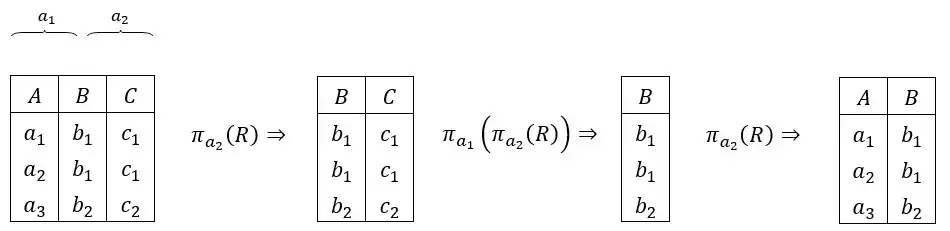
متوسط هم ارزیهای جبر رابطهای زیر را در نظر بگیرید. این هم ارزیها ممکن است همواره درست باشند، در بعضی شرایط درست باشند، یا همواره نادرست باشند. در این عبارتها، R یک رابطه (Relation)، ci ها شرطهایی بر روی R و ai ها زیر مجموعههایی از صفتهای R هستند. کدام هم ارزی همواره درست است؟ پایگاه داده رابطهای
گزینه 2: $\pi$ خاصیت جابجایی ندارد و $\pi$ درونی به $\pi$ بیرونی وابسته است و در $\pi_{a_1}\left(\pi_{a_2}\left(R\right)\right)$ باید $a_1\subseteq a_2$ باشد. وگرنه تهی برمیگرداند.
بنابراین تنها درصورتیکه
$\left\{ \begin{array}{c} a_1\subseteq a_2 \\ a_2\subseteq a_1 \end{array} \right. $ $a_1=a_2\Leftarrow$ برقرار باشد این گزینه صحیح است.
گزینه 3) مثال نقض:
همانطور که در مثال آمده دو جدول $R_2\neq R_1$
گزینه 4)
اگر $a_1$ شامل فقط ستون $B$ و بطور کلی $a_1\subseteq a_2$ بود آنگاه رابطه همارزی درست بود.
دشوار رابطه $R(A,B,C,D)$ و این وابستگیهای تابعی را در نظر بگیرید: $B \to C~ ;~CD \to B$ کدام گزینه در مورد رابطه R درست است؟ طراحی پایگاه داده
1 R در 2NF نیست.
2 R در BCNF است.
3 R در 2NF است، اما در 3NF نیست.
4 R در 3NF است، اما در BCNF نیست.
گزینه 4 صحیح است. A و D در سمت راست رابطه وجود ندارند پس قطعا جزئی از کلید کاندید میباشند. با گسترش A و D بهتنهایی نمیتوان به R رسید بنابراین برای پیدا کردن کلید کاندید B و C را که در سمت چپ رابطه داریم را هرکدام بهتنهایی به AD اضافه میکنیم. اگر به کل R رسیدیم کلید کاندید است.
اضافه کردن B به D و A
$\left. \begin{array}{c} B\to C \\ \text{جزء}\mathrm{\ }\text{کلید}\ A,B,D \end{array} \right\}\Rightarrow\text{کلید}\mathrm{\ }\text{کاندید}\mathrm{\ }\text{است}\ ABD $
[غیرکلید $\rightarrow$ جزء کلید] نداریم $\Leftarrow$ 2NF است.
* در این رابطه کلاً غیرکلید نداریم و A و B و C و D همگی جزء کلید هستند. B در کلید کاندید ABD و C در کلید کاندید ACD هردو جزء کلید محسوب میشوند.
[غیرکلید $\rightarrow$ غیر کلید] نداریم $\Leftarrow$ 3NF است.
[جزء کلید $\rightarrow$ جزء کلید] داریم $\Leftarrow$ BCNF نیست.
توجه: از همان ابتدا بعد از پیدا کردن کلیدهای کاندید با توجه به اینکه هیچ غیرکلیدی نداشتیم میتوان فهمید رابطه 3NF و 2NF است.
دشوار رابطه $R(A,B,C,D,E)$ و این وابستگیهای تابعی را در نظر بگیرید : $AB \to CDE ~; ~E \to BC$ تعداد کلیدهای کاندید R چند تاست؟ طراحی پایگاه داده
1 1
2 2
3 3
4 4
گزینه 2 صحیح است. A سمت راست رایطه نداریم. بنابراین قطعا جزئی از کلید است. با گسترش A به تنهایی نمیتوان به کل R رسید پس از سمت چپ R برای یافتن کلید کاندید B و E را امتحان میکنیم.
3 $\mathrm{\Pi}_{SID}\left(Membership\right)-\ \mathrm{\Pi}_{SID}(Membership-\ \mathrm{\Pi}_{SID.IID}\left(Favorite\ Field\bowtie o f f e r e d\ Field\right))$
4 $\mathrm{\Pi}_{SID}\left(Membership\right)-\ \mathrm{\Pi}_{SID}\lfloor\mathrm{\Pi}_{SID.Field}\left(Membership\bowtie o f f e r e d\ Field\right)-Favorite\ Field\rfloor$
گزینه 4 صحیح است.
کاربر به تمام رشتههایی که مؤسسهای که ثبت نام کرده است ارائه میدهد، علاقه دارد.
گزینه 1) id دانشجویانی را برمیگرداند که در مؤسسه ای که عضو هستند حداقل یک علاقهمندی دارند. (نادرست)
گزینه 2) id دانشجویانی را برمیگرداند که در مؤسسه ای که عضو هستند هیچ علاقهمندی ندارند. (نادرست)
گزینه 3) id دانشجویانی را برمیگرداند که در مؤسسه ای که عضو هستند حداقل یک علاقهمندی دارند. (نادرست)
گزینه 4) با توجه به رابطهی تقسیم $A\div B=\pi_x\left(A\right)-\pi_x\left(\left(\pi_x\left(A\right)\times B\right)-A\right)$ این رابطه همان تقسیم است و id دانشجویانی که به همه دروس ارائه شده مؤسسهای که عضو آن هستند را برمیگرداند.
دشوار حاصل تجزیه رابطه زیر براساس 3NF چند رابطه خواهد بود؟ طراحی پایگاه داده
$R = (A,B,C,D,E)$
$A \to B,C$
$B,C \to A,D$
$D \to E$
1 1 رابطه
2 2 رابطه
3 3 رابطه
4 4 رابطه
گزینه 2 صحیح است.
E و D و C و B و A همگی در سمت راست رابطه وجود دارند. برای یافتن کلید از کمترین های سمت چپ مانند A امتحان میکنیم.
جواب تشریحی تستهای درس نظریه زبانها و ماشینها کنکور کامپیوتر ۱۴۰۰
متوسط کدامیک از گزارههای زیر درست است؟ خانواده زبانهای بازگشتی و شمارش پذیر بازگشتی
1 مجموعه تمام ماشینهای تورینگ روی یک الفبا ناشمارا است.
2 مجموعه تمام زبانهای تصمیم ناپذیر روی یک الفبا ناشمارا است.
3 مجموعه همه رشتههای تعریف شده روی یک الفبا ناشمارا است.
4 مجموعه تمام زبانهای نامنظم روی یک الفبا شمارا است.
گزینه 2 صحیح است.
مجموعه تمام ماشینهای تورینگ شمارا هستند (حذف گزینه 1).
مجموعه تمام رشتههای تعریف شده روی یک الفبا همان $\sum^\ast$ است و ما میدانیم که $\sum^\ast$ مجموعهای شماراست (حذف گزینه 3).
کل زبانهای قابل تعریف روی الفبا ناشمارا و زبانهای منظم شمارا هستند. حال میدانیم که اگر یک مجموعه شمارا را از یک مجموعه ناشمارا کم کنیم، مجموعه حاصل همچنان ناشمارا خواهد بود. اگر از مجموعه کل زبانها، مجموعه زبانهای منظم را کم کنیم، مجموعه حاصل شامل کلیه زبانهای نامنظم است که ناشمارا نیز هست (حذف گزینه 4)
دشوار سه زبان $L_3$, $L_2$, $L_1$ با تعاریف زیر مفروضند. کدام گزاره صحیح است؟ خصوصیات زبانهای مستقل از متن
1 $L_2$ و $L_3$ هر دو از نوع مستقل از متن قطعی هستند ولی $L_1$ از این نوع نیست.
2 $L_2$ مستقل از متن قطعی است ولی $L_1$ مستقل از متن غیرقطعی است.
3 $L_2$ مستقل از متن قطعی و $L_3$ مستقل از متن غیرقطعی است.
4 هر سه زبان از نوع مستقل از متن هستند.
گزینه 3 صحیح است.
بررسی زبان ${L}_\mathbf{1}$:
در قسمت w اگر بخواهیم تعداد a و b برابری داشته باشیم باید به ازای هر a که میخوانیم، b نیز وجود داشته باشد تا به این طریق بتوانیم مستقل از متن بودن آن را تشخیص دهیم اما پس از w رشته $o^n$ آمده است. ما اکنون معیاری جهت سنجش تعداد nتا o که برابر تعداد a یا b هست نداریم زیرا این معیار را جهت برابری تعداد a و b به اندازه n، مصرف کردیم در نتیجه زبان داده شده مستقل از متن نیست (حذف گزینه 2 و 4).
بررسی زبان ${L}_\mathbf{2}$:
برای اینکه بفهمیم این زبان مستقل از متن هست یا خیر یک روش این است که سعی کنیم ماشین پشتهای آن را بکشیم. اکنون همین کار را میکنیم.
همانطور که مشاهده میکنید میتوان به صورت فوق ماشین را به راحتی کشید. اگر دقت کنید میبینید که ماشین رسم شده DPDA است در نتیجه این زبان مستقل از متن قطعی است.
بررسی زبان ${L}_\mathbf{3}$:
روش دیگر تشخیص مستقل از متن بودن یک زبان، نوشتن گرامر مستقل از متن برای آن زبان است. اکنون همین کار را میکنیم.
در نتیجه متوجه میشویم که زبان داده شده مستقل از متن است. اما به دلیل وجود قاعده $S\rightarrow S_1|S_2$ که عدم قطعیت به وجود میآورد، میتوان گفت که این زبان غیرقطعی است (حذف گزینه 1).
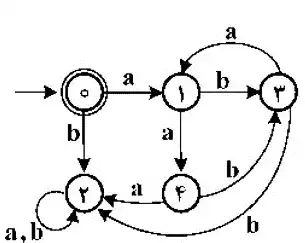
متوسط گرامر زیر چه زبانی را تولید میکند؟ ($\varepsilon$ بیانگر رشته تهی است.) ماشینهای تورینگ
بر اساس متن درس میدانیم که زبانهای مستقل از متن قطعی تحت اجتماع بسته نیستند در نتیجه این گزاره غلط است.
بررسی گزاره د:
بر اساس متن درس میدانیم که زبانهای شمارش پذیر بازگشتی (RE) تحت مکمل گیری بسته نیستند. در نتیجه این گزاره غلط است.
آسان اگر M یک ماشین حالت متناهی قطعی (DFA) باشد، میگوییم دو رشته x و y نسبت به M با هم معادلند، هرگاه $\left(\mathrm{s,y}\right) \begin{array}{c}\mathrm{*} \\ {{\mathop{\longrightarrow}\limits_{\mathrm{\ \ \ M\ \ \ \ }}}} \end{array}\mathrm{q}\mathrm{\Leftrightarrow }\left(\mathrm{s,x}\right) \begin{array}{c}\mathrm{*} \\ {{\mathop{\longrightarrow}\limits_{\mathrm{\ \ \ \ M\ \ \ \ }}}} \end{array}{q}$، که در آن s حالت شروع و q یک حالت دلخواه ماشین است. کلاسهای همارزی رشتهها نسبت به ماشین روبهرو کدام است؟ ماشینهای متناهی
اگر حالات مشابهی در ماشین نباشد (حالاتی که با ورودیهای یکسان به حالات مشابه میروند) آنگاه کوتاهترین رشتهای که به وسیله آن وارد یک state میشویم، نماینده کلاس همارزی آن state خواهد بود.
هیچیک از حالتهای 1 و 2 و 3 و 4 باهم معادل نیستند زیرا به ازای ورودیهای یکسان، حالت بعدی یکسانی ندارند، در نتیجه ماشین داده شده ساده نمیشود و این بدان معناست که کلاسهای همارزی هر حالت به صورت زیر میباشد:
Q4
Q3
Q2
Q1
Q0
$[aa]$
$[ab]$
$[b]$
$[a]$
$[\varepsilon]$
روش دوم: استفاده از دوره های نکته و تست درس های کنکور کامپیوتر
دوره های نکته و تست درسهای کنکور کامپیوتر برای آشنایی و تسلط بر تستهای کنکور تهیه شدهاند. دوره نکته و تست هر درس شامل تمامی تستهای کنکور آن درس به همراه پاسخ تشریحی است. برای آشنایی بیشتر با هر دوره میتوانید از لینکهای زیر استفاده کنید.
چگونه می توانم به جواب تشریحی کنکور کامپیوتر ۱۴۰۰ دسترسی داشته باشم؟
دو روش: (۱) پلتفرم آزمون (۲) دورههای نکته و تست
آیا منابعی برای دروس کنکور کامپیوتر وجود دارد؟
بله میتوانید از دورههای درس کنکور کامپیوتر استفاده کنید.
چگونه می توانم کلید کنکور ارشد کامپیوتر ۱۴۰۰ را داشته باشم؟
شما با مراجعه به صفحه دفترچههای کنکور کامپیوتر میتوانید به پاسخ کلیدی تمامی کنکورهای کامپیوتر دسترسی رایگان داشته باشید.
همچنین هر گونه سوالی در مورد کلاسهای آنلاین کنکور کامپیوتر و یا تهیه فیلمها و یا رزرو مشاوره تک جلسهای تلفنی با استاد رضوی دارید میتوانید به طرق زیر از تیم پشتیبانی بپرسید:

 ارشد کامپیوتر چیست؟
این مقاله عالی به معرفی ارشد کامپیوتر میپردازد و درباره آینده رشته کامپیوتر و نحوه اپلای کردن توضیح میدهد و آیتیمعرفی فناوری اطلاعات (IT) - 7 دلیل برای انتخاب رشته آی تی در دانشگاه
ارشد کامپیوتر چیست؟
این مقاله عالی به معرفی ارشد کامپیوتر میپردازد و درباره آینده رشته کامپیوتر و نحوه اپلای کردن توضیح میدهد و آیتیمعرفی فناوری اطلاعات (IT) - 7 دلیل برای انتخاب رشته آی تی در دانشگاه آی تی چیست و چگونه پس از ظهور توانست در مدت فقط 20 سال تمام دنیا را فرا بگیرد و اکثر پول دنیا را ببلعد و پرطرفدارترین و پر درآمدترین مشاغل دنیا را در بر گیرد، در این صفحه به بررسی این موضوعات پرداخته شده برای هر درس را شامل میشود، بلکه محیطی برای ایجاد آزمونهای شبیهسازی شده، رقابت با دیگر دانشجویان و… فراهم میآورد. برای کسب اطلاعات بیشتر درباره این پلتفرم میتوانید به صفحه پلتفرم آزمون مراجعه کنید.
آی تی چیست و چگونه پس از ظهور توانست در مدت فقط 20 سال تمام دنیا را فرا بگیرد و اکثر پول دنیا را ببلعد و پرطرفدارترین و پر درآمدترین مشاغل دنیا را در بر گیرد، در این صفحه به بررسی این موضوعات پرداخته شده برای هر درس را شامل میشود، بلکه محیطی برای ایجاد آزمونهای شبیهسازی شده، رقابت با دیگر دانشجویان و… فراهم میآورد. برای کسب اطلاعات بیشتر درباره این پلتفرم میتوانید به صفحه پلتفرم آزمون مراجعه کنید.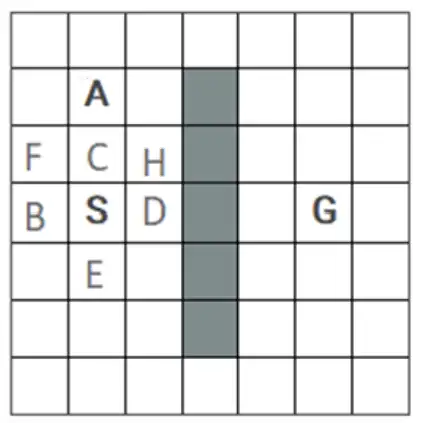



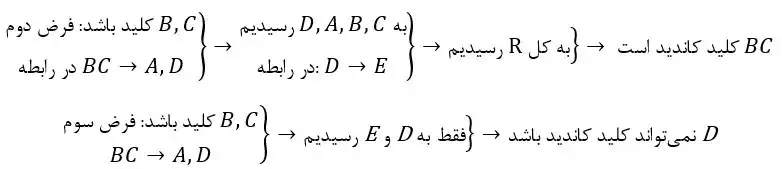
 از نگاه دانشجویان، قدرت بیان فوق العاده استاد رضوی و پوشش ۱۰۰ درصدی تمامی سرفصلها، نکات و تستها، ویدیوهای حل تست ساختمان داده و طراحی الگوریتم را به بهترین ویدیو حل تست کشور در درس ساختمان و الگوریتم تبدیل کرده است. این فیلم پرطرفدارترین و پرفروشترین فیلم حل تست ساختمان داده و الگوریتم کشور است و هر سال بیش از ۶۰۰۰ نفر این فیلم را تهیه میکنند
از نگاه دانشجویان، قدرت بیان فوق العاده استاد رضوی و پوشش ۱۰۰ درصدی تمامی سرفصلها، نکات و تستها، ویدیوهای حل تست ساختمان داده و طراحی الگوریتم را به بهترین ویدیو حل تست کشور در درس ساختمان و الگوریتم تبدیل کرده است. این فیلم پرطرفدارترین و پرفروشترین فیلم حل تست ساختمان داده و الگوریتم کشور است و هر سال بیش از ۶۰۰۰ نفر این فیلم را تهیه میکنند
 بهترین دوره نکته و تست هوش مصنوعی کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست هوش و نحوه استفاده از نکته و تست هوش مصنوعی گفته شده
بهترین دوره نکته و تست هوش مصنوعی کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست هوش و نحوه استفاده از نکته و تست هوش مصنوعی گفته شده
 دوره نکته و تست پایگاه داده و ویژگیها و اهمیت دوره نکته و تست پایگاه داده و نحوه استفاده صحیح از نکته و تست پایگاه داده کنکور ارشد کامپیوتر و آیتی در این صفحه عالی توضیح داده شده است
دوره نکته و تست پایگاه داده و ویژگیها و اهمیت دوره نکته و تست پایگاه داده و نحوه استفاده صحیح از نکته و تست پایگاه داده کنکور ارشد کامپیوتر و آیتی در این صفحه عالی توضیح داده شده است
 بهترین دوره نکته و تست سیستم عامل در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست سیستم های عامل و نحوه استفاده از نکته و تست سیستم عامل گفته شده
بهترین دوره نکته و تست سیستم عامل در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست سیستم های عامل و نحوه استفاده از نکته و تست سیستم عامل گفته شده
 بهترین دوره نکته و تست شبکه کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست شبکه های کامپیوتری و نحوه استفاده از نکته و تست شبکه گفته شده
بهترین دوره نکته و تست شبکه کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست شبکه های کامپیوتری و نحوه استفاده از نکته و تست شبکه گفته شده
 دوره نکته و تست نظریه زبان ها و ماشین ها در این صفحه قرار گرفته و ویژگی ها و اهمیت دوره نکته و تست نظریه زبان ها و ماشین ها بررسی شده است
دوره نکته و تست نظریه زبان ها و ماشین ها در این صفحه قرار گرفته و ویژگی ها و اهمیت دوره نکته و تست نظریه زبان ها و ماشین ها بررسی شده است
 دوره نکته و تست سیگنال و سیستم و ویژگیهای نکته و تست سیگنال و نحوه استفاده صحیح از نکته و تست سیگنال کنکور ارشد کامپیوتر در این صفحه عالی توضیح داده شده
دوره نکته و تست سیگنال و سیستم و ویژگیهای نکته و تست سیگنال و نحوه استفاده صحیح از نکته و تست سیگنال کنکور ارشد کامپیوتر در این صفحه عالی توضیح داده شده
 بهترین دوره نکته و تست مدار منطقی کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست مدار منطقی و نحوه استفاده از نکته و تست مدار منطقی گفته شده
بهترین دوره نکته و تست مدار منطقی کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست مدار منطقی و نحوه استفاده از نکته و تست مدار منطقی گفته شده
 بهترین دوره نکته و تست الکترونیک دیجیتال کشور در این صفحه معرفی شده و اهمیت دوره نکته و تست الکترونیک دیجیتال و نحوه استفاده صحیح از دوره بیان شده است
بهترین دوره نکته و تست الکترونیک دیجیتال کشور در این صفحه معرفی شده و اهمیت دوره نکته و تست الکترونیک دیجیتال و نحوه استفاده صحیح از دوره بیان شده است
 بهترین دوره نکته و تست ریاضیات گسسته کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست گسسته و نحوه استفاده از نکته و تست گسسته گفته شده
بهترین دوره نکته و تست ریاضیات گسسته کشور در این صفحه معرفی و ویژگیها و اهمیت دوره نکته و تست گسسته و نحوه استفاده از نکته و تست گسسته گفته شده
 دفترچه سوالات کنکورهای ارشد کامپیوتر از اولین سال برگزاری تا کنکور 1403 به همراه کلید نهایی سازمان سنجش در این صفحه بصورت رایگان قرار داده شده است تا بتوانید به راحتی و بدون صرف زمان زیاد برای جستجو در اینترنت، از دفترچه سوالات سالهای گذشته استفاده نمایند میتوانید تمامی آنها را بهصورت رایگان دانلود کنید.
دفترچه سوالات کنکورهای ارشد کامپیوتر از اولین سال برگزاری تا کنکور 1403 به همراه کلید نهایی سازمان سنجش در این صفحه بصورت رایگان قرار داده شده است تا بتوانید به راحتی و بدون صرف زمان زیاد برای جستجو در اینترنت، از دفترچه سوالات سالهای گذشته استفاده نمایند میتوانید تمامی آنها را بهصورت رایگان دانلود کنید.
 درس طراحی الگوریتم یکی از مهمترین و بنیادیترین دروس رشته کامپیوتر است. هدف از این درس، معرفی روشهای مختلف طراحی الگوریتمها برای حل مسائل گوناگون است، در این صفحه به معرفی و آموزش طراحی الگوریتم پرداخته شده است. و ساختمان دادهآموزش ساختمان داده و الگوریتم
درس طراحی الگوریتم یکی از مهمترین و بنیادیترین دروس رشته کامپیوتر است. هدف از این درس، معرفی روشهای مختلف طراحی الگوریتمها برای حل مسائل گوناگون است، در این صفحه به معرفی و آموزش طراحی الگوریتم پرداخته شده است. و ساختمان دادهآموزش ساختمان داده و الگوریتم هر ساختمان داده یک نوع فرمت ذخیرهسازی و مدیریت دادهها در کامپیوتر است، که امکان دسترسی و اصلاح کارآمد آن دادهها را برای یکسری از الگوریتمها و کاربردها فراهم میکند، در این صفحه به بررسی و آموزش ساختمان داده و الگوریتم پرداخته شده است، شبکهجامعترین آموزش درس شبکه های کامپیوتری
هر ساختمان داده یک نوع فرمت ذخیرهسازی و مدیریت دادهها در کامپیوتر است، که امکان دسترسی و اصلاح کارآمد آن دادهها را برای یکسری از الگوریتمها و کاربردها فراهم میکند، در این صفحه به بررسی و آموزش ساختمان داده و الگوریتم پرداخته شده است، شبکهجامعترین آموزش درس شبکه های کامپیوتری درس شبکه های کامپیوتری یکی از مهمترین و بنیادیترین دروس رشته کامپیوتر است، با توجه به اینکه اینترنت امروزی بزرگترین سیستم مهندسی ساخت دست بشر در تمام طول تاریخ است، آشنایی با شبکههای کامپیوتری برای تمامی علاقهمندان و دانشجویان رشته کامپیوتر الزامی است، در این راستا در این صفحه به معرفی شبکههای کامپیوتری پرداخته شده است، هوش مصنوعیدرس هوش مصنوعی
درس شبکه های کامپیوتری یکی از مهمترین و بنیادیترین دروس رشته کامپیوتر است، با توجه به اینکه اینترنت امروزی بزرگترین سیستم مهندسی ساخت دست بشر در تمام طول تاریخ است، آشنایی با شبکههای کامپیوتری برای تمامی علاقهمندان و دانشجویان رشته کامپیوتر الزامی است، در این راستا در این صفحه به معرفی شبکههای کامپیوتری پرداخته شده است، هوش مصنوعیدرس هوش مصنوعی این صفحه عالی به معرفی درس هوش مصنوعی از جمله پیش نیازهای درس هوش مصنوعی، سرفصل و منابع درس هوش مصنوعی و فیلمهای آموزشی درس هوش مصنوعی پرداخته شده و ... است. داوطلبان برای پاسخگویی به این سوالات نیاز به دانش عمیق و تسلط بر مباحث مورد نظر دارند و لازم است که از منابع مناسبی استفاده کنند پس استفاده از دوره نکته و تست و پلتفرم آزمون را به شما پیشنهاد میکنیم.
این صفحه عالی به معرفی درس هوش مصنوعی از جمله پیش نیازهای درس هوش مصنوعی، سرفصل و منابع درس هوش مصنوعی و فیلمهای آموزشی درس هوش مصنوعی پرداخته شده و ... است. داوطلبان برای پاسخگویی به این سوالات نیاز به دانش عمیق و تسلط بر مباحث مورد نظر دارند و لازم است که از منابع مناسبی استفاده کنند پس استفاده از دوره نکته و تست و پلتفرم آزمون را به شما پیشنهاد میکنیم.




































