پاسخ تشریحی ساختمان داده و الگوریتم ارشد کامپیوتر 1403
پاسخ تشریحی ساختمان داده و الگوریتم کنکور ارشد کامپیوتر 1403 در این صفحه بصورت رایگان قرار گرفته و روش های دسترسی به پاسخ تشریحی کنکور سال های قبل گفته شده
فیلم پاسخ تشریحی ساختمان داده و طراحی الگوریتم کنکور ارشد کامپیوتر ۱۴۰۳
فیلم پاسخ تشریحی ساختمان داده و طراحی الگوریتم کنکور ارشد آیتی ۱۴۰۳
پاسخ تشریحی ساختمان داده و الگوریتم کنکور ارشد کامپیوتر ۱۴۰۳
دشوار گوییم $H=\left\{h:U\to \left.\left\{0,\ 1,\ 2,\dots ,\ m-1\right\}\right|\ \text{تابع}\mathrm{\ }\text{است}\mathrm{\ }h\right\}$ یک خانواده از درهمسازهای سراسری (universal) است، هرگاه برای هر $h \in H$ و $K_1,K_2\in U$ داشته باشیم $Pr\left(h\left(k_1\right)=h\left(k_2\right)\right)\le \frac{1}{m}$ . اگر مجموعه $H$ که فقط متشکل از توابعی به شکل $h_{ab}\left(x\right)=\left(\left(ax+b\right){\mathrm{mod}\ n\ }\right){\mathrm{mod}\ 20\ }$، یک خانواده درهمساز سراسری باشد، آنگاه در مورد تعداد عناصر $H$ چه میتوان گفت؟ درهمسازی
1 $H$ میتواند 380 عضو داشته باشد.
2 $H$ میتواند 420 عضو داشته باشد.
3 $H$ میتواند 506 عضو داشته باشد.
4 $H$ میتواند 650 عضو داشته باشد.
ابتدا نیاز داریم تعریف درهمساز سراسری (Universal Hashing) را بدانیم.
یکی از مشکلاتی که در روش زنجیرهسازی (درهم سازی باز یا آدرس دهی بسته) رخ میدهد این است که چون تابع درهم سازی را از قبل داریم، میتوان مجموعهای از n کلید پیدا کرد که همه به یک درایه فرستاده شود و در نتیجه زمان ریکاوری عناصر از $\theta\left(n\right)$ خواهد بود، حال یک کاربر مخرب میتواند از این موضوع سوءاستفاده کند. هر تابع هش ایستا در برابر این بدرفتاریها بشدت آسیبپذیر است. تنها راه مؤثر برای این شرایط این است که تابع هش بصورت تصادفی و مستقل از مقادیری که قرار است ذخیره شوند انتخاب شود. این رویکرد هش تصادفی (random hashing) خوانده میشود، یکی از انواع این رویکرد درهم ساز سراسری (universal hashing) است که اثبات میشود بطور متوسط عملکرد قابل قبولی دارد.
$H=\left\{h_1,h_2,\ldots,h_i,\ldots,h_K\right\}:$
- فرض کنید H خانواده محدود از توابع درهمسازی است، چنین خانوادهای را سراسری میگوییم اگر:
وقتی یک تابع درهم ساز $h\in H$ بصورت تصادفی از h انتخاب میکنیم داشته باشیم:
بیان 1: تعدداد توابعی که در این خانواده هستند و K و L مارا به یک خانه مپ میکشد حداکثر $\frac{\left|H\right|}{m}$ باشد.
توضیح بیشتر: دو به دو کلیدها را چک میکنیم، برای هرجفت کلید در حداکثر $\frac{\left|H\right|}{m}$ ای / تا از توابع $h_i$ مان تصادم وجود داشته باشد.
تفسیر جمله بالا: یعنی K و L در هشهای مختلف به خانههای مختلف توزیع شوند، میگوید اینگونه نباشد که توی اکثر این توابع به یک خانه مپ بشوند (یعنی یکنواخت پخش بشوند)
بیان 2: احتمال وقوع برخورد بین کلیدهای متفاوت K و L کمتر مساوی $\frac{1}{m}$ باشد: $h\left(L\right)=h\left(K\right)\le\frac{1}{m}$ بیان دیگر این احتمال بهصورت زیر است:
اگر همه اینها کوچکتر مساوی $\frac{1}{2}$ شوند، H سراسری است.
* توجه: با استفاده از تعریف اول نیز میتوان سراسری بودن یا نبودن H را چک کرد.
بیان 1: تعداد توابعی که در این خانواده هستند و K و L را به یک خانه مپ میکنند حداکثر $\frac{\left|H\right|}{m}$ باشد.
توضیح بیشتر: دو به دو کلیدها را چک میکنیم، برای هرجفت کلید در حداکثر $\frac{\left|H\right|}{m}$ ای / تا از توابع $h_i$ مان تصادم وجود داشته باشد.
مثال: آیا خانواده H زیر سراسری است؟ فرض کنید Hash Table، سه خانه دارد.
حال باید دید که چگونه تابع هش سراسری را تعریف کرد که ویژگیهای گفته شده را داشته باشد.
تابع هش Carter-Wegman: خانوادهای از توابع Hash است که ورودی آن اعداد صحیح است و به صورت روبهرو تعریف میشود: $h_{a,b}\left(x\right)=\left(\left(ax+b\right){mod\ p\ }\right){mod\ m\ }$
که در آن m تعداد حفرههاست و p عدد صحیح است. p باید از تمام اعداد مجموعه جهانی اعداد صحیح که میتوانیم به ورودی تابع Hash بدهیم بزرگتر باشد؛ بهعبارت دیگر:
درنتیجه عدد p را باید طوری انتخاب کنیم که بهاندازهی کافی بزرگ باشد.
در ادامه $ {\mathbb{Z}}_p$ را مجموعهی $ \{0,1,\dots ,p-1\}\ $ تعریف میکنیم و $ {\mathbb{Z}}^*_p$ را مجموعهی $\left\{1,\dots ,p-1\right\}$ تعریف میکنیم. حال با انتخاب هر a و b بهطوری که $a\in {\mathbb{Z}}^*_p$ و $b\in {\mathbb{Z}}_p$ است، تابع هش $h_{ab}$ را تعریف میکنیم که عضو خانوادهی هش سراسری $H_{pm}$ است.
فرض میشود p از تعداد حفرهها (m) بزرگتر است. (در غیراینصورت اصلاً نیازی به استفاده از توابع Hash نداریم و میتوانیم از direct address استفاده کنیم.)
اثبات میشود که $H_{pm}$ بهازای p های اول یک خانواده هش سراسری است.
(اثبات در توضیحات بیشتر)
در این سؤال داریم $h_{ab}\left(x\right)=\left(\left(ax+b\right){mod n\ }\right){mod 20\ }$
در این سؤال تعداد حفرهها برابر 20 گرفته شده. باتوجه به تعریف خود سؤال از توابع هش سراسری که مطابق با آنچه میداینم هست، برای اینکه $h_{ab}(x)$ سراسری شود باید n عددی اول باشد. برای بهدست آوردن تعداد توابع خانوادهی هش سراسری H میدانیم هرجفت $(a,\ b)$ یک عضو خانواده را مشخص میکند، $a\in \left\{1,2,\dots ,p-1\right\}$ است که $p-1$ عضو دارد و $b\in \left\{0,1,\dots ,p-1\right\}$ است که p عضو دارد. طبق اصل ضرب تعداد اعضا برابر با $p \times (p-1)$ میباشد.
باتوجه به فرض $n \ge p$ داریم: $n\in \left\{23,29,31,\dots \right\}$
که با درنظر گرفتن $n=23$ داریم: $23\times 22=506$
که مطابق با گزینه 3 است. دقت کنید اگر در گزینهها $29 \times 28 = 812$ نیز قرار داشت آن گزینه درست بود امّا سایر گزینهها n را بهترتیب برابر $n=20$ و $n=21$ و $n=26$ گرفتند که فرض اول بودن n را نقض کردهاند.
گزینه 3 صحیح است.
مطالعهی بیشتر:
اثبات $H_{ab}$ اینکه خانوادهی هش سراسری است:
باید ثابت کنیم احتمال تصادم (Collision) برای هر تابع هش خانواده کوچکتر مساوی $\frac{1}{n}$ (n تعداد حفرهها) باشد، بهعبارت دیگر:
همچنین بدیهی است که در معادلههای I جواب $x=y$ بهازای $q=0$ اهمیتی ندارد و $q\neq 0$ است.
جفت $(K\ ,\ q)$ را Conflicting مینامیم بهشرطیکه $q\neq 0$ و $K\in {\mathbb{Z}}_p$ و $K+qn\in {\mathbb{Z}}_p$ باشد.
ادعای اول: بهطور کلی میتوان گفت که تعداد جفتهای Conflicting حداکثر $\frac{p\left(p-1\right)}{n}$ میباشد.
اثبات: برای K های ثابت میتوان گفت $K+qn\in \left\{0,1,2,\dots ,p-1\right\}$ است که نتیجه میدهد $qn\in \left\{-K,-K+1,\dots ,K+p-K\right\}$. یعنی مضارب n در بازهای بهطول p قرار دارند. حال سؤال این است که چند مقدار q حداکثر وجود دارد که qn عضو مجموعهی p عدد متوالی است؟
باتوجه به اینکه p عدد اول است و بهطور کلی p مضرب n نیست. حداکثر $\frac{p-1}{n}$ مضرب q وجود دارد. پس تا اینجا ثابت کردیم بهازای مقداری از K حداکثر $\frac{p-1}{n}$ مضرب q وجود دارد. باتوجه به اینکه $K\in {\mathbb{Z}}_p$ است، تعداد جفت Conflicting نهایتاً $\frac{p(p-1)}{n}$ است.
ما جفت $(a,\ b)$ را جفت $bad$ میگوییم اگر جفت $(K,\ q)$ Conflicting وجود داشته باشد بهطوری با جایگذاری مقادیر K و q در دستگاه $(a,\ b)$ ،I بهدست آید.
ادعای دوم: بهازای هرجفت $(K,\ q)$ ،Conflicting و جایگذاری آن در دستگاه I فقط و فقط یک جفت $(a,\ b)$ وجود دارد.
اثبات: باتوجه به قضایای نظریه اعداد میتوان گفت بهازای p های اول دستگاه معادلاتی $\left\{ \begin{array}{c}ax+b\ \begin{array}{c}p \\ \equiv \end{array}\ K\ \ \ \ \ \ \ \ \ \ \\ ay+b\ \begin{array}{c} p \\ \equiv \end{array}\ K+qn \end{array} \right.$ حتماً یک جواب دارد که به شکل $\begin{array}{c}a=\left(qn{\left(y-x\right)}^{-1}\right)\mathrm{mod}\ p \\ b=\left(K-ax\right)\mathrm{mod}\ p\ \ \ \ \ \ \ \ \ \ \end{array}$ میباشد.
یعنی بهازای p اول، m و $K,\ q$ و $x,\ y$ مشخص ما یک جفت $(a,\ b)$ جواب گرفتیم.
نتیجهگیری نهایی: ابتدا اثبات کردیم که حداکثر $\frac{p(p-1)}{n}$ جفت $(K,\ q)$، Conflictingوجود دارد که هرکدام از آنها درصورتیکه p عددی اول باشد، دقیق یک جفت $(a,\ b)$ را نتیجه میدهد؛ که به این جفت $bad$ ،$(a,\ b)$ میگوییم. هرجفت $bad$ منجر به یک تصادم میشود.
$h_{a,b}\left(x\right)=h_{a,b}\left(y\right)$
و از آنجایی که تعداد جفت Conflicting برابر تعداد جفت بد است و تعداد Conflicting برابر $\le \frac{p(p-1)}{n}$، میتوان نتیجه گرفت که تعداد تصادم $\le \frac{p(p-1)}{n}$ است که درصورت محاسبهی احتمال داریم:
متوسط آرایه $A$ بهطول $n$ را $-K$ مرتب میکنیم. هرگاه برای هر $i$ که $k \le i \le n-k$ داشته باشیم $A\left[i-k\right]\le A\left[i\right]\le A\left[i+k\right]$، یعنی آرایه $A$ به $k$ لیست مرتب که هرکدام تقریباً $\frac{n}{k}$ عنصر دارند افراز میشود. فرض کنید $A$ یک آرایه $-k$ مرتب بهطول $n$ باشد. سریعترین الگوریتم برای تبدیل این آرایه به یک آرایه $-1$ مرتب، از چه مرتبه زمانی است؟ مرتبسازی
1 $O\left(n\right)$
2 $O\left(n\ k\right)$
3 $O\left(k\ {\mathrm{log}\ n\ }\right)$
4 $O\left(n\ {log\ k\ }\right)$
سؤال 57) گزینه 3 صحیح است.
* تعداد دسته $\times$ log تعداد کل عناصر $=$ هزینه ادغام تعدادی لیست مرتب
برای اثبات * به تست 146 نکته و تست ساختمان استاد رضوی مراجعه کنید.
متوسط فرض کنید $G=(V\ ,\ E)$، یک گراف همبند وزندار باشد. چند مورد از گزارههای زیر درست است؟ سوالات ترکیبی
- اگر وزن تمام یالهای گراف باهم برابر باشد، میتوان درخت فراگیر کمینه آنرا با الگوریتمی از مرتبه $O(|E|)$ بهدست آورد. - اگر $G$ گراف جهتدار باشد، یافتن دور در این گراف را میتوان در مرتبه $O(|V|+|E|)$ محاسبه کرد. - چنانچه وزن یالهای گراف دوبهدو متمایز باشند، الگوریتم پریم و کروسکال دارای جواب یکسانی هستند. - الگوریتم پریم را میتوان بهنحوی پیادهسازی کرد که همواره مرتبه آن بدتر از الگوریتم کروسکال نباشد.
1 1
2 2
3 3
4 4
سؤال 56) گزینه 4 صحیح است.
گزاره 1: اگر تمام یالهای گراف وزن یکسانی داشته باشند؛ هر درخت پوشایی یک درخت پوشای کمینه است. با استفاده از الگوریتمهای DFS و BFS میتوان یک درخت پوشا بهدست آورد که اینکار از مرتبهی:
گزاره 2: با استفاده از الگوریتم DFS میتوان متوجه شد که آیا در گراف دور داریم یا نه. به اینصورت که اگر یال back edge در درخت داشتیم حتماً دور داریم. دقت کنید تعداد دورها میتواند بیشتر از تعداد یال back edge باشد امّا گزاره پیچیدگی یافتن یک دور در گراف میخواهد که برابر مرتبهی DFS یعنی:
$O \left(\left|V\right|+\left|E\right|\right)$
میباشد.
این گزاره صحیح است.
گزاره 3: اگر وزن یالها دو به دو متمایز باشد، یک درخت پوشای کمینه موجود است که باعث میشود هم پریم هم کروسکال جواب یکسانی بدهند.
این گزاره صحیح است.
گزاره 4: الگوریتم پریم اگر با هیپ فیبوناچی پیادهسازی کنیم در گرافی که با لیست مجاورتی پیادهسازی شده است همواره بهتر از کروسکال جواب میدهد.
این گزاره صحیح است.
هر 4 گزاره صحیح است؛ درنتیجه گزینه 4 صحیح است.
دشوار رشتههایی که از دو طرف یکسان خوانده میشوند پالیندروم (Palindrome) نامیده میشوند (مانند abcba). برای محاسبه بزرگترین زیررشته پالیندروم یک رشته به طول n، یک الگوریتم پویا کارا بهترتیب از راست به چپ دارای چه مرتبه زمان و حافظه است؟ برنامه نویسی پویا
گزینه 1 توسط سنجش اعلام شده امّا گزینه 4 صحیح است.
الگوریتمهای مختلفی برای حل این سؤال وجود دارند که بهترین پیچیدگی زمانی را الگوریتم Manacher داراست. الگوریتم Manacher دارای پیچیدگی زمانی $O(n)$ و پیچیدگی فضایی $O(n)$ میباشد. الگوریتم Manacher یک الگوریتم برنامهنویسی پویا و کارا است. امّا طراح محترم این الگوریتم را بهطور کامل نادیده گرفته است. درنتیجه گزینه 4 صحیح است.
الگوریتم Manacher:
مسئله پیدا کردن بزرگترین زیررشتهی پالیندروم رشتهی ورودی است. مثلاً برای رشته ورودی “bananas” بزرگترین زیررشته پالیندروم “anana” است که خوانش از سمت چپ و راست یکی هستش.
فرض کنید رشتهای داریم که طول آن فرد است، مانند “abababa”. برای پیدا کردن پالیندرومهای فرد رشته میتوان ایندکسی را بهعنوان Center گرفت و سمت راست و چپ آن را باهم مقایسه کرد و درصورت برابری مقایسه را به ایندکسهای بعدی سمت راست و چپ گسترش داد و زمانی که نابرابری بهوجود آمد یا به انتها و ابتدای آرایه رسیدیم، رشته پالیندروم را اعلام کنیم. مثلاً، $\begin{array}{c}"abababa" \\ 0123456 \end{array}$ با گرفتن ایندکس 3 بهعنوان Center و چک کردن برابری ایندکس 2 با 4، ایندکس 1 با 5 و ایندکس 0 با 6 به رشتهی پالیندروم “abababa” میرسیم. حال میتوان با توسعهی الگوریتم تمام رشتههای پالیندروم فرد را پیدا کرد؛ بهاینصورت که تمام ایندکسهای الگوریتم را انتخاب میکنید و با الگوریتم گفته شده چک میکنیم آیا پالیندروم است یا خیر.
برای پیدا کردن پالیندرومهای زوج نیز الگوریتم مشابهی وجود دارد بهطوریکه بهجای Center گرفتن یک ایندکس فضای مابین ایندکسها را بهطور مجازی Center میگیریم. برای مثال در رشتهی $\begin{array}{c} "abaaba" \\ 012345 \end{array}$ اگر فضای بین 2 و 3 را Center بگیریم باید ایندکسهای 2 و 3 را باهم مقایسه و سپس درصورت برابری ایندکسهای 1 و 4 باهم مقایسه کرد و بههمینترتیب رشته پالیندروم زوج بهدست میآید. اگر بخواهیم برای رشته “abababa” تمام Center های موجود برای پالیندرومهای فرد و زوج را نشان داد داریم:
I
aI
bI
aI
bI
aI
bI
aI
$14$
$13$$12$
$11$$10$
$9$$8$
$7$$6$
$5$$4$
$3$$2$
$1$$0$
بهدلیل اینکه کل رشته یک زیررشته پالیندروم است Center هایی که بهشکل آینهای در رشته قرار دارند (مانند 8 و 6 یا 4 و 10) یک زیررشته پالیندروم میدهند که این یعنی با محاسبه رشتههای پالیندروم با Center گرفتن 3، میتوان رشتههای پالیندروم با Center گرفتن 11 بهدست آورد و نیازی به محاسبهی مجدد نیست.
استفاده از اطلاعات بهدست آمده ناشیاز Center گرفتن مکانهای قبلی باعث میشود مرتبهی الگوریتم Manacher خطی شود.
الگوریتم Manacher پالیندرومهای رشتههای بهطول فرد را پیدا میکند. برای اینکه این بتوان این الگوریتم را برای رشتههای زوج نیز استفاده کرد کافی است برای مثال رشته ورودي زوج “abaaba” به رشته “|a|b|a|a|b|a|” تبديل كرد و رشتههاي فرد ورودي مانند “abababa” به “|a|b|a|b|a|b|a” تبديل كرد که در این صورت تغييري در جواب مسئله بهوجود نميآيد. به رشته حاصل رشته تبدیل یافته می گوییم .
براي پیادهسازی الگوریتم باید آرایهای با نام P داشته باشیم که طول آن به اندازه ی طول رشته تبدیل یافته است. در انتهای اجرای الگوریتم هر ایندکس این آرایه برابر با طول رشتهی پالیندروم با گرفتن آن ایندکس از رشته به عنوان Center می شود .
برای رشتهی ورودی NBNNBR داریم:
$C$
$\downarrow$
I
RI
BI
NI
BI
NI
$0$
$0$$0$
$0$$0$
$0$$0$
$0$$0$
$0$$0$
$P : $
ابتدا Center را برابر ایندکس صفر میگیریم، و با گسترش از چپ و راست متوجه میشویم صفر رشته پالیندروم با Center گرفتن ایندکس صفر بهدست میآید و آرایه P دست نخورده باقی میماند. درادامه ایندکس یک را بهعنوان Center درنظر میگیریم:
$ C\;\;\;\;R$
$\downarrow \;\;\;\;\; \downarrow$
I
RI
BI
NI
BI
NI
$0$
$0$$0$
$0$$0$
$0$$0$
$0$$0$
$1$$0$
$P : $
که رشته پالیندروم “|N|” بهدست میآید که یک واحد از سمت راست و چپ گسترش پیدا کرده است که درنتیجه در آرایه P مقدار 1 را در ایندکس 1 میگذاریم. حال باتوجه به رشته پالیندروم فلگ جدیدی بهنام Right Boundary تعریف میکنیم که با R نشان میدهیم. R بالای آخرین کاراکتر زیر رشته پالیندروم است که از Center گرفتن ایندکسی بهدست میآید.
با جلو بردن C و Center گرفتن ایندکس دوم هیچ رشته پالیندرومی نداریم؛ در نتیجه آرایه P دست نخورده باقی می ماند و فلگ R هم نداریم.
با Center گرفتن ایندکس سوم داریم:
$R$
$C$
$\downarrow$
$\downarrow$
I
RI
BI
NI
BI
NI
$0$
$0$$0$
$0$$0$
$0$$0$
$3$$0$
$1$$0$
$P : $
رشتهی پالیندروم بهشکل “|N|B|N|” است. در ایندکس سوم آرایه P مقدار 3 را می گذاریم . فلگها نیز مشخص شدهاند.
حال درادامه اگر ایندکس چهارم را Center بگیریم:
$R$
$C$
$m$
$\downarrow$
$\downarrow$
$\downarrow$
I
RI
BI
NI
BI
NI
$0$
$0$$0$
$0$$0$
$0$$0$
$3$$0$
$1$$0$
$P : $
قبلاز محاسبهی گسترش از چپ و راست میدانیم طول رشتهی پالیندروم حداقل $min(P[mirror], R-C)$ میباشد. قبلاً بیان شد که در رشتههای پالیندروم خاصیت آینهای برقرار است. درحقیقت R مرز رشتهی پالیندروم را نشان میدهد. در شکل بالا ایندکس دوم که با m نشان داده شده است ایندکس آینهای چهارم در رشتهی پالیندروم “|N|B|N|” میباشد، که مقدار صفر دارد. در حالتهایی امکان دارد $P[mirror]$ بزرگتر باشد و شامل ایندکسهایی شود که در رشتهی پالیندروم با Center گرفتن مرکز رشته نباشد:
برای مثال داریم:
$R$
$C$
$\downarrow$
$\downarrow$
B
BA
CC
BA
BA
BA
$0$
$0$$0$
$0$$0$
$0$$0$
$2$$2$
$1$$0$
به مرحلهای رسیدیم که B را Center گرفتیم و رشتهی پالیندروم “BABAB” را بهدست آوردیم و فلگ R را مشخص کردیم. حال با Center گرفتن ایندکس بعدی یعنی A داریم:
مشاهده میشود که مقدار $P[mirror]$ معتبر نیست چون از رشتهی پالیندروم “BABAB” بیرون میزند و کاراکترهای دیگر را دربرمیگیرد؛ درنتیجه حد $R-C$ تعریف شده است که مقادیر بیشتر از $R-C$ برای طول رشتهی پالیندروم ایندکس جاری معتبر نیست.
باتوجه به موارد ذکر شده مثال اصلی را ادامه میدهیم:
حال باید برای ایندکسهای چپ و راست بزرگتر از 1 (یعنی ایندکس 7 و 3) برابری را چک کنیم چون مطمئنیم حداقل رشتهی پالیندروم حاصل طول 1 را دارد.
متوجه میشویم که رشتهی پالیندروم طولش 3 است. وقتی مقایسه از ایندکس R رد شد R را آپدیت میکنیم کهدر شکل بالا R اپدیت شده است: درحالحاضر رشتهی “|B|N|B|” پالیندروم حاصلاز Center گرفتن ایندکس 5 است. اگر الگوریتم را ادامه دهیم جواب بهشکل زیر میشود:
I
RI
BI
NI
BI
NI
$0$
$1$$0$
$1$$0$
$3$$0$
$3$$0$
$1$$0$
استفاده از اطلاعات قبلی و بهدست آمده مرتبهی الگوریتم را تا $O(n)$ بهبود میدهد. مرتبهی حافظه نیز $O(n)$ میباشد. درنهایت برای جواب باید بزرگترین عدد آرایه P برگردانده شود.
آسان فرض کنید $s$ رشتهای به طول $n$ باشد. میخواهیم بزرگترین زیررشته بهشکل $ww$ را در این آرایه بیابیم که طول آن را با (Longest Double String) LDS (S) نشان میدهیم. دراینصورت رابطه بازگشتی طول بزرگترین زیررشته (LDS) چیست؟ (توجه کنید LCS تابعی است که طول بزرگترین زیررشته مشترک دو رشته ورودی را برمیگرداند.) برنامه نویسی پویا
اگر در این سؤال فرض کنیم که زیررشته بهشکل ww است سؤال غلط میشود، به این دلیل که جواب در گزینهها نیست. به مثال زیر توجه کنید:
$\begin{array}{cccccccccc}c & a & b & c & d & c & d & c & a & b \\ 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10 \end{array}$
در گزینه 3 اگر $p=3$ باشد $LCS\left(S\left[1\dots 3\right],S\left[4\dots 10\right]\right)$ برابر با 3 میشود باتوجه به اینکه LCS بزرگترین زیررشته مشترک را میدهد که در این مثال برابر “cab” میباشد. درنهایت مقدار 6 بهعنوان جواب برگردانده میشود. درحالیکه اگر بهشکل ww فکر کنیم باید رشته “cd” انتخاب شود و جواب نهایی برابر با 4 بشود.
از اینرو میتوان گفت که منظور طراح $w{\mathit{\Sigma}}^xw$ میباشد که در اینصورت گزینه 2 صحیح است.
متوسط تابع بازگشتی زیر را درنظر بگیرید: به دست آوردن مرتبه زمانی شبه کدها
int f (int n) { if (n == 0 || n ==1) return (n + 1); else if (n == 2) return 4; return (f (n – 1) + 2 * f (n – 2) + f (n – 3)); }
برای $n \ge 3$، کدام گزینه بهترین کاندید برای $f(n)$ است؟
اگر عبارت $f\left(n-1\right)$ را تبدیل به $f\left(n-2\right)$ کنیم و $f\left(n-3\right)$ را تبدیل به $f\left(n-2\right)$ کنیم مشخص است $f(n)$ درنهایت کوچکتر میشود.
در اینجا $2\times f\left(n-2\right)$ تبدیل به $2\times f\left(n-1\right)$ شدهاند که باعث بزرگتر شدن عبارت شدند ولی $f\left(n-3\right)$ حذف شد که باعث کوچکتر شدن عبارت شده است. بدیهی است که درنهایت عبارت بزرگتر شده است.
آسان فرض کنید آرایهای به طول n داریم که به شکل حلقوی مرتب صعودی است. برای مثال آرایه زیر: مرتبسازی
40
50
60
70
80
90
10
20
30
میخواهیم الگوریتمی بنویسیم که $\left\lfloor \sqrt{n}\right\rfloor $ امین کوچکترین عنصر این آرایه را بیابیم، مرتبه زمانی این الگوریتم چیست؟
1 $O\left(n\right)$
2 $O\left(\sqrt{n}\right)$
3 $O\left({{\mathrm{log}}^2 \ n\ }\right)$
4 $O\left({\mathrm{log}\ n\ }\right)$
گزینه 4 صحیح است.
ابتدا بهدنبال کوچکترین عنصر آرایه میگردیم.
عنصر وسط آرایه را با عنصر ابتدای آرایه مقایسه میکنیم؛ اگر کوچکتر بود (و همچنین از عنصر بعدیاش بزرگتر بود) متوجه میشویم که در قسمت سمت راست آرایه باید با همین روش بهدنبال min بگردیم و اگر از عنصر اول آرایه بزرگتر بود متوجه میشویم که در سمت راست آرایه هستیم و باید بریم و در نصفه چپ بهدنبال min بگردیم. مشخص است که با هربار مقایسه داریم آرایهمان را نصف میکنیم، بنابراین مرتبه $O(log\ n)$ است.
بعد از پیدا کردن کوچکترین عنصر کافیست $\sqrt n$ ایندکس بعدی و $\sqrt n$ ایندکس قبلی را درنظر بگیریم و هرکدام کوچکتر بود بهعنوان جواب برمیگردانیم که اینکار از مرتبهی $\theta(1)$ میباشد.
درنتیجه مرتبهی زمانی برابر $O(log\ n)$ میباشد.
آسان فرض کنید $f\left(n\right)=n$ و $g\left(n\right)=n^{\left(1+{sin n\ }\right)}$، که $n$ یک عدد صحیح مثبت است. کدامیک از گزارههای زیر درست است؟ رشد توابع
باتوجه به بازهی توان $n$ در $g(n)$ نه $f\left(n\right)=\mathit{O}\left(g\left(n\right)\right)$ برقرار است و نه $f\left(n\right)=\mathit{\Omega}\left(g\left(n\right)\right)$. درنتیجه گزینه 3 صحیح است.
آسان بهترین پیچیدگی زمانی مورد نیاز برای محاسبه مجموع دو جمله $i$ ام و $j$ ام از دنباله فیبوناچی چیست؟ تقسیم و غلبه
برای محاسبهی $F_n$ کافی است ماتریس $A$ را $n$ بار به توان رساند که مرتبهی اینکار $O(n)$ میباشد. الگوریتم بهتر شده وجود دارد که مرتبه را به $O(log\ n)$ تبدیل میکند امّا این سؤال آنرا درنظر نگرفته است. محاسبهی جملهی $i$ ام، $O(i)$ و محاسبهی جملهی $O(j)\ ،\ j$ پیچیدگی زمانی دارد.
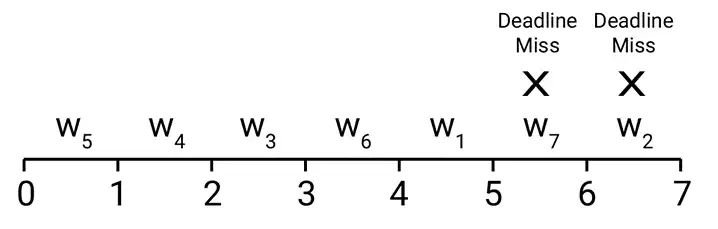
آسان هریک از کارهای زیر در یک واحد زمان قابل اجرا است. هریک از این کارها دارای یک زمان خاتمه است و درصورتیکه بعد از زمان خاتمه انجام شود مشمول یک جریمه خواهد شد. اگر این کارها را برای اجرا به کمترین جریمه زمانبندی کنیم، مقدار جریمه چقدر است؟ الگوریتمهای حریصانه
work
$w_1$
$w_2$
$w_3$
$w_4$
$w_5$
$w_6$
$w_7$
Deadline
10
2
3
3
2
5
1
Penalty
10
45
55
65
70
33
18
1 28
2 43
3 51
4 63
گزینه 4 صحیح است.
برای اینکه کمترین جریمه را داشته باشیم کارها را باید براساس جریمه مرتب کنیم.
Work
$w_5$
$w_4$
$w_3$
$w_2$
$w_6$
$w_7$
$w_1$
Penalty
$70$
$65$
$55$
$45$
$33$
$18$
$10$
سپس کارهایی که جریمهی آنها بیشتر است سعی میکنیم که انجام دهیم. کارهایی که جریمه آنها قطعی است در آخر بازه زمانی قرار میدهیم که مانع کارهای دیگر نشود.
دشوار فرض کنید که در الگوریتم مرتبسازی سریع برای انتخاب محور از میان $n$ عنصر آرایه $2\lfloor {\mathrm{log}\ n\ }\rfloor+1$ عنصر اولیه را انتخاب کنیم و با الگوریتم مرتبسازی درجی آنها را مرتب کنیم. عنصر میانه این تعداد عنصر مرتب را بهعنوان محور انتخاب میکنیم. بقیه الگوریتم همانند الگوریتم مرتبسازی عمل میکند. بهترین گزینه برای بدترین زمان اجرای این الگوریتم کدام است؟ تقسیم و غلبه
مرتبسازی درجی دارای پیچیدگی زمانی $O(n^2)$ میباشد که برای $2\left\lfloor {\mathrm{log} n\ }\right\rfloor +1$ عنصر مرتبه برابر با $O(log^2\ n)$ میباشد.
بعد از مرتبسازی درجی ما برای آرایه به تعداد $2\left\lfloor {\mathrm{log} n\ }\right\rfloor +1$ بهشکل زیر داریم.
درادامه در بدترین حالت تمام $n-(2\left\lfloor {\mathrm{log} n\ }\right\rfloor +1)$ باقیمانده از میانه بزرگتر هستند و به یک سمت اضافه میشود. دراینصورت شکل زیر را داریم:
امّا اگر در بخش 1 تعداد عناصر بیشتر از $\lfloor {\mathrm{log} n\ }\rfloor$ باشد در بخش 1 هم نیاز به مرتبسازی داریم امّا باتوجه به Pivot، عناصر بهشکل متوازن تقسیمبندی میشود که در حالت زیر بهصورت کاملاً برابر است.
$\frac{n-1}{2}$
$M$
$\frac{n-1}{2}$
که در این حالت پیچیدگی زمانی الگوریتم کمتر است و فرمول بازگشتی بهشکل زیر است:
درنتیجه هرچقدر عناصر بهصورت متوازن تقسیمبندی شوند مرتبهی الگوریتم کمتر میشود.
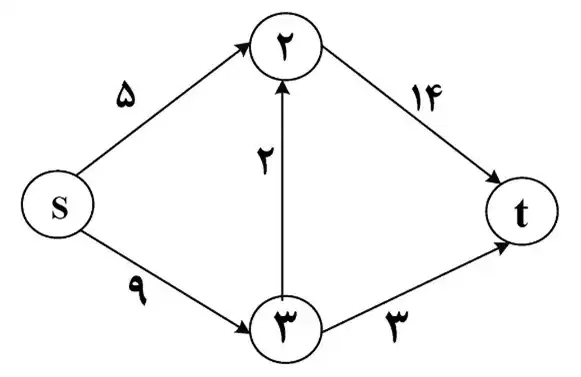
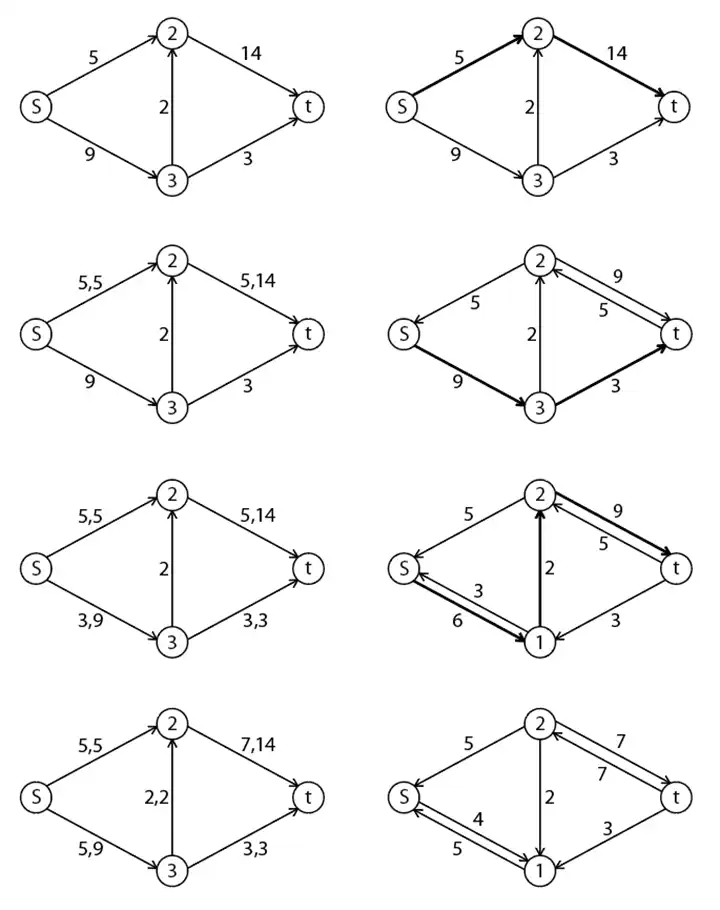
دشوار چند مورد از گزارههای زیر درست است؟ نظریه Np، شار، مجموعههای مجزا
- هر الگوریتم که ضرب دو ماتریس را محاسبه کند، میتواند در همان مرتبه وارون یک ماتریس را محاسبه کند و بالعکس. - برای محاسبه ضرب دو چندجملهای از درجه 16 تعداد فراخوانیهای لازم با استفاده از الگوریتم تقسیم و حل، وقتی که چندجملهای حداکثر از درجه 4، چندجملهای کوچک تلقی میشود برابر است با 13. - در شبکه جریان داده شده شکل زیر اگر فقط مجاز به افزایش ظرفیت یک یال باشیم، حداکثر میتوان 7 واحد به ظرفیت یک یال آن اضافه کرد تا شبکه حداکثر جریان عبوری را داشته باشیم.
1 صفر
2 1
3 2
4 3
گزینه 3 صحیح است امّا سنجش گزینه 4 را اعلام کرده است.
x: یک نوع محاسبهی معکوس ماتریس است که با استفاده از ضرب ماتریس و بدون محاسبهی مستقیم دترمینان وجود دارد.
Block Wise Inverstion: اگر بلوک بلوک به ماتریس نگاه کرد میتوان معکوس یک ماتریس بهشکل زیر نوشت:
${\left[ \begin{array}{cc}A & B \\ C & D \end{array}\right]}^{-1}=\left[ \begin{array}{cc}A^{-1}+A^{-1}B{\left(D-CA^{-1}B\right)}^{-1}CA^{-1} & -A^{-1}B{\left(D-CA^{-1}B\right)}^{-1} \\ -{\left(D-CA^{-1}B\right)}^{-1}CA^{-1} & {\left(D-CA^{-1}B\right)}^{-1} \end{array}\right]$
که A و B و C و D هریک بلوکهایی از ماتریس هستند. این نگاه به ماتریس را قبلاً در الگوریتم استراسن دیده بودیم که باعث میشد بتوانیم بهشکل بازگشتی و با الگوریتم تقسیم و غلبه ضرب ماتریسها را انجام بدهیم.
با استفاده از ترکیب فرمول بالا و سایر فرمولهای Block Wise Inversion میتوان ثابت کرد که بهدست آوردن معکوس ماتریس با استفاده از ضرب ماتریس همهزینهی پیچیدگی ضرب ماتریس است.
برای مثال اگر از الگوریتم ضرب ماتریسهای استراسن استفاده شود، مرتبهی محاسبهی معکوس ماتریس برابر با $\theta \left(n^{{{\mathrm{log}}_2 7\ }}\right)$ میباشد.
گزاره 2: چندجملهایهای $q(x)$ ،$p(x)$ را میتوان بهشکل زیر نوشت:
$P\left(x\right)=P_L+x^{\frac{n}{2}}P_R$
$q\left(x\right)=q_L+x^{\frac{n}{2}}q_R$
و میتوان ضرب چندجملهایهای $p(x)$ و $q(x)$ را بهشکل زیر تعریف کرد:
مشخص نیست منظور طراح از گزاره 3 چیست. در گزاره 3 بیان شده است که حداکثر میتوان 7 واحد به یک یال اضافه کرد که حداکثر ظرفیت را داشته باشیم که مشخصاً واژهی حداکثر اشتباه است زیرا حد بالایی برای ظرفیت یک یال وجود ندارد.
همچنین حداکثر جریان عبوری از گراف براساس ظرفیتهای آن گراف معرفی میشود که اگر ظرفیت یک یال بیشتر شود، جریان عبوری نیز بیشتر میشود.
این گزاره غلط است.
برای اهداف آموزشی حداکثر شار عبوری بهدست آورده شده است.
گزاره سوم: با استفاده از الگوریتم فورد – فالکرسون میتوان بیشینه شار عبوری را بهدست آورد.
درنهایت مسیر دیگری از s به t وجود ندارد و الگوریتم به اتمام میرسد.
گزاره اول و دوم درست است. اما گزاره سوم غلط است. کلید سنجش گزینه 4 را اعلام کرده است.
روش های دسترسی به پاسخ تشریحی ساختمان داده و طراحی الگوریتم کنکور
دو روش برای دسترسی به پاسخ تشریحی تمامی تست های درس ساختمان داده و طراحی الگوریتم وجود دارد:
دوره نکته و تست ساختمان داده و طراحی الگوریتم
علاوه بر حل تشریحی تست های درس ساختمان داده و طراحی الگوریتم در این دوره نکته و تست، شما میتوانید به تعداد زیادی تست تألیفی نیز دسترسی داشته باشید. همچنین نکاتی در این دوره بیان میشود که به درک بهتر درس کمک میکند. برای کسب اطلاعات بیشتر و تهیه دوره میتوانید به صفحه دوره نکته و تست ساختمان داده و طراحی الگوریتم مراجعه کنید.
پلتفرم آزمون و بانک تست و مجموعه سوالات کنکور ارشد کامپیوتر و آیتی
سیستم قدرتمند آزمون کنکور کامپیوتر - اولین و تنها سیستم آزمون رشته کامپیوتر
داوطلبین کنکور ارشد کامپیوتر و آیتی، با این پلتفرم نیازی به تهیه هیچ کتابی ندارید، بهتر از هر کتاب مجموعه سوالات
به دو روش میتوانید به پاسخ تشریحی تست های درس ساختمان داده و طراحی الگوریتم دسترسی داشته باشید: روش اول استفاده از دوره نکته و تست ساختمان داده و الگوریتم و روش دوم استفاده از پلتفرم آزمون است.
چگونه می توانم به پاسخ تشریحی تست های کنکور ساختمان داده و طراحی الگوریتم دسترسی داشته باشم؟
به دو روش زیر: 1- دوره نکتهوتست ساختمان داده و طراحی الگوریتم 2- استفاده از پلتفرم آزمون
آیا با تهیه منابع ذکر شده، نیازمند کتاب یا منبع دیگری هستم؟
خیر، این منابع جامعیت کافی دارند و شما نیاز به منبع دیگری ندارید.
همچنین هر گونه سوالی در مورد کلاسهای آنلاین کنکور کامپیوتر و یا تهیه فیلمها و یا رزرو مشاوره تک جلسهای تلفنی با استاد رضوی دارید میتوانید به طرق زیر از تیم پشتیبانی بپرسید:

 هر ساختمان داده یک نوع فرمت ذخیرهسازی و مدیریت دادهها در کامپیوتر است، که امکان دسترسی و اصلاح کارآمد آن دادهها را برای یکسری از الگوریتمها و کاربردها فراهم میکند، در این صفحه به بررسی و آموزش ساختمان داده و الگوریتم پرداخته شده است دارد، مطالعه آن برای کسب رتبه مطلوب ضروری است. برای تکمیل مطالعه شما نیاز به حل تست دارید. پس از حل هر تست باید پاسخ خودتان را با پاسخ مرجع مقایسه کنید. ازاینرو نیازمند پاسخ تشریحی درس ساختمان داده و الگوریتم هستید. در این مقاله به پاسخ تشریحی ساختمان داده و الگوریتم ۱۴۰۳ میپردازیم. برای دسترسی به پاسخ تشریحی ساختمان داده و الگوریتم دیگر سالها میتوانید از دوره نکته و تست ساختمان داده و طراحی الگوریتم یا پلتفرم آزمون استفاده کنید.
هر ساختمان داده یک نوع فرمت ذخیرهسازی و مدیریت دادهها در کامپیوتر است، که امکان دسترسی و اصلاح کارآمد آن دادهها را برای یکسری از الگوریتمها و کاربردها فراهم میکند، در این صفحه به بررسی و آموزش ساختمان داده و الگوریتم پرداخته شده است دارد، مطالعه آن برای کسب رتبه مطلوب ضروری است. برای تکمیل مطالعه شما نیاز به حل تست دارید. پس از حل هر تست باید پاسخ خودتان را با پاسخ مرجع مقایسه کنید. ازاینرو نیازمند پاسخ تشریحی درس ساختمان داده و الگوریتم هستید. در این مقاله به پاسخ تشریحی ساختمان داده و الگوریتم ۱۴۰۳ میپردازیم. برای دسترسی به پاسخ تشریحی ساختمان داده و الگوریتم دیگر سالها میتوانید از دوره نکته و تست ساختمان داده و طراحی الگوریتم یا پلتفرم آزمون استفاده کنید.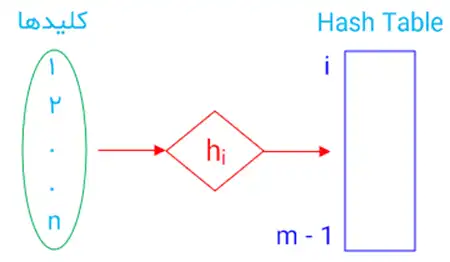
 از نگاه دانشجویان، قدرت بیان فوق العاده استاد رضوی و پوشش ۱۰۰ درصدی تمامی سرفصلها، نکات و تستها، ویدیوهای حل تست ساختمان داده و طراحی الگوریتم را به بهترین ویدیو حل تست کشور در درس ساختمان و الگوریتم تبدیل کرده است. این فیلم پرطرفدارترین و پرفروشترین فیلم حل تست ساختمان داده و الگوریتم کشور است و هر سال بیش از ۶۰۰۰ نفر این فیلم را تهیه میکنند مراجعه کنید.
از نگاه دانشجویان، قدرت بیان فوق العاده استاد رضوی و پوشش ۱۰۰ درصدی تمامی سرفصلها، نکات و تستها، ویدیوهای حل تست ساختمان داده و طراحی الگوریتم را به بهترین ویدیو حل تست کشور در درس ساختمان و الگوریتم تبدیل کرده است. این فیلم پرطرفدارترین و پرفروشترین فیلم حل تست ساختمان داده و الگوریتم کشور است و هر سال بیش از ۶۰۰۰ نفر این فیلم را تهیه میکنند مراجعه کنید.





































